From 4542a4d0611723767a37f1bd89665ef71dc75393 Mon Sep 17 00:00:00 2001
From: Cresson Remi <remi.cresson@irstea.fr>
Date: Tue, 4 Apr 2023 12:25:11 +0200
Subject: [PATCH 01/18] Release 4.0.0-alpha
---
.gitignore | 3 +
.gitlab-ci.yml | 79 ++-
.readthedocs.yaml | 12 +
Dockerfile | 66 ++-
README.md | 112 ++--
RELEASE_NOTES.txt | 15 +
app/otbPatchesSelection.cxx | 5 +-
doc/APPLICATIONS.md | 371 ------------
doc/CREATEYOUROWN.md | 37 --
doc/EXAMPLES.md | 317 ----------
doc/api_distributed.md | 143 +++++
doc/api_model_generalities.md | 57 ++
doc/api_tutorial.md | 502 ++++++++++++++++
doc/app_inference.md | 130 ++++
doc/app_overview.md | 46 ++
doc/app_sampling.md | 164 ++++++
doc/app_training.md | 114 ++++
doc/{HOWTOBUILD.md => build_from_sources.md} | 93 ++-
doc/deprecated.md | 38 ++
doc/doc_requirements.txt | 8 +
doc/docker_build.md | 211 +++++++
doc/docker_troubleshooting.md | 201 +++++++
doc/{DOCKERUSE.md => docker_use.md} | 257 +++-----
doc/gen_ref_pages.py | 33 ++
doc/images/modelbase.png | 3 +
doc/images/modelbase_1.png | 3 +
doc/images/modelbase_2.png | 3 +
doc/images/modelbase_3.png | 3 +
doc/images/modelbase_4.png | 3 +
doc/images/pipeline.png | 3 +
doc/index.md | 112 ++++
mkdocs.yml | 84 +++
otbtf/__init__.py | 17 +-
otbtf/dataset.py | 556 ++++++++++++------
otbtf/examples/__init__.py | 4 +
otbtf/examples/tensorflow_v1x/__init__.py | 456 ++++++++++++++
.../create_savedmodel_ienco-m3_patchbased.py | 252 +++++---
otbtf/examples/tensorflow_v2x/__init__.py | 0
.../tensorflow_v2x/deterministic/__init__.py | 95 +++
.../{ => deterministic}/l2_norm.py | 14 +-
.../scalar_prod.py} | 19 +-
otbtf/examples/tensorflow_v2x/fcnn/README.md | 64 --
.../examples/tensorflow_v2x/fcnn/__init__.py | 4 +
.../tensorflow_v2x/fcnn/create_tfrecords.py | 48 +-
.../tensorflow_v2x/fcnn/fcnn_model.py | 174 ++++--
otbtf/examples/tensorflow_v2x/fcnn/helper.py | 37 +-
.../fcnn/train_from_patchesimages.py | 124 ++--
.../fcnn/train_from_tfrecords.py | 37 +-
otbtf/model.py | 244 ++++++--
otbtf/tfrecords.py | 260 +++++---
otbtf/utils.py | 40 +-
setup.py | 11 +-
test/api_unittest.py | 109 ++--
test/imports_test.py | 23 +
tools/docker/README.md | 159 -----
tools/docker/build-deps-cli.txt | 1 -
tools/docker/build-env-tf.sh | 6 +-
tools/docker/build-flags-otb.txt | 13 -
tools/docker/multibuild.sh | 104 ++--
59 files changed, 4180 insertions(+), 1919 deletions(-)
create mode 100644 .readthedocs.yaml
delete mode 100644 doc/APPLICATIONS.md
delete mode 100644 doc/CREATEYOUROWN.md
delete mode 100644 doc/EXAMPLES.md
create mode 100644 doc/api_distributed.md
create mode 100644 doc/api_model_generalities.md
create mode 100644 doc/api_tutorial.md
create mode 100644 doc/app_inference.md
create mode 100644 doc/app_overview.md
create mode 100644 doc/app_sampling.md
create mode 100644 doc/app_training.md
rename doc/{HOWTOBUILD.md => build_from_sources.md} (68%)
create mode 100644 doc/deprecated.md
create mode 100644 doc/doc_requirements.txt
create mode 100644 doc/docker_build.md
create mode 100644 doc/docker_troubleshooting.md
rename doc/{DOCKERUSE.md => docker_use.md} (63%)
create mode 100644 doc/gen_ref_pages.py
create mode 100644 doc/images/modelbase.png
create mode 100644 doc/images/modelbase_1.png
create mode 100644 doc/images/modelbase_2.png
create mode 100644 doc/images/modelbase_3.png
create mode 100644 doc/images/modelbase_4.png
create mode 100644 doc/images/pipeline.png
create mode 100644 doc/index.md
create mode 100644 mkdocs.yml
create mode 100644 otbtf/examples/__init__.py
create mode 100644 otbtf/examples/tensorflow_v1x/__init__.py
create mode 100644 otbtf/examples/tensorflow_v2x/__init__.py
create mode 100644 otbtf/examples/tensorflow_v2x/deterministic/__init__.py
rename otbtf/examples/tensorflow_v2x/{ => deterministic}/l2_norm.py (71%)
rename otbtf/examples/tensorflow_v2x/{scalar_product.py => deterministic/scalar_prod.py} (65%)
delete mode 100644 otbtf/examples/tensorflow_v2x/fcnn/README.md
create mode 100644 otbtf/examples/tensorflow_v2x/fcnn/__init__.py
create mode 100644 test/imports_test.py
delete mode 100644 tools/docker/README.md
diff --git a/.gitignore b/.gitignore
index 1ef65aa1..9ec7724f 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,3 +1,6 @@
# Compiled python source #
*.pyc
.idea
+build
+site
+otbtf.egg-info
diff --git a/.gitlab-ci.yml b/.gitlab-ci.yml
index a03ca2ca..596e7ed1 100644
--- a/.gitlab-ci.yml
+++ b/.gitlab-ci.yml
@@ -1,7 +1,7 @@
image: $CI_REGISTRY_IMAGE:$CI_COMMIT_REF_NAME
variables:
- OTBTF_VERSION: 3.4.0
+ OTBTF_VERSION: 4.0.0
OTB_BUILD: /src/otb/build/OTB/build # Local OTB build directory
OTBTF_SRC: /src/otbtf # Local OTBTF source directory
OTB_TEST_DIR: $OTB_BUILD/Testing/Temporary # OTB testing directory
@@ -18,7 +18,9 @@ variables:
CI_REGISTRY_PUBIMG: $CI_REGISTRY_IMAGE:$OTBTF_VERSION
DOCKERHUB_BASE: mdl4eo/otbtf
DOCKERHUB_IMAGE_BASE: ${DOCKERHUB_BASE}:${OTBTF_VERSION}
-
+ CPU_BASE_IMG: ubuntu:22.04
+ GPU_BASE_IMG: nvidia/cuda:12.1.0-devel-ubuntu22.04
+
workflow:
rules:
- if: $CI_MERGE_REQUEST_ID || $CI_COMMIT_REF_NAME =~ /master/ # Execute jobs in merge request context, or commit in master branch
@@ -26,6 +28,7 @@ workflow:
stages:
- Build
- Static Analysis
+ - Documentation
- Test
- Applications Test
- Update dev image
@@ -51,40 +54,39 @@ docker image:
- >
docker build
--target otbtf-base
- --network="host"
--cache-from $CACHE_IMAGE_BASE
--tag $CACHE_IMAGE_BASE
- --build-arg BASE_IMG="ubuntu:20.04"
+ --build-arg BASE_IMG=$CPU_BASE_IMG
--build-arg BUILDKIT_INLINE_CACHE=1
"."
- docker push $CACHE_IMAGE_BASE
- >
docker build
--target builder
- --network="host"
--cache-from $CACHE_IMAGE_BASE
--cache-from $CACHE_IMAGE_BUILDER
--tag $CACHE_IMAGE_BUILDER
- --build-arg OTBTESTS="true"
--build-arg KEEP_SRC_OTB="true"
--build-arg BZL_CONFIGS=""
- --build-arg BASE_IMG="ubuntu:20.04"
+ --build-arg BASE_IMG=$CPU_BASE_IMG
--build-arg BUILDKIT_INLINE_CACHE=1
+ --build-arg BZL_OPTIONS="--verbose_failures --remote_cache=$BAZELCACHE"
+ --build-arg OTBTESTS="true"
"."
- docker push $CACHE_IMAGE_BUILDER
- >
docker build
- --network="host"
--cache-from $CACHE_IMAGE_BASE
--cache-from $CACHE_IMAGE_BUILDER
--cache-from $BRANCH_IMAGE
--cache-from $DEV_IMAGE
--tag $BRANCH_IMAGE
- --build-arg OTBTESTS="true"
--build-arg KEEP_SRC_OTB="true"
--build-arg BZL_CONFIGS=""
- --build-arg BASE_IMG="ubuntu:20.04"
+ --build-arg BASE_IMG=$CPU_BASE_IMG
--build-arg BUILDKIT_INLINE_CACHE=1
+ --build-arg BZL_OPTIONS="--verbose_failures --remote_cache=$BAZELCACHE"
+ --build-arg OTBTESTS="true"
"."
- docker push $BRANCH_IMAGE
@@ -95,26 +97,54 @@ docker image:
flake8:
extends: .static_analysis_base
script:
- - sudo apt update && sudo apt install flake8 -y
- - python -m flake8 --max-line-length=120 --per-file-ignores="__init__.py:F401" $OTBTF_SRC/otbtf
+ - sudo pip install flake8
+ - flake8 $OTBTF_SRC/otbtf --exclude=tensorflow_v1x
pylint:
extends: .static_analysis_base
script:
- - sudo apt update && sudo apt install pylint -y
- - pylint --logging-format-style=old --disable=too-many-nested-blocks,too-many-locals,too-many-statements,too-few-public-methods,too-many-instance-attributes,too-many-arguments --ignored-modules=tensorflow --max-line-length=120 --logging-format-style=new $OTBTF_SRC/otbtf
+ - sudo pip install pylint
+ - pylint $OTBTF_SRC/otbtf --ignore=tensorflow_v1x
codespell:
extends: .static_analysis_base
script:
- - sudo pip install codespell && codespell
-
+ - sudo pip install codespell
+ - codespell otbtf
+ - codespell doc
+
cppcheck:
extends: .static_analysis_base
script:
- sudo apt update && sudo apt install cppcheck -y
- cd $OTBTF_SRC/ && cppcheck --enable=all --error-exitcode=1 -I include/ --suppress=missingInclude --suppress=unusedFunction .
+.doc_base:
+ stage: Documentation
+ before_script:
+ - pip install -r doc/doc_requirements.txt
+ artifacts:
+ paths:
+ - public
+ - public_test
+
+pages_test:
+ extends: .doc_base
+ except:
+ - master
+ script:
+ - mkdocs build --site-dir public_test
+
+pages:
+ extends: .doc_base
+ only:
+ - master
+ script:
+ - mkdocs build --site-dir public
+ artifacts:
+ paths:
+ - public
+
.tests_base:
artifacts:
paths:
@@ -172,6 +202,11 @@ geos_enabled:
script:
- python -m pytest --junitxml=$ARTIFACT_TEST_DIR/report_geos_enabled.xml $OTBTF_SRC/test/geos_test.py
+imports:
+ extends: .applications_test_base
+ script:
+ - python -m pytest --junitxml=$ARTIFACT_TEST_DIR/report_imports.xml $OTBTF_SRC/test/imports_test.py
+
deploy_cpu-dev-testing:
stage: Update dev image
extends: .docker_build_base
@@ -198,10 +233,10 @@ deploy_cpu:
DOCKERHUB_LATEST: $DOCKERHUB_BASE:latest
script:
# cpu
- - docker build --network='host' --tag $IMAGE_CPU --build-arg BASE_IMG=ubuntu:20.04 --build-arg BZL_CONFIGS="" .
+ - docker build --build-arg BZL_OPTIONS="--remote_cache=$BAZELCACHE" --tag $IMAGE_CPU --build-arg BASE_IMG=$CPU_BASE_IMG --build-arg BZL_CONFIGS="" .
- docker push $IMAGE_CPU
# cpu-dev
- - docker build --network='host' --tag $IMAGE_CPUDEV --build-arg BASE_IMG=ubuntu:20.04 --build-arg BZL_CONFIGS="" --build-arg KEEP_SRC_OTB=true .
+ - docker build --build-arg BZL_OPTIONS="--remote_cache=$BAZELCACHE" --tag $IMAGE_CPUDEV --build-arg BASE_IMG=$CPU_BASE_IMG --build-arg BZL_CONFIGS="" --build-arg KEEP_SRC_OTB=true .
- docker push $IMAGE_CPUDEV
# push images on dockerhub
- echo -n $DOCKERHUB_TOKEN | docker login -u mdl4eo --password-stdin
@@ -224,16 +259,16 @@ deploy_gpu:
DOCKERHUB_GPUDEV: $DOCKERHUB_IMAGE_BASE-gpu-dev
script:
# gpu-opt
- - docker build --network='host' --tag $IMAGE_GPUOPT --build-arg BASE_IMG=nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04 .
+ - docker build --build-arg BZL_OPTIONS="--remote_cache=$BAZELCACHE" --tag $IMAGE_GPUOPT --build-arg BASE_IMG=$GPU_BASE_IMG .
- docker push $IMAGE_GPUOPT
# gpu-opt-dev
- - docker build --network='host' --tag $IMAGE_GPUOPTDEV --build-arg BASE_IMG=nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04 --build-arg KEEP_SRC_OTB=true .
+ - docker build --build-arg BZL_OPTIONS="--remote_cache=$BAZELCACHE" --tag $IMAGE_GPUOPTDEV --build-arg BASE_IMG=$GPU_BASE_IMG --build-arg KEEP_SRC_OTB=true .
- docker push $IMAGE_GPUOPTDEV
# gpu-basic
- - docker build --network='host' --tag $IMAGE_GPU --build-arg BASE_IMG=nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04 --build-arg BZL_CONFIGS="" .
+ - docker build --build-arg BZL_OPTIONS="--remote_cache=$BAZELCACHE" --tag $IMAGE_GPU --build-arg BASE_IMG=$GPU_BASE_IMG --build-arg BZL_CONFIGS="" .
- docker push $IMAGE_GPU
# gpu-basic-dev
- - docker build --network='host' --tag $IMAGE_GPUDEV --build-arg BZL_CONFIGS="" --build-arg BASE_IMG=nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04 --build-arg KEEP_SRC_OTB=true .
+ - docker build --build-arg BZL_OPTIONS="--remote_cache=$BAZELCACHE" --tag $IMAGE_GPUDEV --build-arg BZL_CONFIGS="" --build-arg BASE_IMG=$GPU_BASE_IMG --build-arg KEEP_SRC_OTB=true .
- docker push $IMAGE_GPUDEV
# push gpu-basic* images on dockerhub
- echo -n $DOCKERHUB_TOKEN | docker login -u mdl4eo --password-stdin
diff --git a/.readthedocs.yaml b/.readthedocs.yaml
new file mode 100644
index 00000000..719167fe
--- /dev/null
+++ b/.readthedocs.yaml
@@ -0,0 +1,12 @@
+version: 2
+build:
+ os: ubuntu-22.04
+ tools:
+ python: "3.10"
+
+mkdocs:
+ configuration: mkdocs.yml
+
+python:
+ install:
+ - requirements: doc/doc_requirements.txt
\ No newline at end of file
diff --git a/Dockerfile b/Dockerfile
index ddac9997..f8b82f79 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -28,7 +28,7 @@ RUN pip install --no-cache-dir pip --upgrade
# NumPy version is conflicting with system's gdal dep and may require venv
ARG NUMPY_SPEC="==1.22.*"
ARG PROTO_SPEC="==3.20.*"
-RUN pip install --no-cache-dir -U wheel mock six future tqdm deprecated "numpy$NUMPY_SPEC" "protobuf$PROTO_SPEC" \
+RUN pip install --no-cache-dir -U wheel mock six future tqdm deprecated "numpy$NUMPY_SPEC" "protobuf$PROTO_SPEC" packaging requests \
&& pip install --no-cache-dir --no-deps keras_applications keras_preprocessing
# ----------------------------------------------------------------------------
@@ -37,29 +37,36 @@ FROM otbtf-base AS builder
# A smaller value may be required to avoid OOM errors when building OTB GUI
ARG CPU_RATIO=1
-RUN mkdir -p /src/tf /opt/otbtf/bin /opt/otbtf/include /opt/otbtf/lib
+RUN mkdir -p /src/tf /opt/otbtf/bin /opt/otbtf/include /opt/otbtf/lib/python3
WORKDIR /src/tf
RUN git config --global advice.detachedHead false
### TF
-ARG TF=v2.8.0
+
+ARG TF=v2.12.0
+
# Install bazelisk (will read .bazelversion and download the right bazel binary - latest by default)
RUN wget -qO /opt/otbtf/bin/bazelisk https://github.com/bazelbuild/bazelisk/releases/latest/download/bazelisk-linux-amd64 \
&& chmod +x /opt/otbtf/bin/bazelisk \
&& ln -s /opt/otbtf/bin/bazelisk /opt/otbtf/bin/bazel
ARG BZL_TARGETS="//tensorflow:libtensorflow_cc.so //tensorflow/tools/pip_package:build_pip_package"
-# "--config=opt" will enable 'march=native' (otherwise read comments about CPU compatibility and edit CC_OPT_FLAGS in build-env-tf.sh)
+
+# "--config=opt" will enable 'march=native'
+# (otherwise read comments about CPU compatibility and edit CC_OPT_FLAGS in
+# build-env-tf.sh)
ARG BZL_CONFIGS="--config=nogcp --config=noaws --config=nohdfs --config=opt"
-# "--compilation_mode opt" is already enabled by default (see tf repo .bazelrc and configure.py)
+
+# "--compilation_mode opt" is already enabled by default (see tf repo .bazelrc
+# and configure.py)
ARG BZL_OPTIONS="--verbose_failures --remote_cache=http://localhost:9090"
# Build
ARG ZIP_TF_BIN=false
COPY tools/docker/build-env-tf.sh ./
-RUN git clone --single-branch -b $TF https://github.com/tensorflow/tensorflow.git \
- && cd tensorflow \
+RUN git clone --single-branch -b $TF https://github.com/tensorflow/tensorflow.git
+RUN cd tensorflow \
&& export PATH=$PATH:/opt/otbtf/bin \
&& export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/otbtf/lib \
&& bash -c '\
@@ -67,14 +74,15 @@ RUN git clone --single-branch -b $TF https://github.com/tensorflow/tensorflow.gi
&& ./configure \
&& export TMP=/tmp/bazel \
&& BZL_CMD="build $BZL_TARGETS $BZL_CONFIGS $BZL_OPTIONS" \
- && bazel $BZL_CMD --jobs="HOST_CPUS*$CPU_RATIO" ' \
-# Installation - split here if you want to check files ^
-#RUN cd tensorflow \
+ && bazel $BZL_CMD --jobs="HOST_CPUS*$CPU_RATIO" '
+
+# Installation
+RUN cd tensorflow \
&& ./bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg \
&& pip3 install --no-cache-dir --prefix=/opt/otbtf /tmp/tensorflow_pkg/tensorflow*.whl \
- && ln -s /opt/otbtf/lib/python3.* /opt/otbtf/lib/python3 \
- && cp -P bazel-bin/tensorflow/libtensorflow_cc.so* /opt/otbtf/lib/ \
- && ln -s $(find /opt/otbtf -type d -wholename "*/site-packages/tensorflow/include") /opt/otbtf/include/tf \
+ && ln -s /opt/otbtf/local/lib/python3.*/* /opt/otbtf/lib/python3 \
+ && ln -s /opt/otbtf/local/bin/* /opt/otbtf/bin \
+ && ln -s $(find /opt/otbtf -type d -wholename "*/dist-packages/tensorflow/include") /opt/otbtf/include/tf \
# The only missing header in the wheel
&& cp tensorflow/cc/saved_model/tag_constants.h /opt/otbtf/include/tf/tensorflow/cc/saved_model/ \
&& cp tensorflow/cc/saved_model/signature_constants.h /opt/otbtf/include/tf/tensorflow/cc/saved_model/ \
@@ -86,6 +94,7 @@ RUN git clone --single-branch -b $TF https://github.com/tensorflow/tensorflow.gi
&& rm -rf bazel-* /src/tf /root/.cache/ /tmp/*
### OTB
+
ARG GUI=false
ARG OTB=5086d7601d80f2427f4d4d7f2398ec46e7efa300
ARG OTBTESTS=false
@@ -99,7 +108,20 @@ RUN apt-get update -y \
&& apt-get install --reinstall ca-certificates -y \
&& update-ca-certificates \
&& git clone https://gitlab.orfeo-toolbox.org/orfeotoolbox/otb.git \
- && cd otb && git checkout $OTB && cd .. \
+ && cd otb && git checkout $OTB \
+# <---------------------------------------- Begin dirty hack
+# This is a dirty hack for release 4.0.0alpha
+# We have to wait that OTB moves from C++14 to C++17
+# See https://gitlab.orfeo-toolbox.org/orfeotoolbox/otb/-/issues/2338
+ && sed -i 's/CMAKE_CXX_STANDARD 14/CMAKE_CXX_STANDARD 17/g' CMakeLists.txt \
+ && echo "" > Modules/Filtering/ImageManipulation/test/CMakeLists.txt \
+ && echo "" > Modules/Segmentation/Conversion/test/CMakeLists.txt \
+ && echo "" > Modules/Radiometry/Indices/test/CMakeLists.txt \
+ && echo "" > Modules/Learning/DempsterShafer/test/CMakeLists.txt \
+ && echo "" > Modules/Feature/Edge/test/CMakeLists.txt \
+ && echo "" > Modules/Core/ImageBase/test/CMakeLists.txt \
+# <---------------------------------------- End dirty hack
+ && cd .. \
&& mkdir -p build \
&& cd build \
&& if $OTBTESTS; then \
@@ -129,8 +151,8 @@ RUN cd /src/otb/build/OTB/build \
-DOTB_USE_TENSORFLOW=ON -DModule_OTBTensorflow=ON \
-Dtensorflow_include_dir=/opt/otbtf/include/tf \
# Forcing TF>=2, this Dockerfile hasn't been tested with v1 + missing link for libtensorflow_framework.so in the wheel
- -DTENSORFLOW_CC_LIB=/opt/otbtf/lib/libtensorflow_cc.so.2 \
- -DTENSORFLOW_FRAMEWORK_LIB=/opt/otbtf/lib/python3/site-packages/tensorflow/libtensorflow_framework.so.2 \
+ -DTENSORFLOW_CC_LIB=/opt/otbtf/local/lib/python3.10/dist-packages/tensorflow/libtensorflow_cc.so.2 \
+ -DTENSORFLOW_FRAMEWORK_LIB=/opt/otbtf/local/lib/python3.10/dist-packages/tensorflow/libtensorflow_framework.so.2 \
&& make install -j $(python -c "import os; print(round( os.cpu_count() * $CPU_RATIO ))") \
# Cleaning
&& ( $GUI || rm -rf /opt/otbtf/bin/otbgui* ) \
@@ -152,10 +174,12 @@ COPY --from=builder /src /src
# System-wide ENV
ENV PATH="/opt/otbtf/bin:$PATH"
ENV LD_LIBRARY_PATH="/opt/otbtf/lib:$LD_LIBRARY_PATH"
-ENV PYTHONPATH="/opt/otbtf/lib/python3/site-packages:/opt/otbtf/lib/python3/dist-packages:/opt/otbtf/lib/otb/python:/src/otbtf"
+ENV PYTHONPATH="/opt/otbtf/lib/python3/dist-packages:/opt/otbtf/lib/otb/python"
ENV OTB_APPLICATION_PATH="/opt/otbtf/lib/otb/applications"
+RUN pip install -e /src/otbtf
-# Default user, directory and command (bash is the entrypoint when using 'docker create')
+# Default user, directory and command (bash is the entrypoint when using
+# 'docker create')
RUN useradd -s /bin/bash -m otbuser
WORKDIR /home/otbuser
@@ -165,14 +189,18 @@ RUN if $SUDO; then \
usermod -a -G sudo otbuser \
&& echo "otbuser ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers; fi
-# Set /src/otbtf ownership to otbuser (but you still need 'sudo -i' in order to rebuild TF or OTB)
+# Set /src/otbtf ownership to otbuser (but you still need 'sudo -i' in order
+# to rebuild TF or OTB)
RUN chown -R otbuser:otbuser /src/otbtf
# This won't prevent ownership problems with volumes if you're not UID 1000
USER otbuser
+
# User-only ENV
+ENV PATH="/home/otbuser/.local/bin:$PATH"
# Test python imports
RUN python -c "import tensorflow"
RUN python -c "import otbtf, tricks"
RUN python -c "import otbApplication as otb; otb.Registry.CreateApplication('ImageClassifierFromDeepFeatures')"
+RUN python -c "from osgeo import gdal"
\ No newline at end of file
diff --git a/README.md b/README.md
index 5b8bd66a..b61be7b9 100644
--- a/README.md
+++ b/README.md
@@ -1,81 +1,43 @@
-
-
# OTBTF: Orfeo ToolBox meets TensorFlow
-[](https://opensource.org/licenses/Apache-2.0)
-[](https://gitlab.irstea.fr/remi.cresson/otbtf/-/commits/develop)
-
-This remote module of the [Orfeo ToolBox](https://www.orfeo-toolbox.org) provides a generic, multi purpose deep learning framework, targeting remote sensing images processing.
-It contains a set of new process objects that internally invoke [Tensorflow](https://www.tensorflow.org/), and a bunch of user-oriented applications to perform deep learning with real-world remote sensing images.
-Applications can be used to build OTB pipelines from Python or C++ APIs.
-
-## Features
-
-### OTB Applications
-
-- Sample patches in remote sensing images with `PatchesExtraction`,
-- Model training, supporting save/restore/import operations (a model can be trained from scratch or fine-tuned) with `TensorflowModelTrain`,
-- Inference with support of OTB streaming mechanism with `TensorflowModelServe`. The streaming mechanism means (1) no limitation with images sizes, (2) inference can be used as a "lego" in any OTB pipeline (using C++ or Python APIs) and preserving streaming, (3) MPI support available (use multiple processing unit to generate one single output image)
-
-### Python
-
-The `otbtf` module targets python developers that want to train their own model from python with TensorFlow or Keras.
-It provides various classes for datasets and iterators to handle the _patches images_ generated from the `PatchesExtraction` OTB application.
-For instance, the `otbtf.DatasetFromPatchesImages` can be instantiated from a set of _patches images_
-and delivering samples as `tf.dataset` that can be used in your favorite TensorFlow pipelines, or convert your patches into TFRecords.
-The `otbtf.TFRecords` enables you train networks from TFRecords files, which is quite suited for
-distributed training. Read more in the [tutorial for keras](otbtf/examples/tensorflow_v2x/fcnn/README.md).
-
-`tricks.py` is here for backward compatibility with codes based on OTBTF 1.x and 2.x.
-
-## Examples
-
-Below are some screen captures of deep learning applications performed at large scale with OTBTF.
- - Landcover mapping (Spot-7 images --> Building map using semantic segmentation)
-
-
-
- - Super resolution (Sentinel-2 images upsampled with the [SR4RS software](https://github.com/remicres/sr4rs), which is based on OTBTF)
-
-
-
- - Sentinel-2 reconstruction with Sentinel-1 VV/VH with the [Decloud software](https://github.com/CNES/decloud), which is based on OTBTF
-
-
- -
- - Image to image translation (Spot-7 image --> Wikimedia Map using CGAN. So unnecessary but fun!)
-
-
-
-## How to install
-
-For now you have two options: either use the existing **docker image**, or build everything **from source**.
-
-### Docker
-
-Use the latest CPU or GPU-enabled image from dockerhub:
-```
-docker run mdl4eo/otbtf:3.4.0-cpu otbcli_PatchesExtraction -help
+<p align="center">
+<img src="https://gitlab.irstea.fr/remi.cresson/otbtf/-/raw/develop/doc/images/logo.png" width="160px">
+<br>
+<a href="https://gitlab.irstea.fr/remi.cresson/otbtf/-/releases">
+<img src="https://gitlab.irstea.fr/remi.cresson/otbtf/-/badges/release.svg">
+</a>
+<a href="https://gitlab.irstea.fr/remi.cresson/otbtf/-/commits/master">
+<img src="https://gitlab.irstea.fr/remi.cresson/otbtf/badges/master/pipeline.svg">
+</a>
+<img src='https://readthedocs.org/projects/otbtf/badge/?version=latest' alt='Documentation Status' />
+<a href="LICENSE">
+<img src="https://img.shields.io/badge/License-Apache%202.0-blue.svg">
+</a>
+</p>
+
+OTBTF is a remote module of the [Orfeo ToolBox](https://www.orfeo-toolbox.org).
+It provides a generic, multi-purpose deep learning framework, targeting remote
+sensing images processing. It contains a set of new process objects for OTB
+that internally invoke [Tensorflow](https://www.tensorflow.org/), and new OTB
+applications to perform deep learning with real-world remote sensing images.
+Applications can be used to build OTB pipelines from Python or C++ APIs. OTBTF
+also includes a python API to build quickly Keras compliant models suited for
+remote sensing imagery, easy to train in distributed environments.
+
+## Documentation
+
+The documentation is available on [otbtf.readthedocs.io](otbtf.readthedocs.io).
+
+## Use
+
+You can use our latest GPU enabled docker images.
+
+```bash
+docker run --runtime=nvidia -ti mdl4eo/otbtf:4.0.0-gpu otbcli_PatchesExtraction
+docker run --runtime=nvidia -ti mdl4eo/otbtf:4.0.0-gpu python -c "import otbtf"
```
-Read more in the [docker use documentation](doc/DOCKERUSE.md).
-
-### Build from sources
-
-Read more in the [build from sources documentation](doc/HOWTOBUILD.md).
-
-## How to use
-
-- Reading [the applications documentation](doc/APPLICATIONS.md) will help, of course 😉
-- A small [tutorial](https://mdl4eo.irstea.fr/2019/01/04/an-introduction-to-deep-learning-on-remote-sensing-images-tutorial/) on MDL4EO's blog
-- in the `python` folder are provided some [ready-to-use deep networks, with documentation and scientific references](doc/EXAMPLES.md).
-- A [book](https://doi.org/10.1201/9781003020851): *Cresson, R. (2020). Deep Learning for Remote Sensing Images with Open Source Software. CRC Press.* Use QGIS, OTB and Tensorflow to perform various kind of deep learning sorcery on remote sensing images (patch-based classification for landcover mapping, semantic segmentation of buildings, optical image restoration from joint SAR/Optical time series).
-- Check [our repository](https://github.com/remicres/otbtf_tutorials_resources) containing stuff (data and models) to begin with with!
-- Finally, take a look in the `test` folder. You will find plenty of command lines for applications tests!
-
-## Contribute
-
-Every one can **contribute** to OTBTF. Just open a PR :)
+You can also build OTBTF from sources (see the documentation)
## Cite
@@ -90,4 +52,4 @@ Every one can **contribute** to OTBTF. Just open a PR :)
year={2018},
publisher={IEEE}
}
-```
+```
\ No newline at end of file
diff --git a/RELEASE_NOTES.txt b/RELEASE_NOTES.txt
index 490538c2..7cf3b01d 100644
--- a/RELEASE_NOTES.txt
+++ b/RELEASE_NOTES.txt
@@ -1,3 +1,18 @@
+Version 4.0.0alpha (4 apr 2023)
+----------------------------------------------------------------
+* Big improvement of the documentation:
+ - Re-structure the entire doc, remove deprecated stuff, etc.
+ - Add a nice mkdocs template
+ - Docs are now hosted at otbtf.readthedocs.io
+ - Add a new section on the python API (end-to-end tutorial)
+ - A lot of new sections: distributed training, etc...
+* Refactoring all the python classes to enforce pep8
+* Ubuntu version: 22.04
+* Cuda version: 12.1.0
+* Tensorflow version: 2.12.0
+* Fixed Tensorflow error "Cannot register 2 metrics with the same name" + new test
+* Faster CI build thanks to bazel remote cache
+
Version 3.4.0 (22 mar 2023)
----------------------------------------------------------------
* Update OTB version to 5086d7601d80f2427f4d4d7f2398ec46e7efa300 (version 8.1.1 with bugfixes on in-memory connection with python bindings)
diff --git a/app/otbPatchesSelection.cxx b/app/otbPatchesSelection.cxx
index 3437849b..a146bb6a 100644
--- a/app/otbPatchesSelection.cxx
+++ b/app/otbPatchesSelection.cxx
@@ -110,9 +110,10 @@ public:
// Documentation
SetName("PatchesSelection");
SetDescription("This application generate points sampled at regular interval over "
- "the input image region. The grid size and spacing can be configured.");
+ "the input image region. The selection strategy, grid size and step, "
+ " can be configured.");
SetDocLongDescription("This application produces a vector data containing "
- "a set of points centered on the patches lying in the valid regions of the input image. ");
+ "a set of points centered on the selected patches.");
SetDocAuthors("Remi Cresson");
diff --git a/doc/APPLICATIONS.md b/doc/APPLICATIONS.md
deleted file mode 100644
index 2ca5fd1f..00000000
--- a/doc/APPLICATIONS.md
+++ /dev/null
@@ -1,371 +0,0 @@
-# Description of applications
-
-This section introduces the new OTB applications provided in OTBTF.
-
-## Patches extraction
-
-The `PatchesExtraction` application performs the extraction of patches in images from a vector data containing points.
-Each point locates the **center** of the **central pixel** of the patch.
-For patches with even size of *N*, the **central pixel** corresponds to the pixel index *N/2+1* (index starting at 0).
-We denote one _input source_, either an input image, or a stack of input images that will be concatenated (they must have the same size).
-The user can set the `OTB_TF_NSOURCES` environment variable to select the number of _input sources_ that he wants.
-For example, for sampling a Time Series (TS) together with a single Very High Resolution image (VHR), two sources are required:
- - 1 input images list for time series,
- - 1 input image for the VHR.
-
-The sampled patches are extracted at each positions designed by the input vector data, only if a patch lies fully in all _input sources_ extents.
-For each _input source_, patches sizes must be provided.
-For each _input source_, the application export all sampled patches as a single multiband raster, stacked in rows.
-For instance, for *n* samples of size *16 x 16* from a *4* channels _input source_, the output image will be a raster of size *16 x 16n* with *4* channels.
-An optional output is an image of size *1 x n* containing the value of one specific field of the input vector data.
-Typically, the *class* field can be used to generate a dataset suitable for a model that performs pixel wise classification.
-
-
-
-```
-This application extracts patches in multiple input images. Change the OTB_TF_NSOURCES environment variable to set the number of sources.
-Parameters:
- -source1 <group> Parameters for source 1
-MISSING -source1.il <string list> Input image(s) 1 (mandatory)
-MISSING -source1.out <string> [pixel] Output patches for image 1 [pixel=uint8/uint16/int16/uint32/int32/float/double/cint16/cint32/cfloat/cdouble] (default value is float) (mandatory)
-MISSING -source1.patchsizex <int32> X patch size for image 1 (mandatory)
-MISSING -source1.patchsizey <int32> Y patch size for image 1 (mandatory)
- -source1.nodata <float> No-data value for image 1
-MISSING -vec <string> Positions of the samples (must be in the same projection as input image) (mandatory)
- -outlabels <string> [pixel] output labels [pixel=uint8/uint16/int16/uint32/int32/float/double/cint16/cint32/cfloat/cdouble] (default value is uint8) (optional, off by default)
-MISSING -field <string> field of class in the vector data (mandatory)
- -progress <boolean> Report progress
- -help <string list> Display long help (empty list), or help for given parameters keys
-
-Use -help param1 [... paramN] to see detailed documentation of those parameters.
-
-Examples:
-otbcli_PatchesExtraction -vec points.sqlite -source1.il $s2_list -source1.patchsizex 16 -source1.patchsizey 16 -field class -source1.out outpatches_16x16.tif -outlabels outlabels.tif
-```
-
-## Build your Tensorflow model <a name="buildmodel"></a>
-
-You can build models using the TensorFlow Python API as shown in the `./python/` directory.
-Models must be exported in **SavedModel** format.
-When using a model in OTBTF, the important thing is to know the following parameters related to the _placeholders_ (the inputs of your model) and _output tensors_ (the outputs of your model).
- - For each _input placeholder_:
- - Name
- - **Receptive field**
- - For each _output tensor_:
- - Name
- - **Expression field**
- - **Scale factor**
-
-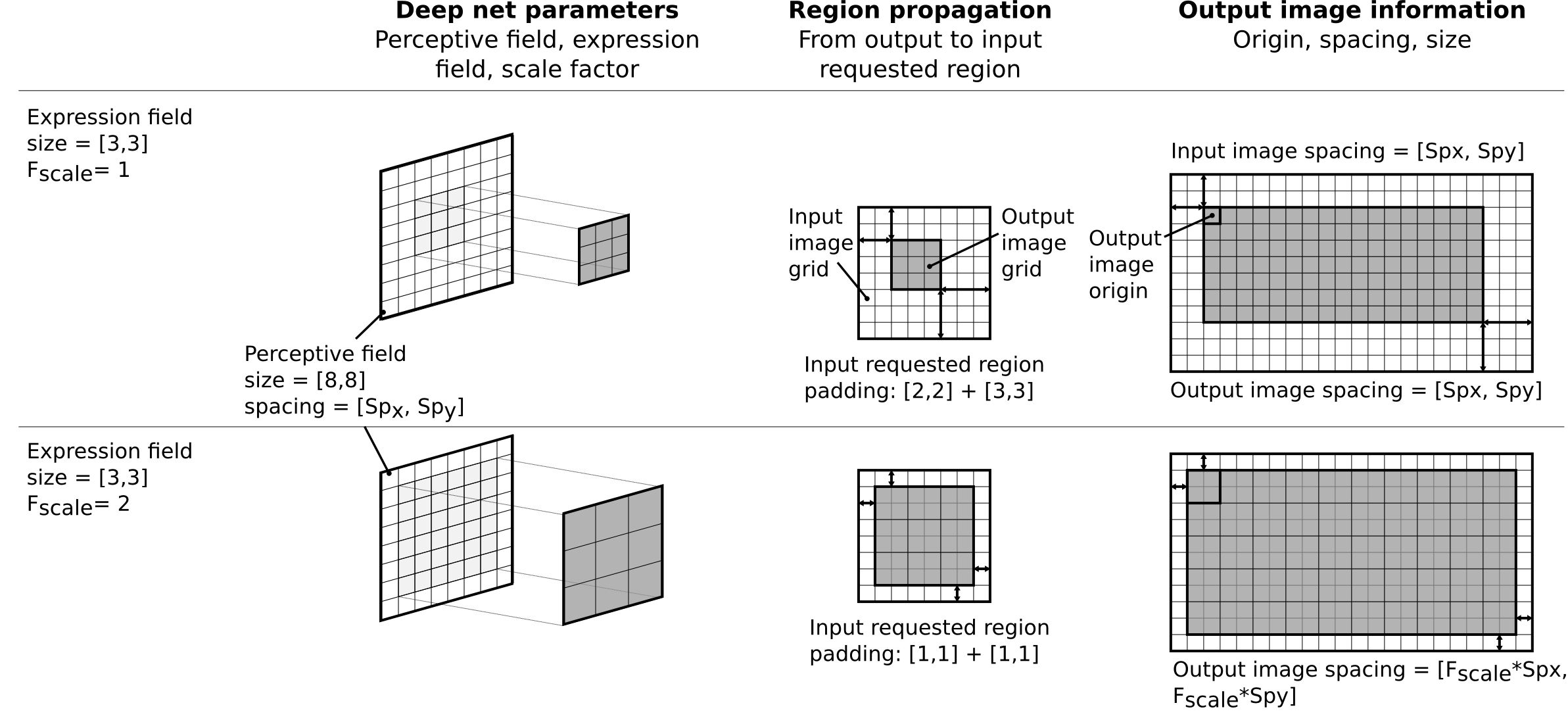
-
-The **scale factor** describes the physical change of spacing of the outputs, typically introduced in the model by non unitary strides in pooling or convolution operators.
-For each output, it is expressed relatively to one single input of the model called the _reference input source_.
-Additionally, the names of the _target nodes_ must be known (e.g. "optimizer").
-Also, the names of _user placeholders_, typically scalars placeholders that are used to control some parameters of the model, must be know (e.g. "dropout_rate").
-The **receptive field** corresponds to the input volume that "sees" the deep net.
-The **expression field** corresponds to the output volume that the deep net will create.
-
-## Train your Tensorflow model
-
-Here we assume that you have produced patches using the **PatchesExtraction** application, and that you have a **SavedModel** stored in a directory somewhere on your filesystem.
-The **TensorflowModelTrain** application performs the training, validation (against test dataset, and against validation dataset) providing the usual metrics that machine learning frameworks provide (confusion matrix, recall, precision, f-score, ...).
-You must provide the path of the **SavedModel** to the `model.dir` parameter.
-The `model.restorefrom` and `model.saveto` corresponds to the variables of the **SavedModel** used respectively for restoring and saving them.
-Set you _input sources_ for training (`training` parameter group) and for validation (`validation` parameter group): the evaluation is performed against training data, and optionally also against the validation data (only if you set `validation.mode` to "class").
-For each _input sources_, the patch size and the placeholder name must be provided.
-Regarding validation, if a different name is found in a particular _input source_ of the `validation` parameter group, the application knows that the _input source_ is not fed to the model at inference, but is used as reference to compute evaluation metrics of the validation dataset.
-Batch size (`training.batchsize`) and number of epochs (`training.epochs`) can be set.
-_User placeholders_ can be set separately for training (`training.userplaceholders`) and validation (`validation.userplaceholders`).
-The `validation.userplaceholders` can be useful if you have a model that behaves differently depending the given placeholder.
-Let's take the example of dropout: it's nice for training, but you have to disable it to use the model at inference time.
-Hence you will pass a placeholder with "dropout\_rate=0.3" for training and "dropout\_rate=0.0" for validation.
-Of course, one can train models from handmade python code: to import the patches images, a convenient method consist in reading patches images as numpy arrays using OTB applications (e.g. **ExtractROI**) or GDAL, then do a np.reshape to the dimensions wanted.
-
-
-
-```
-Train a multisource deep learning net using Tensorflow. Change the OTB_TF_NSOURCES environment variable to set the number of sources.
-Parameters:
- -model <group> Model parameters
-MISSING -model.dir <string> Tensorflow model_save directory (mandatory)
- -model.restorefrom <string> Restore model from path (optional, off by default)
- -model.saveto <string> Save model to path (optional, off by default)
- -training <group> Training parameters
- -training.batchsize <int32> Batch size (mandatory, default value is 100)
- -training.epochs <int32> Number of epochs (mandatory, default value is 100)
- -training.userplaceholders <string list> Additional single-valued placeholders for training. Supported types: int, float, bool. (optional, off by default)
-MISSING -training.targetnodes <string list> Names of the target nodes (mandatory)
- -training.outputtensors <string list> Names of the output tensors to display (optional, off by default)
- -training.usestreaming <boolean> Use the streaming through patches (slower but can process big dataset) (optional, off by default, default value is false)
- -training.source1 <group> Parameters for source #1 (training)
-MISSING -training.source1.il <string list> Input image (or list to stack) for source #1 (training) (mandatory)
-MISSING -training.source1.patchsizex <int32> Patch size (x) for source #1 (mandatory)
-MISSING -training.source1.patchsizey <int32> Patch size (y) for source #1 (mandatory)
-MISSING -training.source1.placeholder <string> Name of the input placeholder for source #1 (training) (mandatory)
- -training.source2 <group> Parameters for source #2 (training)
-MISSING -training.source2.il <string list> Input image (or list to stack) for source #2 (training) (mandatory)
-MISSING -training.source2.patchsizex <int32> Patch size (x) for source #2 (mandatory)
-MISSING -training.source2.patchsizey <int32> Patch size (y) for source #2 (mandatory)
-MISSING -training.source2.placeholder <string> Name of the input placeholder for source #2 (training) (mandatory)
- -validation <group> Validation parameters
- -validation.step <int32> Perform the validation every Nth epochs (mandatory, default value is 10)
- -validation.mode <string> Metrics to compute [none/class/rmse] (mandatory, default value is none)
- -validation.userplaceholders <string list> Additional single-valued placeholders for validation. Supported types: int, float, bool. (optional, off by default)
- -validation.usestreaming <boolean> Use the streaming through patches (slower but can process big dataset) (optional, off by default, default value is false)
- -validation.source1 <group> Parameters for source #1 (validation)
- -validation.source1.il <string list> Input image (or list to stack) for source #1 (validation) (mandatory)
- -validation.source1.name <string> Name of the input placeholder or output tensor for source #1 (validation) (mandatory)
- -validation.source2 <group> Parameters for source #2 (validation)
- -validation.source2.il <string list> Input image (or list to stack) for source #2 (validation) (mandatory)
- -validation.source2.name <string> Name of the input placeholder or output tensor for source #2 (validation) (mandatory)
- -progress <boolean> Report progress
- -help <string list> Display long help (empty list), or help for given parameters keys
-
-Use -help param1 [... paramN] to see detailed documentation of those parameters.
-
-Examples:
-otbcli_TensorflowModelTrain -source1.il spot6pms.tif -source1.placeholder x1 -source1.patchsizex 16 -source1.patchsizey 16 -source2.il labels.tif -source2.placeholder y1 -source2.patchsizex 1 -source2.patchsizex 1 -model.dir /tmp/my_saved_model/ -training.userplaceholders is_training=true dropout=0.2 -training.targetnodes optimizer -model.saveto /tmp/my_saved_model/variables/variables
-```
-
-As you can note, there is `$OTB_TF_NSOURCES` + 1 sources because we often need at least one more source for the reference data (e.g. terrain truth for land cover mapping).
-
-## Inference
-
-The **TensorflowModelServe** application performs the inference, it can be used to produce an output raster with the specified tensors.
-Thanks to the streaming mechanism, very large images can be produced.
-The application uses the `TensorflowModelFilter` and a `StreamingFilter` to force the streaming of output.
-This last can be optionally disabled by the user, if he prefers using the extended filenames to deal with chunk sizes.
-However, it's still very useful when the application is used in other composites applications, or just without extended filename magic.
-Some models can consume a lot of memory.
-In addition, the native tiling strategy of OTB consists in strips but this might not always the best.
-For Convolutional Neural Networks for instance, square tiles are more interesting because the padding required to perform the computation of one single strip of pixels induces to input a lot more pixels that to process the computation of one single tile of pixels.
-So, this application takes in input one or multiple _input sources_ (the number of _input sources_ can be changed by setting the `OTB_TF_NSOURCES` to the desired number) and produce one output of the specified tensors.
-The user is responsible of giving the **receptive field** and **name** of _input placeholders_, as well as the **expression field**, **scale factor** and **name** of _output tensors_.
-The first _input source_ (`source1.il`) corresponds to the _reference input source_.
-As explained [previously](#buildmodel), the **scale factor** provided for the _output tensors_ is related to this _reference input source_.
-The user can ask for multiple _output tensors_, that will be stack along the channel dimension of the output raster.
-However, if the sizes of those _output tensors_ are not consistent (e.g. a different number of (x,y) elements), an exception will be thrown.
-
-
-
-
-```
-Multisource deep learning classifier using TensorFlow. Change the OTB_TF_NSOURCES environment variable to set the number of sources.
-Parameters:
- -source1 <group> Parameters for source #1
-MISSING -source1.il <string list> Input image (or list to stack) for source #1 (mandatory)
-MISSING -source1.rfieldx <int32> Input receptive field (width) for source #1 (mandatory)
-MISSING -source1.rfieldy <int32> Input receptive field (height) for source #1 (mandatory)
-MISSING -source1.placeholder <string> Name of the input placeholder for source #1 (mandatory)
- -model <group> model parameters
-MISSING -model.dir <string> TensorFlow model_save directory (mandatory)
- -model.userplaceholders <string list> Additional single-valued placeholders. Supported types: int, float, bool. (optional, off by default)
- -model.fullyconv <boolean> Fully convolutional (optional, off by default, default value is false)
- -output <group> Output tensors parameters
- -output.spcscale <float> The output spacing scale, related to the first input (mandatory, default value is 1)
-MISSING -output.names <string list> Names of the output tensors (mandatory)
- -output.efieldx <int32> The output expression field (width) (mandatory, default value is 1)
- -output.efieldy <int32> The output expression field (height) (mandatory, default value is 1)
- -optim <group> This group of parameters allows optimization of processing time
- -optim.disabletiling <boolean> Disable tiling (optional, off by default, default value is false)
- -optim.tilesizex <int32> Tile width used to stream the filter output (mandatory, default value is 16)
- -optim.tilesizey <int32> Tile height used to stream the filter output (mandatory, default value is 16)
-MISSING -out <string> [pixel] output image [pixel=uint8/uint16/int16/uint32/int32/float/double/cint16/cint32/cfloat/cdouble] (default value is float) (mandatory)
- -progress <boolean> Report progress
- -help <string list> Display long help (empty list), or help for given parameters keys
-
-Use -help param1 [... paramN] to see detailed documentation of those parameters.
-
-Examples:
-otbcli_TensorflowModelServe -source1.il spot6pms.tif -source1.placeholder x1 -source1.rfieldx 16 -source1.rfieldy 16 -model.dir /tmp/my_saved_model/ -model.userplaceholders is_training=false dropout=0.0 -output.names out_predict1 out_proba1 -out "classif128tgt.tif?&streaming:type=tiled&streaming:sizemode=height&streaming:sizevalue=256"
-```
-
-## Composite applications for classification
-
-Who has never dreamed to use classic classifiers performing on deep learning features?
-This is possible thank to two new applications that uses the existing training/classification applications of OTB:
-
-**TrainClassifierFromDeepFeatures**: is a composite application that wire the **TensorflowModelServe** application output into the existing official **TrainImagesClassifier** application.
-
-```
-Train a classifier from deep net based features of an image and training vector data.
-Parameters:
- -source1 <group> Parameters for source 1
-MISSING -source1.il <string list> Input image (or list to stack) for source #1 (mandatory)
-MISSING -source1.rfieldx <int32> Input receptive field (width) for source #1 (mandatory)
-MISSING -source1.rfieldy <int32> Input receptive field (height) for source #1 (mandatory)
-MISSING -source1.placeholder <string> Name of the input placeholder for source #1 (mandatory)
- -model <group> Deep net inputs parameters
-MISSING -model.dir <string> TensorFlow model_save directory (mandatory)
- -model.userplaceholders <string list> Additional single-valued placeholders. Supported types: int, float, bool. (optional, off by default)
- -model.fullyconv <boolean> Fully convolutional (optional, off by default, default value is false)
- -output <group> Deep net outputs parameters
- -output.spcscale <float> The output spacing scale, related to the first input (mandatory, default value is 1)
-MISSING -output.names <string list> Names of the output tensors (mandatory)
- -output.efieldx <int32> The output expression field (width) (mandatory, default value is 1)
- -output.efieldy <int32> The output expression field (height) (mandatory, default value is 1)
- -optim <group> Processing time optimization
- -optim.disabletiling <boolean> Disable tiling (optional, off by default, default value is false)
- -optim.tilesizex <int32> Tile width used to stream the filter output (mandatory, default value is 16)
- -optim.tilesizey <int32> Tile height used to stream the filter output (mandatory, default value is 16)
- -ram <int32> Available RAM (Mb) (optional, off by default, default value is 128)
-MISSING -vd <string list> Vector data for training (mandatory)
- -valid <string list> Vector data for validation (optional, off by default)
-MISSING -out <string> Output classification model (mandatory)
- -confmatout <string> Output confusion matrix (optional, off by default)
- -sample <group> Sampling parameters
- -sample.mt <int32> Maximum training sample size per class (mandatory, default value is 1000)
- -sample.mv <int32> Maximum validation sample size per class (mandatory, default value is 1000)
- -sample.bm <int32> Bound sample number by minimum (mandatory, default value is 1)
- -sample.vtr <float> Training and validation sample ratio (mandatory, default value is 0.5)
- -sample.vfn <string> Field containing the class integer label for supervision (mandatory, no default value)
- -elev <group> Elevation parameters
- -elev.dem <string> DEM directory (optional, off by default)
- -elev.geoid <string> Geoid File (optional, off by default)
- -elev.default <float> Default elevation (mandatory, default value is 0)
- -classifier <string> Classifier parameters [libsvm/boost/dt/gbt/ann/bayes/rf/knn/sharkrf/sharkkm] (mandatory, default value is libsvm)
- -classifier.libsvm.k <string> SVM Kernel Type [linear/rbf/poly/sigmoid] (mandatory, default value is linear)
- -classifier.libsvm.m <string> SVM Model Type [csvc/nusvc/oneclass] (mandatory, default value is csvc)
- -classifier.libsvm.c <float> Cost parameter C (mandatory, default value is 1)
- -classifier.libsvm.nu <float> Cost parameter Nu (mandatory, default value is 0.5)
- -classifier.libsvm.opt <boolean> Parameters optimization (mandatory, default value is false)
- -classifier.libsvm.prob <boolean> Probability estimation (mandatory, default value is false)
- -classifier.boost.t <string> Boost Type [discrete/real/logit/gentle] (mandatory, default value is real)
- -classifier.boost.w <int32> Weak count (mandatory, default value is 100)
- -classifier.boost.r <float> Weight Trim Rate (mandatory, default value is 0.95)
- -classifier.boost.m <int32> Maximum depth of the tree (mandatory, default value is 1)
- -classifier.dt.max <int32> Maximum depth of the tree (mandatory, default value is 65535)
- -classifier.dt.min <int32> Minimum number of samples in each node (mandatory, default value is 10)
- -classifier.dt.ra <float> Termination criteria for regression tree (mandatory, default value is 0.01)
- -classifier.dt.cat <int32> Cluster possible values of a categorical variable into K <= cat clusters to find a suboptimal split (mandatory, default value is 10)
- -classifier.dt.f <int32> K-fold cross-validations (mandatory, default value is 10)
- -classifier.dt.r <boolean> Set Use1seRule flag to false (mandatory, default value is false)
- -classifier.dt.t <boolean> Set TruncatePrunedTree flag to false (mandatory, default value is false)
- -classifier.gbt.w <int32> Number of boosting algorithm iterations (mandatory, default value is 200)
- -classifier.gbt.s <float> Regularization parameter (mandatory, default value is 0.01)
- -classifier.gbt.p <float> Portion of the whole training set used for each algorithm iteration (mandatory, default value is 0.8)
- -classifier.gbt.max <int32> Maximum depth of the tree (mandatory, default value is 3)
- -classifier.ann.t <string> Train Method Type [back/reg] (mandatory, default value is reg)
- -classifier.ann.sizes <string list> Number of neurons in each intermediate layer (mandatory)
- -classifier.ann.f <string> Neuron activation function type [ident/sig/gau] (mandatory, default value is sig)
- -classifier.ann.a <float> Alpha parameter of the activation function (mandatory, default value is 1)
- -classifier.ann.b <float> Beta parameter of the activation function (mandatory, default value is 1)
- -classifier.ann.bpdw <float> Strength of the weight gradient term in the BACKPROP method (mandatory, default value is 0.1)
- -classifier.ann.bpms <float> Strength of the momentum term (the difference between weights on the 2 previous iterations) (mandatory, default value is 0.1)
- -classifier.ann.rdw <float> Initial value Delta_0 of update-values Delta_{ij} in RPROP method (mandatory, default value is 0.1)
- -classifier.ann.rdwm <float> Update-values lower limit Delta_{min} in RPROP method (mandatory, default value is 1e-07)
- -classifier.ann.term <string> Termination criteria [iter/eps/all] (mandatory, default value is all)
- -classifier.ann.eps <float> Epsilon value used in the Termination criteria (mandatory, default value is 0.01)
- -classifier.ann.iter <int32> Maximum number of iterations used in the Termination criteria (mandatory, default value is 1000)
- -classifier.rf.max <int32> Maximum depth of the tree (mandatory, default value is 5)
- -classifier.rf.min <int32> Minimum number of samples in each node (mandatory, default value is 10)
- -classifier.rf.ra <float> Termination Criteria for regression tree (mandatory, default value is 0)
- -classifier.rf.cat <int32> Cluster possible values of a categorical variable into K <= cat clusters to find a suboptimal split (mandatory, default value is 10)
- -classifier.rf.var <int32> Size of the randomly selected subset of features at each tree node (mandatory, default value is 0)
- -classifier.rf.nbtrees <int32> Maximum number of trees in the forest (mandatory, default value is 100)
- -classifier.rf.acc <float> Sufficient accuracy (OOB error) (mandatory, default value is 0.01)
- -classifier.knn.k <int32> Number of Neighbors (mandatory, default value is 32)
- -classifier.sharkrf.nbtrees <int32> Maximum number of trees in the forest (mandatory, default value is 100)
- -classifier.sharkrf.nodesize <int32> Min size of the node for a split (mandatory, default value is 25)
- -classifier.sharkrf.mtry <int32> Number of features tested at each node (mandatory, default value is 0)
- -classifier.sharkrf.oobr <float> Out of bound ratio (mandatory, default value is 0.66)
- -classifier.sharkkm.maxiter <int32> Maximum number of iteration for the kmeans algorithm. (mandatory, default value is 10)
- -classifier.sharkkm.k <int32> The number of class used for the kmeans algorithm. (mandatory, default value is 2)
- -rand <int32> User defined random seed (optional, off by default)
- -inxml <string> Load otb application from xml file (optional, off by default)
- -progress <boolean> Report progress
- -help <string list> Display long help (empty list), or help for given parameters keys
-
-Use -help param1 [... paramN] to see detailed documentation of those parameters.
-
-Examples:
-None
-```
-
-**ImageClassifierFromDeepFeatures** same approach with the official **ImageClassifier**.
-
-```
-Classify image using features from a deep net and an OTB machine learning classification model
-Parameters:
- -source1 <group> Parameters for source 1
-MISSING -source1.il <string list> Input image (or list to stack) for source #1 (mandatory)
-MISSING -source1.rfieldx <int32> Input receptive field (width) for source #1 (mandatory)
-MISSING -source1.rfieldy <int32> Input receptive field (height) for source #1 (mandatory)
-MISSING -source1.placeholder <string> Name of the input placeholder for source #1 (mandatory)
- -deepmodel <group> Deep net model parameters
-MISSING -deepmodel.dir <string> TensorFlow model_save directory (mandatory)
- -deepmodel.userplaceholders <string list> Additional single-valued placeholders. Supported types: int, float, bool. (optional, off by default)
- -deepmodel.fullyconv <boolean> Fully convolutional (optional, off by default, default value is false)
- -output <group> Deep net outputs parameters
- -output.spcscale <float> The output spacing scale, related to the first input (mandatory, default value is 1)
-MISSING -output.names <string list> Names of the output tensors (mandatory)
- -output.efieldx <int32> The output expression field (width) (mandatory, default value is 1)
- -output.efieldy <int32> The output expression field (height) (mandatory, default value is 1)
- -optim <group> This group of parameters allows optimization of processing time
- -optim.disabletiling <boolean> Disable tiling (optional, off by default, default value is false)
- -optim.tilesizex <int32> Tile width used to stream the filter output (mandatory, default value is 16)
- -optim.tilesizey <int32> Tile height used to stream the filter output (mandatory, default value is 16)
-MISSING -model <string> Model file (mandatory)
- -imstat <string> Statistics file (optional, off by default)
- -nodatalabel <int32> Label mask value (optional, off by default, default value is 0)
-MISSING -out <string> [pixel] Output image [pixel=uint8/uint16/int16/uint32/int32/float/double/cint16/cint32/cfloat/cdouble] (default value is uint8) (mandatory)
- -confmap <string> [pixel] Confidence map image [pixel=uint8/uint16/int16/uint32/int32/float/double/cint16/cint32/cfloat/cdouble] (default value is double) (optional, off by default)
- -ram <int32> Ram (optional, off by default, default value is 128)
- -inxml <string> Load otb application from xml file (optional, off by default)
- -progress <boolean> Report progress
- -help <string list> Display long help (empty list), or help for given parameters keys
-
-Use -help param1 [... paramN] to see detailed documentation of those parameters.
-
-Examples:
-None
-```
-
-Note that you can still set the `OTB_TF_NSOURCES` environment variable.
-
-# Basic example
-
-Below is a minimal example that presents the main steps to train a model, and perform the inference.
-
-## Sampling
-
-Here we will try to provide a simple example of doing a classification using a deep net that performs on one single VHR image.
-Our data set consists in one Spot-7 image, *spot7.tif*, and a training vector data, *terrain_truth.shp* that describes sparsely forest / non-forest polygons.
-First, we compute statistics of the vector data : how many points can we sample inside objects, and how many objects in each class.
-We use the **PolygonClassStatistics** application of OTB.
-```
-otbcli_PolygonClassStatistics -vec terrain_truth.shp -field class -in spot7.tif -out vec_stats.xml
-```
-Then, we will select some samples with the **SampleSelection** application of the existing machine learning framework of OTB.
-Since the terrain truth is sparse, we want to sample randomly points in polygons with the default strategy of the **SampleSelection** OTB application.
-```
-otbcli_SampleSelection -in spot7.tif -vec terrain_truth.shp -instats vec_stats.xml -field class -out points.shp
-```
-Now we extract the patches with the **PatchesExtraction** application.
-We want to produce one image of 16x16 patches, and one image for the corresponding labels.
-```
-otbcli_PatchesExtraction -source1.il spot7.tif -source1.patchsizex 16 -source1.patchsizey 16 -vec points.shp -field class -source1.out samp_labels.tif -outpatches samp_patches.tif
-```
-
-## Training
-
-Now we have two images for patches and labels.
-We can split them to distinguish test/validation groups (with the **ExtractROI** application for instance).
-But here, we will just perform some fine tuning of our model.
-The **SavedModel** is located in the `outmodel` directory.
-Our model is quite basic: it has two input placeholders, **x1** and **y1** respectively for input patches (with size 16x16) and input reference labels (with size 1x1).
-We named **prediction** the tensor that predict the labels and the optimizer that perform the stochastic gradient descent is an operator named **optimizer**.
-We perform the fine tuning and we export the new model variables directly in the _outmodel/variables_ folder, overwriting the existing variables of the model.
-We use the **TensorflowModelTrain** application to perform the training of this existing model.
-```
-otbcli_TensorflowModelTrain -model.dir /path/to/oursavedmodel -training.targetnodesnames optimizer -training.source1.il samp_patches.tif -training.source1.patchsizex 16 -training.source1.patchsizey 16 -training.source1.placeholder x1 -training.source2.il samp_labels.tif -training.source2.patchsizex 1 -training.source2.patchsizey 1 -training.source2.placeholder y1 -model.saveto /path/to/oursavedmodel/variables/variables
-```
-Note that we could also have performed validation in this step. In this case, the `validation.source2.placeholder` would be different than the `training.source2.placeholder`, and would be **prediction**. This way, the program know what is the target tensor to evaluate.
-
-## Inference
-
-After this step, we use the trained model to produce the entire map of forest over the whole Spot-7 image.
-For this, we use the **TensorflowModelServe** application to produce the **prediction** tensor output for the entire image.
-```
-otbcli_TensorflowModelServe -source1.il spot7.tif -source1.placeholder x1 -source1.rfieldx 16 -source1.rfieldy 16 -model.dir /path/to/oursavedmodel -output.names prediction -out map.tif uint8
-```
diff --git a/doc/CREATEYOUROWN.md b/doc/CREATEYOUROWN.md
deleted file mode 100644
index 4a22d4ef..00000000
--- a/doc/CREATEYOUROWN.md
+++ /dev/null
@@ -1,37 +0,0 @@
-# Create your own architecture
-
-This section gives a few tips to create your own models ready to be used in inference using OTBTF's `TensorflowModelServe` and `TensorflowModelTrain` applications.
-
-## Model inputs
-
-### Dimensions
-
-All networks must input **4D tensors**.
-- **dim 0** is for the batch dimension. It is used in the `TensorflowModelTrain` application during training, and in **patch-based mode** during inference: in this mode, `TensorflowModelServe` performs the inference of several patches simultaneously. In **fully-convolutional mode**, a single slice of the batch dimension is used.
-- **dim 1** and **2** are for the spatial dimensions,
-- **dim 3** is for the image channels. Even if your image have only 1 channel, you must set a shape value equals to 1 for the last dimension of the input placeholder.
-
-### Shapes
-
-For nets intended to work in **patch-based** mode, you can stick with a placeholder where you define your patch size explicitly in **dim 1** and **dim 2**.
-However, for nets intended to work in **fully-convolutional** mode, you must set `None` in **dim 1** and **dim 2** (before Tensorflow 2.X, it was possible to feed placeholders with a tensor of different size where the dims were defined, but no more after!).
-For instance, let consider an input raster with 4 spectral bands: the input shape of the model input would be like `[None, None, None, 4]` to work in fully-convolutional mode. By doing so, the use of input images of any size is enabled (`TensorflowModelServe` will automatically compute the input/output regions sizes to process, given the **receptive field** and **expression field** of your net).
-
-## Model outputs
-
-### Dimensions
-
-Supported tensors for the outputs must have **between 2 and 4 dimensions**.
-OTBTF always consider that **the size of the last dimension is the number of channels in the output**.
-For instance, you can have a model that outputs 8 channels with a tensor of shape `[None, 8]` or `[None, None, None, 8]`
-
-### Name your tensors and nodes
-
-Always name explicitly your models outputs. You will need the output tensor name for performing the inference with `TensoflowModelServe`. If you forget to name them, use the graph viewer in `tensorboard` to get the names.
-
-### Training
-
-If you want to enable your network training with the `TensorflowModelTrain` application, do not forget to name your optimizers/operators!
-You can build a single operator from multiple ones using the `tf.group` command, which also enable you to name your new operator.
-For sequential nodes trigger, you can build an operator that do what you want is the desired order using the `tf.control_dependancies` with TF <= 1.15.
-
diff --git a/doc/EXAMPLES.md b/doc/EXAMPLES.md
deleted file mode 100644
index d48c56a9..00000000
--- a/doc/EXAMPLES.md
+++ /dev/null
@@ -1,317 +0,0 @@
-# Examples
-
-Some examples of ready-to-use deep learning architectures built with the TensorFlow API from python.
-All models used are provided in this directory.
-
-**Table of Contents**
-1. [Simple CNN](#part1)
-2. [Fully convolutional network](#part2)
-3. [M3Fusion Model](#part3)
-4. [Maggiori model](#part4)
-5. [Fully convolutional network with separate Pan/MS channels](#part5)
-
-## Simple CNN <a name="part1"></a>
-
-This simple model estimates the class of an input patch of image.
-This model consists in successive convolutions/pooling/relu of the input (*x* placeholder).
-At some point, the feature map is connected to a dense layer which has N neurons, N being the number of classes we want.
-The training operator (*optimizer* node) performs the gradient descent of the loss function corresponding to the cross entropy of (the softmax of) the N neurons output and the reference labels (*y* placeholder).
-Predicted label is the argmax of the N neurons (*prediction* tensor).
-Predicted label is a single pixel, for an input patch of size 16x16 (for an input *x* of size 16x16, the *prediction* has a size of 1x1).
-The learning rate of the training operator can be adjusted using the *lr* placeholder.
-The following figure summarizes this architecture.
-
-<img src ="https://gitlab.irstea.fr/remi.cresson/otbtf/-/raw/develop/doc/images/savedmodel_simple_cnn.png" />
-
-### Generate the model
-
-Use the python script to generate the SavedModel that will be used by OTBTF applications.
-
-```
-python create_savedmodel_simple_cnn.py --outdir $modeldir
-```
-
-Note that you can adjust the number of classes for the model with the `--nclasses` option.
-
-### Train the model
-
-Use **TensorflowModelTrain** to train this model.
-
-```
-otbcli_TensorflowModelTrain \
--model.dir $modeldir \
--model.saveto "$modeldir/variables/variables" \
--training.source1.il $patches_train -training.source1.patchsizex 1 -training.source1.patchsizey 1 -training.source1.placeholder "x" \
--training.source2.il $labels_train -training.source2.patchsizex 1 -training.source2.patchsizey 1 -training.source2.placeholder "y" \
--training.targetnodes "optimizer" \
--validation.mode "class" \
--validation.source1.il $patches_valid -validation.source1.name "x" \
--validation.source2.il $labels_valid -validation.source2.name "prediction"
-```
-
-Type `otbcli_TensorflowModelTrain --help` to display the help.
-
-For instance, you can change the number of epochs to 50 with `-training.epochs 50` or you can change the batch size to 8 with `-training.batchsize 8`.
-In addition, it is possible to feed some scalar values to scalar placeholder of the model (currently, bool, int and float are supported).
-For instance, our model has a placeholder called *lr* that controls the learning rate of the optimizer.
-We can change this value at runtime using `-training.userplaceholders "lr=0.0002"`
-
-### Inference
-
-This model can be used either in patch-based mode or in fully convolutional mode.
-
-#### Patch-based mode
-
-You can estimate the class of every pixels of your input image.
-Since the model is able to estimate the class of the center value of a 16x16 patch, you can run the model over the whole image in patch-based mode.
-
-```
-otbcli_TensorflowModelServe \
--source1.il $image" \
--source1.rfieldx 16 \
--source1.rfieldy 16 \
--source1.placeholder "x" \
--model.dir $modeldir \
--output.names "prediction" \
--out $output_classif
-```
-
-However, patch-based approach is slow because each patch is processed independently, which is not computationally efficient.
-
-#### Fully convolutional mode
-
-In fully convolutional mode, the model is used to process larger blocks in order to estimate simultaneously multiple pixels classes.
-The model has a total number of 4 strides (caused by pooling).
-Hence the physical spacing of the features maps, in spatial dimensions, is divided by 4.
-This is what is called *spcscale* in the **TensorflowModelServe** application.
-If you want to use the model in fully convolutional mode, you have to tell **TensorflowModelServe** that the model performs a change of physical spacing of the output, 4 in our case.
-
-```
-otbcli_TensorflowModelServe \
--source1.il $image" \
--source1.rfieldx 16 \
--source1.rfieldy 16 \
--source1.placeholder "x" \
--output.names "prediction" \
--output.spcscale 4 \
--model.dir $modeldir \
--model.fullyconv on \
--out $output_classif_fcn
-```
-
-## Fully convolutional network <a name="part2"></a>
-
-The `create_savedmodel_simple_fcn.py` script enables you to create a fully convolutional model which does not use any stride.
-
-<img src ="https://gitlab.irstea.fr/remi.cresson/otbtf/-/raw/develop/doc/images/savedmodel_simple_fcnn.png" />
-
-Thank to that, once trained this model can be applied on the image to produce a landcover map at the same resolution as the input image, in a fully convolutional (i.e. fast) manner.
-The main difference with the model described in the previous section is the *spcscale* parameter that must be let to default (i.e. unitary).
-
-Create the SavedModel using `python create_savedmodel_simple_fcn.py --outdir $modeldir` then train it as before.
-Then you can produce the land cover map at pixel level in fully convolutional mode:
-```
-otbcli_TensorflowModelServe \
--source1.il $image" \
--source1.rfieldx 16 \
--source1.rfieldy 16 \
--source1.placeholder "x" \
--output.names "prediction" \
--model.dir $modeldir \
--model.fullyconv on \
--out $output_classif
-```
-
-## M3Fusion Model <a name="part3"></a>
-
-The M3Fusion model (stands for MultiScale/Multimodal/Multitemporal satellite data fusion) is a model designed to input time series and very high resolution images.
-
-Benedetti, P., Ienco, D., Gaetano, R., Ose, K., Pensa, R. G., & Dupuy, S. (2018). _M3Fusion: A Deep Learning Architecture for Multiscale Multimodal Multitemporal Satellite Data Fusion_. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 11(12), 4939-4949.
-
-See the original paper [here](https://arxiv.org/pdf/1803.01945).
-
-The M3 model is patch-based, and process two input sources simultaneously: (i) time series, and (ii) a very high resolution image.
-The output class estimation is performed at pixel level.
-
-### Generate the model
-
-```
-python create_savedmodel_ienco-m3_patchbased.py --outdir $modeldir
-```
-
-Note that you can adjust the number of classes for the model with the `--nclasses` option.
-Type `python create_savedmodel_ienco-m3_patchbased.py --help` to see the other available parameters.
-
-### Train the model
-
-Let's train the M3 model from time series (TS) and Very High Resolution Satellite (VHRS) patches images.
-
-<img src ="https://gitlab.irstea.fr/remi.cresson/otbtf/-/raw/develop/doc/images/model_training.png" />
-
-First, tell OTBTF that we want two sources: one for time series + one for VHR image
-
-```
-export OTB_TF_NSOURCES=2
-```
-
-Run the **TensorflowModelTrain** application of OTBTF.
-
-Note that for time series we could also have provided a list of images rather that a single big images stack (since "sourceX.il" is an input image list parameter).
-
-```
-otbcli_TensorflowModelTrain \
--model.dir $modeldir \
--model.saveto "$modeldir/variables/variables" \
--training.source1.il $patches_ts_train -training.source1.patchsizex 1 -training.source1.patchsizey 1 -training.source1.placeholder "x_rnn" \
--training.source2.il $patches_vhr_train -training.source2.patchsizex 25 -training.source2.patchsizey 25 -training.source2.placeholder "x_cnn" \
--training.source3.il $labels_train -training.source3.patchsizex 1 -training.source3.patchsizey 1 -training.source3.placeholder "y" \
--training.targetnodes "optimizer" \
--training.userplaceholders "is_training=true" "drop_rate=0.1" "learning_rate=0.0002" \
--validation.mode "class" -validation.step 1 \
--validation.source1.il $patches_ts_valid -validation.source1.name "x_rnn" \
--validation.source2.il $patches_vhr_valid -validation.source2.name "x_cnn" \
--validation.source3.il $labels_valid -validation.source3.name "prediction"
-```
-
-### Inference
-
-Let's produce a land cover map using the M3 model from time series (TS) and Very High Resolution Satellite image (VHRS)
-
-<img src ="https://gitlab.irstea.fr/remi.cresson/otbtf/-/raw/develop/doc/images/classif_map.png" />
-
-Since we provide time series as the reference source (*source1*), the output classes are estimated at the same resolution.
-This model can be run in patch-based mode only.
-
-```
-otbcli_TensorflowModelServe \
--source1.il $ts -source1.rfieldx 1 -source1.rfieldy 1 -source1.placeholder "x_rnn" \
--source2.il $vhr -source2.rfieldx 25 -source2.rfieldy 25 -source2.placeholder "x_cnn" \
--model.dir $modeldir \
--output.names "prediction" -out $output_classif
-```
-
-## Maggiori model <a name="part4"></a>
-
-This architecture was one of the first to introduce a fully convolutional model suited for large scale remote sensing images.
-
-Maggiori, E., Tarabalka, Y., Charpiat, G., & Alliez, P. (2016). _Convolutional neural networks for large-scale remote-sensing image classification_. IEEE Transactions on Geoscience and Remote Sensing, 55(2), 645-657.
-
-See the original paper [here](https://hal.inria.fr/hal-01350706/document).
-This fully convolutional model performs binary semantic segmentation of large scale images without any blocking artifacts.
-
-### Generate the model
-
-```
-python create_savedmodel_maggiori17_fullyconv.py --outdir $modeldir
-```
-
-You can change the number of spectral bands of the input image that is processed with the model, using the `--n_channels` option.
-
-### Train the model
-
-The model perform the semantic segmentation from one single source.
-
-```
-otbcli_TensorflowModelTrain \
--model.dir $modeldir \
--model.saveto "$modeldir/variables/variables" \
--training.source1.il $patches_image_train -training.source1.patchsizex 80 -training.source1.patchsizey 80 -training.source1.placeholder "x" \
--training.source2.il $patches_labels_train -training.source2.patchsizex 16 -training.source2.patchsizey 16 -training.source2.placeholder "y" \
--training.targetnodes "optimizer" \
--training.userplaceholders "is_training=true" "learning_rate=0.0002" \
--validation.mode "class" -validation.step 1 \
--validation.source1.il $patches_image_valid -validation.source1.name "x" \
--validation.source2.il $patches_labels_valid -validation.source2.name "estimated" \
-```
-
-Note that the `userplaceholders` parameter contains the *is_training* placeholder, fed with value *true* because the default value for this placeholder is *false*, and it is used in the batch normalization layers (take a look in the `create_savedmodel_maggiori17_fullyconv.py` code).
-
-### Inference
-
-This model can be used in fully convolutional mode only.
-This model performs convolutions with stride (i.e. downsampling), followed with transposed convolutions with strides (i.e. upsampling).
-Since there is no change of physical spacing (because downsampling and upsampling have both the same number of strides), the *spcscale* parameter is let to default (i.e. unitary).
-The receptive field of the model is 80x80, and the expression field is 16x16, due to the fact that the model keeps only the exact part of the output features maps.
-
-```
-otbcli_TensorflowModelServe \
--source1.il $image -source1.rfieldx 80 -source1.rfieldy 80 -source1.placeholder x \
--model.dir $modeldir \
--model.fullyconv on \
--output.names "estimated" -output.efieldx 16 -output.efieldy 16 \
--out $output_classif
-```
-
-## Fully convolutional network with separate Pan/MS channels <a name="part5"></a>
-
-It's common that very high resolution products are composed with a panchromatic channel at high-resolution (Pan), and a multispectral image generally at lower resolution (MS).
-This model inputs separately the two sources (Pan and MS) separately.
-
-See: Gaetano, R., Ienco, D., Ose, K., & Cresson, R. (2018). A two-branch CNN architecture for land cover classification of PAN and MS imagery. Remote Sensing, 10(11), 1746.
-
-<img src ="https://gitlab.irstea.fr/remi.cresson/otbtf/-/raw/develop/doc/images/savedmodel_simple_pxs_fcn.png" />
-
-Use `create_savedmodel_pxs_fcn.py` to generate this model.
-
-During training, the *x1* and *x2* placeholders must be fed respectively with patches of size 8x8 and 32x32.
-You can use this model in a fully convolutional way with receptive field of size 32 (for the Pan image) and 8 (for the MS image) and an unitary expression field (i.e. equal to 1).
-Don't forget to tell OTBTF that we want two sources: one for Ms image + one for Pan image
-
-```
-export OTB_TF_NSOURCES=2
-```
-
-### Inference at MS image resolution
-
-Here we perform the land cover map at the same resolution as the MS image.
-Do do this, we set the MS image as the first source in the **TensorflowModelServe** application.
-
-```
-otbcli_TensorflowModelServe \
--source1.il $ms -source1.rfieldx 8 -source1.rfieldy 8 -source1.placeholder "x1" \
--source2.il $pan -source2.rfieldx 32 -source2.rfieldy 32 -source2.placeholder "x2" \
--model.dir $modeldir \
--model.fullyconv on \
--output.names "prediction" \
--out $output_classif
-```
-
-Note that we could also have set the Pan image as the first source, and tell the application to use a *spcscale* of 4.
-```
-otbcli_TensorflowModelServe \
--source1.il $pan -source1.rfieldx 32 -source1.rfieldy 32 -source1.placeholder "x2" \
--source2.il $ms -source2.rfieldx 8 -source2.rfieldy 8 -source2.placeholder "x1" \
--model.dir $modeldir \
--model.fullyconv on \
--output.names "prediction" \
--output.spcscale 4 \
--out $output_classif
-```
-
-### Inference at Pan image resolution
-
-Here we perform the land cover map at the same resolution as the Pan image.
-Do do this, we set the Pan image as the first source in the **TensorflowModelServe** application.
-Note that this model can not be applied in a fully convolutional fashion at the Pan image resolution.
-We hence perform the processing in patch-based mode.
-
-```
-otbcli_TensorflowModelServe \
--source1.il $pan -source1.rfieldx 32 -source1.rfieldy 32 -source1.placeholder "x2" \
--source2.il $ms -source2.rfieldx 8 -source2.rfieldy 8 -source2.placeholder "x1" \
--model.dir $modeldir \
--output.names "prediction" \
--out $output_classif
-```
-
-Note that we could also have set the MS image as the first source, and tell the application to use a *spcscale* of 0.25.
-
-```
-otbcli_TensorflowModelServe \
--source1.il $ms -source1.rfieldx 8 -source1.rfieldy 8 -source1.placeholder "x1" \
--source2.il $pan -source2.rfieldx 32 -source2.rfieldy 32 -source2.placeholder "x2" \
--model.dir $modeldir \
--model.fullyconv on \
--output.names "prediction" \
--out $output_classif
-```
diff --git a/doc/api_distributed.md b/doc/api_distributed.md
new file mode 100644
index 00000000..1478022c
--- /dev/null
+++ b/doc/api_distributed.md
@@ -0,0 +1,143 @@
+# Distributed training
+
+Thanks to the new API of Tensorflow since version 2.0, it's very easy to
+perform distributed tranining with the exact same code. Just one single line
+has to be changed!
+
+## Overview
+
+In the following, we will explain how to use multiple nodes of a GPU cluster
+like the [Jean-Zay supercomputer](http://www.idris.fr/eng/jean-zay/jean-zay-presentation-eng.html),
+using `tf.distribute.MultiWorkerMirroredStrategy`.
+We will adopt the data parallelism scheme, meaning that all the computing
+devices will have replicas of the model, but different chunks of data.
+The principle is that once the forward propagation is performed, the gradients
+from the different devices are aggregated together, and the weights are updated
+on all GPUs.
+
+
+<div align="center" width="50%">
+<img src="http://www.idris.fr/media/images/jean-zay-annonce-01.jpg?id=web%3Ajean-zay%3Ajean-zay-presentation" width=50%>
+<figcaption>Jean-Zay has several hundreds of computing nodes with 4 or 8 GPUs. Copyright Photothèque CNRS/Cyril Frésillon</figcaption>
+</div>
+
+## Python code
+
+We can start from the codebase of the fully convolutional model example
+described in the OTBTF [Python API tutorial](#api_tutorial.html).
+
+### Dataset
+
+For distributed training, we recommend to use the TFRecords rather than the
+Patch based images.
+This has two advantages:
+
+- Performance in terms of I/O
+- `otbtf` can be imported without anything else than `tensorflow` as
+dependency. Indeed, the `otbtf.TFRecords` class just needs the `tensorflow`
+module to work.
+
+!!! Info
+
+ When imported, OTBTF tries to import the GDAL-related classes (e.g.
+ `PatchesImagesReader`) and skip the import if an `ImportError` occurs (i.e.
+ when GDAL is not present in the environment). This allows to safely use the
+ other classes that rely purely on the `tensorflow` module (e.g.
+ `otbtf.ModelBase`, `otbtf.TFRecords`, etc.).
+
+### Prerequisites
+
+To use OTBTF on environment where only Tensorflow is available, you can just
+clone the OTBTF repository somewhere and install it in your favorite virtual
+environment with `pip`. Or you can also just update the `PYTHONPATH` to include
+the *otbtf* folder. You just have to be able to perform the import of the
+module from python code:
+
+```python
+import otbtf
+```
+
+### Strategy
+
+We change the strategy from `tf.distribute.MirroredStrategy` to
+`tf.distribute.MultiWorkerMirroredStrategy`.
+
+First, we have to instantiate a cluster resolver for SLURM, which is the job
+scheduler of the cluster. The cluster resolver uses the environment variables
+provided by SLURM to grab the useful parameters. On the Jean-Zay computer,
+the port base is **13565**:
+
+```python
+cluster_resolver = tf.distribute.cluster_resolver.SlurmClusterResolver(
+ port_base=13565
+)
+```
+
+Then we specify a communication protocol. The Jean-Zay computer supports
+the NVIDIA NCCL communication protocol, which links tightly GPUs from different
+nodes:
+
+```python
+implementation = tf.distribute.experimental.CommunicationImplementation.NCCL
+communication_options = tf.distribute.experimental.CommunicationOptions(
+ implementation=implementation
+)
+```
+
+Finally, we can replace the strategy with the distributed one:
+
+```python
+#strategy = tf.distribute.MirroredStrategy() # <-- that was before
+strategy = tf.distribute.MultiWorkerMirroredStrategy(
+ cluster_resolver=cluster_resolver,
+ communication_options=communication_options
+)
+```
+
+The rest of the code is identical.
+
+!!! Warning
+
+ Be careful when calling `mymodel.save()` to export the SavedModel. When
+ multiple nodes are used in parallel, this can lead to a corrupt save.
+ One good practice is to defer the call only to the master worker (e.g. node
+ 0). You can identify the master worker using `otbtf.model._is_chief()`.
+
+## SLURM job
+
+Now we have to provide a SLURM job to run our python code over several nodes.
+Below is the content of the *job.slurm* file:
+
+```commandline
+#!/bin/bash
+#SBATCH -A <your_account>@gpu
+#SBATCH --job-name=<job_name>
+#SBATCH --nodes=4 # number of nodes
+#SBATCH --ntasks-per-node=4 # number of MPI task per node
+#SBATCH --gres=gpu:4 # number of GPU per node
+#SBATCH --cpus-per-task=10 # number of cores per task
+#SBATCH --qos=qos_gpu-t3
+#SBATCH --time=00:59:00
+#SBATCH -C v100-16g # Multiworker strategy wants homogeneous GPUs
+
+cd ${SLURM_SUBMIT_DIR}
+
+# deactivate the HTTP proxy (mandatory for multi-node)
+unset http_proxy https_proxy HTTP_PROXY HTTPS_PROXY
+module purge
+module load tensorflow-gpu/py3/2.8.0
+
+export PYTHONPATH=$PYTHONPATH:/path/to/otbtf/
+srun
+python3 /path/to/your_code.py
+```
+
+To submit the job, run the following command:
+```commandline
+sbatch job.slurm
+```
+
+## References
+
+- [Jean-Zay users documentation](https://jean-zay-doc.readthedocs.io/en/latest/)
+- [Official Jean-Zay documentation](http://www.idris.fr/jean-zay/gpu/jean-zay-gpu-tf-multi.html)
diff --git a/doc/api_model_generalities.md b/doc/api_model_generalities.md
new file mode 100644
index 00000000..a4e4a640
--- /dev/null
+++ b/doc/api_model_generalities.md
@@ -0,0 +1,57 @@
+# Model generalities
+
+This section gives a few tips to create your own models ready to be used in
+OTBTF.
+
+## Inputs dimensions
+
+All networks must input **4D tensors**.
+
+- **dim 0** is for the batch dimension. It is used in the
+`TensorflowModelTrain` application during training, and in
+**patch-based mode** during inference: in this mode, `TensorflowModelServe`
+performs the inference of several patches simultaneously. In
+**fully-convolutional mode**, a single slice of the batch dimension is used.
+- **dim 1** and **2** are for the spatial dimensions,
+- **dim 3** is for the image channels. Even if your image have only 1 channel,
+you must set a shape value equals to 1 for the last dimension of the input
+placeholder.
+
+## Inputs shapes
+
+For networks intended to work in **patch-based** mode, you can stick with a
+placeholder having a patch size explicitly defined in **dims 1 and 2**.
+However, for networks intended to work in **fully-convolutional** mode,
+you must set `None` in **dim 1** and **dim 2** (before Tensorflow 2.X, it was
+possible to feed placeholders with a tensor of different size where the dims
+were defined). For instance, let consider an input raster with 4 spectral
+bands: the input shape of the model input would be like `[None, None, None, 4]`
+to work in fully-convolutional mode. By doing so, the use of input images of
+any size is enabled (`TensorflowModelServe` will automatically compute the
+input/output regions sizes to process, given the **receptive field** and
+**expression field** of your network).
+
+## Outputs dimensions
+
+Supported tensors for the outputs must have **between 2 and 4 dimensions**.
+OTBTF always consider that **the size of the last dimension is the number of
+channels in the output**.
+For instance, you can have a model that outputs 8 channels with a tensor of
+shape `[None, 8]` or `[None, None, None, 8]`
+
+## Outputs names
+
+Always name explicitly your models outputs. You will need the output tensor
+name for performing the inference with `TensoflowModelServe`. If you forget to
+name them, use the graph viewer in `tensorboard` to get the names.
+
+!!! note
+
+ If you want to enable your network training with the `TensorflowModelTrain`
+ application, you can use the Tensorflow API v1. In this case, do not forget
+ to name your optimizers/operators. You can build a single operator from
+ multiple ones using the `tf.group` command, which also enable you to name
+ your new operator. For sequential nodes trigger (e.g. GANs), you can build
+ an operator that do what you want is the desired order using
+ `tf.control_dependancies()`.
+
diff --git a/doc/api_tutorial.md b/doc/api_tutorial.md
new file mode 100644
index 00000000..bcd6ea45
--- /dev/null
+++ b/doc/api_tutorial.md
@@ -0,0 +1,502 @@
+# Build and train deep learning models
+
+[Source code :fontawesome-brands-github:](https://github.com/remicres/otbtf/tree/master/otbtf/examples/tensorflow_v2x/fcnn){ .md-button }
+
+This section covers the use of the Python API with deep learnig models.
+It shows how to build and train a small fully convolutional model from patches
+extracted in the images. The example shows how a model can be trained (1) from
+**patches-images**, or (2) from **TFRecords** files.
+
+## Classes and files
+
+- **fcnn_model.py** implements a small fully convolutional U-Net like model,
+called `FCNNModel`, with the preprocessing and normalization functions that
+inherit from `otbtf.BaseModel`
+- **train_from_patches-images.py** shows how to train the model from a list of
+patches-images
+- **train_from_tfrecords.py** shows how to train the model from TFRecords files
+- **create_tfrecords.py** shows how to convert patch-images into TFRecords
+files
+- **helper.py** contains a few helping functions
+
+## Datasets
+
+Tensorflow datasets are the most practical way to feed a network data during
+training steps.
+In particular, they are very useful to train models with data parallelism using
+multiple workers (i.e. multiple GPU devices).
+Since OTBTF 3, two kind of approaches are available to deliver the patches:
+
+- Create TF datasets from **patches-images**: the first approach implemented in
+OTBTF, relying on geospatial raster formats supported by GDAL. Patches are
+stacked in rows. patches-images are friendly because they can be visualized
+like any other image. However this approach is **not very optimized**, since it
+generates a lot of I/O and stresses the filesystem when iterating randomly over
+patches.
+- Create TF datasets from **TFRecords** files. The principle is that a number of
+patches are stored in TFRecords files (google protobuf serialized data). This
+approach provides the best performances, since it generates less I/Os since
+multiple patches are read simultaneously together. It is the recommended approach
+to work on high end gear. It requires an additional step of converting the
+patches-images into TFRecords files.
+
+### Patches-images based datasets
+
+**Patches-images** are generated from the `PatchesExtraction` application of OTBTF.
+They consist in extracted patches stacked in rows into geospatial rasters.
+The `otbtf.DatasetFromPatchesImages` provides access to **patches-images** as a
+TF dataset. It inherits from the `otbtf.Dataset` class, which can be a base class
+to develop other raster based datasets.
+The `use_streaming` option can be used to read the patches on-the-fly
+on the filesystem. However, this can cause I/O bottleneck when one training step
+is shorter that fetching one batch of data. Typically, this is very common with
+small networks trained over large amount of data using multiple GPUs, causing the
+filesystem read operation being the weak point (and the GPUs wait for the batches
+to be ready). The class offers other functionalities, for instance changing the
+iterator class with a custom one (can inherit from `otbtf.dataset.IteratorBase`)
+which is, by default, an `otbtf.dataset.RandomIterator`. This could enable to
+control how the patches are walked, from the multiple patches-images of the
+dataset.
+
+Suppose you have extracted some patches with the `PatchesExtraction`
+application with 2 sources:
+
+ - Source "xs": patches images *xs_1.tif*, ..., *xs_N.tif*
+ - Source "labels": patches images *labels_1.tif*, ..., *labels_N.tif*
+
+To create a dataset from this set of patches can be done with
+`otbtf.DatasetFromPatchesImages` as shown below.
+
+```python
+dataset = DatasetFromPatchesImages(
+ filenames_dict={
+ "input_xs_patches": ["xs_1.tif", ..., "xs_N.tif"],
+ "labels_patches": ["labels_1.tif", ..., "labels_N.tif"]
+ }
+)
+```
+
+Getting the Tensorflow dataset is done doing:
+
+```python
+tf_dataset = dataset.get_tf_dataset(
+ batch_size=8,
+ targets_keys=["predictions"]
+)
+```
+
+Here the `targets_keys` list contains all the keys of the target tensors.
+We will explain later why this has to be specified.
+
+You can also convert the dataset into TFRecords files:
+
+```python
+tf_dataset.to_tfrecords(output_dir="/tmp/")
+```
+
+TFRecords are the subject of the next section!
+
+### TFRecords batches datasets
+
+**TFRecord** based datasets are implemented in the `otbtf.tfrecords` module.
+They basically deliver patches from the TFRecords files, which can be created
+with the `to_tfrecords()` method of the `otbtf.Dataset` based classes.
+Depending on the filesystem characteristics and the computational cost of one
+training step, it can be good to select the number of samples per TFRecords file.
+Another tweak is the shuffling: since one TFRecord file contains multiple patches,
+the way TFRecords files are accessed (sometimes, we need them to be randomly
+accessed), and the way patches are accessed (within a buffer, of size set with
+the `shuffle_buffer_size`), is crucial.
+
+Creating TFRecords based datasets is super easy:
+
+```python
+dataset = TFRecords("/tmp")
+tf_dataset = dataset.read(
+ shuffle_buffer_size=1000,
+ batch_size=8,
+ target_keys=["predictions"]
+)
+```
+
+## Model
+
+### Overview
+
+Let's define the setting for our model:
+
+```python
+# Number of classes estimated by the model
+N_CLASSES = 2
+
+# Name of the input
+INPUT_NAME = "input_xs"
+
+# Name of the target output
+TARGET_NAME = "predictions"
+
+# Name (prefix) of the output we will use at inference time
+OUTPUT_SOFTMAX_NAME = "predictions_softmax_tensor"
+```
+
+Our model estimates *2* classes. The input name is *input_xs*, and the
+target output is *predictions*. This target output will be used to compute
+the loss value, which is used ultimately to drive the learning of the
+network. The name of the output that we want to use at inference time is
+*predictions_softmax_tensor*. We won't use this tensor for anything else than
+inference.
+
+To build our model, we can build from scratch building on `tf.keras.Model`,
+but we will see how OTBTF helps a lot with the `otbtf.BaseModel` class.
+First, let's take a look to this schema:
+
+
+
+As we can see, we can distinguish two main functional blocks:
+
+- training
+- inference
+
+### Dataset transformation
+
+During training, we need to preprocess the samples generated by the dataset to
+feed the network and the loss computation, that will guide how weights will be
+updated. This **data transformation** is generally required to put the data
+in the format expected by the model.
+
+
+
+In our example, the terrain truth consists in labels which are integer values
+ranging from 0 to 1. However, the loss function that computes the cross
+entropy expects one hot encoding. The first thing to do is hence to transform
+the labels values into a one hot vector:
+
+```python
+def dataset_preprocessing_fn(examples: dict):
+ return {
+ INPUT_NAME: examples["input_xs_patches"],
+ TARGET_NAME: tf.one_hot(
+ tf.squeeze(tf.cast(examples["labels_patches"], tf.int32), axis=-1),
+ depth=N_CLASSES
+ )
+ }
+```
+
+As you can see, we don't modify the input tensor, since we want to use it
+as it in the model.
+
+### Model inputs preprocessing
+
+The model is intended to work on real world images, which have often 16 bits
+signed integers as pixel values. The model has to normalize these values such
+as they fit the [0, 1] range before applying the convolutions. This is called
+**normalization**.
+
+
+
+This is the purpose of `normalize_inputs()`, which has to be implemented as
+model method. The method inputs a dictionary of tensors, and returns a
+dictionary of normalized tensors. The transformation is done multiplying the
+input by 0.0001, which guarantee that the 12-bits encoded Spot-7 image pixels
+is in the [0, 1] range. Also, we cast the input tensor, which is originally of
+type integer, to floating point.
+
+```python
+class FCNNModel(ModelBase):
+ def normalize_inputs(self, inputs: dict):
+ return {INPUT_NAME: tf.cast(inputs[INPUT_NAME], tf.float32) * 0.0001}
+```
+
+### Network implementation
+
+Then we implement the model itself in `FCNNModel.get_outputs()`. The model
+must return a dictionary of tensors. All keys of the target tensors must be in
+the returned dictionary (in our case: the *predictions* tensor). These target
+keys will be used later by the optimizer to perform the optimization of the
+loss.
+
+
+
+Our model is built with an encoder composed of 4 downscaling convolutional
+blocks, and its mirrored reversed decoder with skip connections between the
+layers of same scale. The last layer is a softmax layer that estimates the
+probability distribution for each class, and its output is used to perform the
+computation of the cross entropy loss with the terrain truth one hot encoded
+labels. Its name is *predictions* so that the loss crosses the terrain truth
+and the estimated values.
+
+```python
+...
+ def get_outputs(self, normalized_inputs: dict) -> dict:
+
+ def _conv(inp, depth, name):
+ conv_op = tf.keras.layers.Conv2D(
+ filters=depth,
+ kernel_size=3,
+ strides=2,
+ activation="relu",
+ padding="same",
+ name=name
+ )
+ return conv_op(inp)
+
+ def _tconv(inp, depth, name, activation="relu"):
+ tconv_op = tf.keras.layers.Conv2DTranspose(
+ filters=depth,
+ kernel_size=3,
+ strides=2,
+ activation=activation,
+ padding="same",
+ name=name
+ )
+ return tconv_op(inp)
+
+ out_conv1 = _conv(normalized_inputs[INPUT_NAME], 16, "conv1")
+ out_conv2 = _conv(out_conv1, 32, "conv2")
+ out_conv3 = _conv(out_conv2, 64, "conv3")
+ out_conv4 = _conv(out_conv3, 64, "conv4")
+ out_tconv1 = _tconv(out_conv4, 64, "tconv1") + out_conv3
+ out_tconv2 = _tconv(out_tconv1, 32, "tconv2") + out_conv2
+ out_tconv3 = _tconv(out_tconv2, 16, "tconv3") + out_conv1
+ out_tconv4 = _tconv(out_tconv3, N_CLASSES, "classifier", None)
+
+ softmax_op = tf.keras.layers.Softmax(name=OUTPUT_SOFTMAX_NAME)
+ predictions = softmax_op(out_tconv4)
+
+ return {TARGET_NAME: predictions}
+
+```
+
+Now our model is complete.
+
+## Training, validation, and test
+
+In the following, we will use the Keras API using the `model.compile()` then
+`model.fit()` instructions.
+
+First we declare the strategy used. Here we chose
+`tf.distribute.MirroredStrategy` which enable to use multiple GPUs on one
+computing resource.
+
+```python
+strategy = tf.distribute.MirroredStrategy()
+```
+
+Then we instantiate, compile, and train the model within the `strategy` scope.
+
+First, we create an instance of our model:
+
+```python
+with strategy.scope():
+ model = FCNNModel(dataset_element_spec=ds_train.element_spec)
+```
+
+In all the following, we are still inside the `strategy` scope.
+After the model is instantiated, we compile it using:
+
+- a `tf.keras.losses.CategoricalCrossentropy` loss, that will compute the
+categorical cross-entropy between the target labels (delivered from the
+pre-processed dataset) and the target output returned from `get_output()` of
+our model
+- an Adam optimizer,
+- Precision and Recall metrics (respectively `tf.keras.metrics.Precision` and
+`tf.keras.metrics.Recall`), that will be later computed over the validation
+dataset
+
+```python
+ model.compile(
+ loss=tf.keras.losses.CategoricalCrossentropy(),
+ optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4),
+ metrics=[tf.keras.metrics.Precision(), tf.keras.metrics.Recall()]
+ )
+```
+
+We can then train our model using Keras:
+
+```python
+ model.fit(ds_train, epochs=100, validation_data=ds_valid)
+```
+
+At the end of the training (here we just perform 100 epochs over the training
+dataset, then stop), we could perform some evaluation over an additional test
+dataset:
+
+```python
+ model.evaluate(ds_test, batch_size=64)
+```
+
+Finally we can save our model as a SavedModel:
+
+```python
+ model.save("/tmp/my_1st_savedmodel")
+```
+
+## Inference
+
+This section show how to apply the fully convolutional model over an entire
+image.
+
+### Postprocessing to avoid blocking artifacts
+
+The class `otbtf.ModelBase` provides the necessary to enable fully
+convolutional models to be applied over large images, avoiding blocking
+artifacts caused by convolutions at the borders of tensors.
+`ModelBase` comes with a `postprocess_outputs()`, that process the outputs
+tensors returned by `get_outputs()`. This creates new outputs, aiming to be
+used at inference time. The default implementation of
+`ModelBase.postprocess_outputs()` avoids blocking artifacts, by keeping
+only the values of the central part of the tensors in spatial dimensions (you
+can read more on the subject in this
+[book](https://doi.org/10.1201/9781003020851)).
+
+If you take a look to
+[`ModelBase.__init__()`](reference/otbtf/model.html#otbtf.model.ModelBase.__init__)
+you can notice the `inference_cropping` parameter, with the default values
+set to [16, 32, 64, 96, 128]. Now if you take another look in
+[`ModelBase.postprocess_outputs()`](reference/otbtf/model.html#otbtf.model.ModelBase.postprocess_outputs),
+you can see how these values are used: the model will create an array of
+outputs, each one cropped to one value of `inference_cropping`. These cropped
+outputs enable to avoid or lower the magnitude of the blocking artifacts
+in convolutional models.
+The new outputs tensors are named by the
+[`cropped_tensor_name()`](reference/otbtf/model.html#otbtf.model.cropped_tensor_name)
+function, that returns a new name corresponding to:
+```python
+f"{tensor_name}_crop{crop}"
+```
+For instance, for the new output tensor created for *predictions*, that
+removes 32 pixels from the borders in the spatial dimensions, would be named
+***predictions_crop32***.
+
+### How to choose the right cropping value?
+
+Theoretically, we can determine the part of the output image that is not
+polluted by the convolutional padding.
+For a 2D convolution of stride \(s\) and kernel size \(k\), we can deduce the
+valid output size \(y\) from input size \(x\) using this expression:
+$$
+y = \left[\frac{x - k + 1}{s}\right]
+$$
+For a 2D transposed convolution of stride \(s\) and kernel size \(k\), we can
+deduce the valid output size \(y\) from input size \(x\) using this expression:
+$$
+y = (x * s) - k + 1
+$$
+
+Let's consider a chunk of input image of size 128, and check the valid output
+size of our model:
+
+| Conv. name | Conv. type | Kernel | Stride | Out. size | Valid out. size |
+|------------|-------------------|--------|--------|-----------|-----------------|
+| *conv1* | Conv2D | 3 | 2 | 64 | 63 |
+| *conv2* | Conv2D | 3 | 2 | 32 | 30 |
+| *conv3* | Conv2D | 3 | 2 | 16 | 14 |
+| *conv4* | Conv2D | 3 | 2 | 8 | 6 |
+| *tconv1* | Transposed Conv2D | 3 | 2 | 16 | 10 |
+| *tconv2* | Transposed Conv2D | 3 | 2 | 32 | 18 |
+| *tconv3* | Transposed Conv2D | 3 | 2 | 64 | 34 |
+
+This shows that our model can be applied in a fully convolutional fashion
+without generating blocking artifacts, using the central part of the output of
+size 34. This is equivalent to remove \((128 - 24)/2 = 47\) pixels from
+the borders of the output. We can hence use the output cropped with **64**
+pixels, named ***predictions_crop64***.
+
+!!! Info
+
+ Very deep networks will lead to very large cropping values.
+ In these cases, there is a tradeoff between numerical
+ exactness VS computational cost. In practice, expression field can be
+ ridiculously enlarged since most of the networks learn to disminish the
+ convolutional distortion at the border of the training patches.
+
+### TensorflowModelServe parameters
+
+We can use the exported SavedModel, located in */tmp/my_1st_savedmodel*, using
+either:
+
+- The OTB command line interface,
+- The OTB Python wrapper,
+- The PyOTB Python wrapper,
+- The OTB Graphical User Interface,
+- QGIS (you have to copy the descriptors of OTBTF applications in QGIS
+configuration folder).
+In the following, we focus only the CLI and python.
+
+In the following subsections, we run `TensorflowModelServe` over the input
+image, with the following parameters:
+
+- the input name is ***input_xs***
+- the output name is ***predictions_crop64*** (cropping margin of 64 pixels)
+- we choose a receptive field of ***256*** and an expression field of
+***128*** so that they match the cropping margin of 64 pixels.
+
+
+### Command Line Interface
+
+Open a terminal and run the following command:
+
+```commandline
+otbcli_TensorflowModelServe \
+-source1.il $DATADIR/fake_spot6.jp2 \
+-source1.rfieldx 256 \
+-source1.rfieldy 256 \
+-source1.placeholder "input_xs" \
+-model.dir /tmp/my_1st_savedmodel \
+-model.fullyconv on \
+-output.names "predictions_crop64" \
+-output.efieldx 128 \
+-output.efieldy 128 \
+-out softmax.tif
+```
+
+### OTB Python wrapper
+
+The previous command translates in the following in python, using the OTB
+python wrapper:
+
+```python
+import otbApplication
+app = otbApplication.Registry.CreateApplication("TensorflowModelServe")
+app.SetParameterStringList("source1.il", ["fake_spot6.jp2"])
+app.SetParameterInt("source1.rfieldx", 256)
+app.SetParameterInt("source1.rfieldy", 256)
+app.SetParameterString("source1.placeholder", "input_xs")
+app.SetParameterString("model.dir", "/tmp/my_1st_savedmodel")
+app.EnableParameter("fullyconv")
+app.SetParameterStringList("output.names", ["predictions_crop64"])
+app.SetParameterInt("output.efieldx", 128)
+app.SetParameterInt("output.efieldy", 128)
+app.SetParameterString("out", "softmax.tif")
+app.ExecuteAndWriteOutput()
+```
+
+### PyOTB
+
+Using PyOTB is nicer:
+
+```python
+import pyotb
+pyotb.TensorflowModelServe({
+ "source1.il": "fake_spot6.jp2",
+ "source1.rfieldx": 256,
+ "source1.rfieldy": 256,
+ "source1.placeholder": "input_xs",
+ "model.dir": "/tmp/my_1st_savedmodel",
+ "fullyconv": True,
+ "output.names": ["predictions_crop64"],
+ "output.efieldx": 128,
+ "output.efieldy": 128,
+ "out": "softmax.tif",
+})
+```
+
+!!! Note
+
+ The processing can be optimized using the `optim` parameters group.
+ In a terminal, type `otbcli_TensorflowModelServe --help optim` for more
+ information. Also, the extended filenames of the orfeo toolbox enables to
+ control the output image chunk size and tiling/stripping layout. Combined
+ with the `optim` parameters, you will likely always find the best settings
+ suited for the hardware. Also, the receptive and expression fields sizes
+ have a major contribution.
\ No newline at end of file
diff --git a/doc/app_inference.md b/doc/app_inference.md
new file mode 100644
index 00000000..d50a7c03
--- /dev/null
+++ b/doc/app_inference.md
@@ -0,0 +1,130 @@
+# Inference
+
+In OTBTF, the `TensorflowModelServe` performs the inference.
+The application can run models processing any kind or number of input images,
+as soon as they have geographical information and can be read with GDAL, which
+is the underlying library for IO in OTB.
+
+## Models information
+
+Models can be built using Tensorflow/Keras.
+They must be exported in **SavedModel** format.
+When using a model in OTBTF for inference, the following parameters must be
+known:
+
+- For each *input* (or *placeholder* for models built with Tensorflow API v1):
+ - Name
+ - Receptive field
+- For each *output tensor*:
+ - Name
+ - Expression field
+ - Scale factor
+
+
+
+The **scale factor** describes the physical change of spacing of the outputs,
+typically introduced in the model by non unitary strides in pooling or
+convolution operators.
+For each output, it is expressed relatively to one single input of the model
+called the *reference input source*.
+Additionally, the names of the *target nodes* must be known (e.g. optimizers
+for Tensorflow API v1).
+Also, the names of *user placeholders*, typically scalars inputs that are
+used to control some parameters of the model, must be know.
+The **receptive field** corresponds to the input volume that "sees" the deep
+net.
+The **expression field** corresponds to the output volume that the deep net
+will create.
+
+
+## TensorflowModelServe
+
+The `TensorflowModelServe` application performs the inference, it can be used
+to produce an output raster with the specified tensors.
+Thanks to the streaming mechanism, very large images can be produced.
+The application uses the `TensorflowModelFilter` and a `StreamingFilter` to
+force the streaming of output.
+This last can be optionally disabled by the user, if he prefers using the
+extended filenames to deal with chunk sizes.
+However, it's still very useful when the application is used in other
+composites applications, or just without extended filename magic.
+Some models can consume a lot of memory.
+In addition, the native tiling strategy of OTB consists in strips but this
+might not always the best.
+For Convolutional Neural Networks for instance, square tiles are more
+interesting because the padding required to perform the computation of one
+single strip of pixels induces to input a lot more pixels that to process the
+computation of one single tile of pixels.
+So, this application takes in input one or multiple _input sources_ (the number
+of _input sources_ can be changed by setting the `OTB_TF_NSOURCES` to the
+desired number) and produce one output of the specified tensors.
+The user is responsible of giving the **receptive field** and **name** of
+_input placeholders_, as well as the **expression field**, **scale factor** and
+**name** of _output tensors_.
+The first _input source_ (`source1.il`) corresponds to the _reference input
+source_.
+As explained, the **scale factor** provided for the
+_output tensors_ is related to this _reference input source_.
+The user can ask for multiple _output tensors_, that will be stack along the
+channel dimension of the output raster.
+
+!!! Warning
+
+ Multiple outputs names can be provided which results in stacked tensors in
+ the output image along the channels dimension. In this case, tensors must
+ have the same size in spatial dimension: if the sizes of _output tensors_
+ are not consistent (e.g. a different number of (x,y) elements), an
+ exception will be thrown.
+
+!!! Warning
+
+ If no output tensor name is specified, the application will try to grab
+ the first output tensor found in the SavedModel. This is okay with models
+ having a single output (see
+ [deterministic models section](reference/otbtf/examples/tensorflow_v2x/deterministic/__init__.html)).
+
+
+
+The application description can be displayed using:
+
+```commandline
+otbcli_TensorflowModelServe --help
+```
+
+## Composite applications for classification
+
+To use classic classifiers performing on a deep learning model features, one
+can use a traditional classifier generated from the
+`TrainClassifierFromDeepFeatures` application, in the
+`ImageClassifierFromDeepFeatures` application, which implements the same
+approach with the official OTB `ImageClassifier` application.
+
+The application description can be displayed using:
+
+```commandline
+otbcli_ImageClassifierFromDeepFeatures --help
+```
+
+!!! Note
+
+ You can still set the `OTB_TF_NSOURCES` environment variable to change the
+ number of sources.
+
+## Example
+
+We assume that we have already followed the
+[*training* section](app_training.html). We start from the files generated at
+the end of the training step.
+
+After this step, we use the trained model to produce the entire map of forest
+over the whole Spot-7 image.
+For this, we use the `TensorflowModelServe` application to produce the *
+*prediction** tensor output for the entire image.
+
+```commandLine
+otbcli_TensorflowModelServe -source1.il spot7.tif -source1.placeholder x1 \
+-source1.rfieldx 16 -source1.rfieldy 16 \
+-model.dir /path/to/oursavedmodel \
+-output.names prediction -out map.tif uint8
+```
+
diff --git a/doc/app_overview.md b/doc/app_overview.md
new file mode 100644
index 00000000..7961ca04
--- /dev/null
+++ b/doc/app_overview.md
@@ -0,0 +1,46 @@
+# Applications overview
+
+## Applications in OTB
+
+In OTB, applications are processes working on geospatial images, with a
+standardized interface. This interface enables the applications to be fully
+interoperable, and operated from various ways: C++, python, command line
+interface. The cool thing is that most of the applications support the
+so-called *streaming* mechanism that enable to process very large images with
+a limited memory footprint. Thanks to the interface shared by the OTB
+applications, we can use them as functional bricks to build large pipelines,
+that are memory and computationally efficient.
+
+!!! Info
+
+ As any OTB application, the new applications provided by OTBTF can be used
+ in command line interface, C++, or python.
+ For the best experience in python, we recommend to use OTB applications
+ using the excellent
+ [PyOTB](https://pyotb.readthedocs.io/en/master/quickstart.html).
+
+## New applications
+
+Here are the new applications provided by OTBTF.
+
+- **TensorflowModelServe**: Inference on real world remote sensing products
+- **PatchesExtraction**: extract patches in images
+- **PatchesSelection**: patches selection from rasters
+- **LabelImageSampleSelection**: select patches from a label image
+- **DensePolygonClassStatistics**: fast terrain truth polygons statistics
+- **TensorflowModelTrain**: training/validation (educational purpose)
+- **TrainClassifierFromDeepFeatures**: train traditional classifiers that use
+ features from deep nets (educational/experimental)
+- **ImageClassifierFromDeepFeatures**: use traditional classifiers with
+ features from deep nets (educational/experimental)
+
+Typically, you could build a pipeline like that without coding a single
+image process, only by using existing OTB applications, and bringing your own
+Tensorflow model inside (with the `TensorflowModelServe` application).
+
+
+
+The entire pipeline would be fully streamable, with a minimal memory footprint.
+Also, it should be noted that most OTB applications are multithreaded and
+benefit from multiple cores. Read more about streaming in OTB
+[here](https://www.orfeo-toolbox.org/CookBook/C++/StreamingAndThreading.html).
\ No newline at end of file
diff --git a/doc/app_sampling.md b/doc/app_sampling.md
new file mode 100644
index 00000000..b79ba7f4
--- /dev/null
+++ b/doc/app_sampling.md
@@ -0,0 +1,164 @@
+# Sampling applications
+
+OTBTF sampling applications are OTB applications that focus on the extraction
+of samples in the remote sensing images.
+
+Main OTBTF applications for sampling are:
+
+- [`PatchesSelection`](#patchesselection)
+- [`PatchesExtraction`](#patchesextraction)
+
+Other applications were written for experimental and educational purposes, but
+could still fill some needs sometimes:
+
+- [`DensePolygonClassStatistics`](#densepolygonclassstatistics)
+- [`LabelImageSampleSelection`](#labelimagesampleselection)
+
+## PatchesSelection
+
+This application generate points sampled at regular interval over the input
+image region. The selection strategy, patches grid size and step can be
+configured. The application produces a vector data containing a set of points
+centered on the patches after the selection process.
+
+The following strategies are implemented:
+
+- Split: the classic training/validation/testing samples split,
+- Chessboard: training/validation over the patches grid in a chessboard
+fashion
+- All: all patches are selected
+- Balanced: using an additional terrain truth labels map to select patches
+a random locations that try to balance the patches population distribution,
+based on the class value.
+
+The application description can be displayed using:
+
+```commandline
+otbcli_PatchesSelection --help
+```
+
+## PatchesExtraction
+
+The `PatchesExtraction` application performs the extraction of patches in
+images from the following:
+
+- a vector data containing points (mandatory)
+- at least one imagery source (mandatory). To change the number of sources,
+set the environment variable `OTB_TF_NSOURCES`
+- One exiting field name of the vector data to identify the different points.
+
+Each point of the vector data locates the **center** of the **central pixel**
+of one patch.
+For each source, the following parameters can be set:
+
+- the patch size (x and y): for patches with even size *N*, the **central
+pixel** corresponds to the pixel index *N/2+1* (index starting at 0).
+- a no-data value: If any pixel value inside the patch is equal to the
+provided value, the patch is rejected.
+- an output file name for the *patches image* that the application exports at
+the end of the sampling. Patches are stacked in rows and exported as common
+raster files supported by GDAL, without any geographical information.
+
+### Example with 2 sources
+
+We denote one _input source_, either an input image, or a stack of input images
+that will be concatenated (they must have the same size).
+The user can set the `OTB_TF_NSOURCES` environment variable to select the
+number of _input sources_ that he wants.
+For example, for sampling a Time Series (TS) together with a single Very High
+Resolution image (VHR), two sources are required:
+
+- 1 input images list for time series,
+- 1 input image for the VHR.
+
+The sampled patches are extracted at each position designed by the input
+vector data, only if a patch lies fully in all _input sources_ extents.
+For each _input source_, patches sizes must be provided.
+For each _input source_, the application export all sampled patches as a single
+multiband raster, stacked in rows.
+For instance, for *n* samples of size *16 x 16* from a *4* channels _input
+source_, the output image will be a raster of size *16 x 16n* with *4*
+channels.
+An optional output is an image of size *1 x n* containing the value of one
+specific field of the input vector data.
+Typically, the *class* field can be used to generate a dataset suitable for a
+model that performs pixel wise classification.
+
+
+
+The application description can be displayed using:
+
+```commandline
+otbcli_PatchesExtraction --help
+```
+
+
+## DensePolygonClassStatistics
+
+This application is a clone of the [`PolygonClassStatistics`](https://www.orfeo-toolbox.org/CookBook/Applications/app_PolygonClassStatistics.html)
+application from OTB modified to use rasterization instead of vector based
+approach, making it faster.
+
+The application description can be displayed using:
+
+```commandline
+otbcli_DensePolygonClassStatistics --help
+```
+
+## LabelImageSampleSelection
+
+This application extracts points from an input label image. This application
+is like `SampleSelection`, but uses an input label image, rather than an input
+vector data. It produces a vector data containing a set of points centered on
+the pixels of the input label image. The user can control the number of
+points. The default strategy consists in producing the same number of points
+in each class. If one class has a smaller number of points than requested,
+this one is adjusted.
+
+The application description can be displayed using:
+
+```commandline
+otbcli_LabelImageSampleSelection --help
+```
+
+## Example
+
+Below is a minimal example that presents some steps to sample patches from a
+sparse annotated vector data as terrain truth.
+Let's consider that our data set consists in one Spot-7 image, *spot7.tif*,
+and a training vector data, *terrain_truth.shp* that describes sparsely
+forest / non-forest polygons.
+
+First, we compute statistics of the vector data : how many points can we sample
+inside objects, and how many objects in each class.
+We use the `PolygonClassStatistics` application of OTB.
+
+```commandline
+otbcli_PolygonClassStatistics -vec terrain_truth.shp -field class \
+-in spot7.tif -out vec_stats.xml
+```
+
+Then, we will select some samples with the `SampleSelection` application of
+the existing machine learning framework of OTB.
+Since the terrain truth is sparse, we want to sample randomly points in
+polygons with the default strategy of the `SampleSelection` OTB application.
+
+```
+otbcli_SampleSelection -in spot7.tif -vec terrain_truth.shp \
+-instats vec_stats.xml -field class -out points.shp
+```
+
+Now we extract the patches with the `PatchesExtraction` application.
+We want to produce one image of 16x16 patches, and one image for the
+corresponding labels.
+
+```
+otbcli_PatchesExtraction -source1.il spot7.tif \
+-source1.patchsizex 16 -source1.patchsizey 16 \
+-vec points.shp -field class -source1.out samp_labels.tif \
+-outpatches samp_patches.tif
+```
+
+Now we can use the generated *samp_patches.tif* and *samp_labels.tif* in the
+`TensorflowModelTrain` application, or using the python API to build and train
+models with Keras.
\ No newline at end of file
diff --git a/doc/app_training.md b/doc/app_training.md
new file mode 100644
index 00000000..5ea6efaa
--- /dev/null
+++ b/doc/app_training.md
@@ -0,0 +1,114 @@
+!!! Warning
+
+ This section is for educational purposes. No coding skills are required,
+ and it's easy to train an existing model built with the Tensorflow API
+ v1. To have a full control over the model implementation and training
+ process, the Tensorflow API v2 with Keras is the way to go.
+ If you are interested in more similar examples, please read the
+ [Tensorflow v1 models examples](reference/otbtf/examples/tensorflow_v1x/__init__.md)
+
+## TensorflowModelTrain
+
+Here we assume that you have produced patches using the `PatchesExtraction`
+application, and that you have a **SavedModel** stored in a directory somewhere
+on your filesystem.
+The `TensorflowModelTrain` application performs the training, validation (
+against test dataset, and against validation dataset) providing the usual
+metrics that machine learning frameworks provide (confusion matrix, recall,
+precision, f-score, ...).
+You must provide the path of the **SavedModel** to the `model.dir` parameter.
+The `model.restorefrom` and `model.saveto` corresponds to the variables of the
+**SavedModel** used respectively for restoring and saving them.
+Set you _input sources_ for training (`training` parameter group) and for
+validation (`validation` parameter group): the evaluation is performed against
+training data, and optionally also against the validation data (only if you
+set `validation.mode` to "class").
+For each _input sources_, the patch size and the placeholder name must be
+provided.
+Regarding validation, if a different name is found in a particular _input
+source_ of the `validation` parameter group, the application knows that the
+_input source_ is not fed to the model at inference, but is used as reference
+to compute evaluation metrics of the validation dataset.
+Batch size (`training.batchsize`) and number of epochs (`training.epochs`) can
+be set.
+_User placeholders_ can be set separately for
+training (`training.userplaceholders`) and
+validation (`validation.userplaceholders`).
+The `validation.userplaceholders` can be useful if you have a model that
+behaves differently depending on the given placeholder.
+Let's take the example of dropout: it's nice for training, but you have to
+disable it to use the model at inference time.
+Hence you will pass a placeholder with "dropout\_rate=0.3" for training and "
+dropout\_rate=0.0" for validation.
+Of course, one can train models from handmade python code: to import the
+patches images, a convenient method consist in reading patches images as numpy
+arrays using OTB applications (e.g. `ExtractROI`) or GDAL, then do a
+`numpy.reshape` to the dimensions wanted.
+
+
+
+The application description can be displayed using:
+
+```commandLine
+otbcli_TensorflowModelTrain --help
+```
+
+As you can note, there is `$OTB_TF_NSOURCES` + 1 sources because we often need
+at least one more source for the reference data (e.g. terrain truth for land
+cover mapping).
+
+## Composite applications for classification
+
+Who has never dreamed to use classic classifiers performing on deep learning
+features?
+This is possible thank to two new applications that uses the existing
+training/classification applications of OTB:
+
+`TrainClassifierFromDeepFeatures` is a composite application that wire
+`TensorflowModelServe` application output into the existing official
+`TrainImagesClassifier` application.
+
+The application description can be displayed using:
+
+```commandLine
+otbcli_TrainClassifierFromDeepFeatures --help
+```
+
+## Example
+
+We assume that we have already followed the
+[*sampling* section](app_sampling.html). We start from the files generated at
+the end of the patches extraction.
+
+Now we have two images for patches and labels.
+We can split them to distinguish test/validation groups (with the `ExtractROI`
+ application for instance).
+But here, we will just perform some fine-tuning of our model.
+The **SavedModel** is located in the `outmodel` directory.
+Our model is quite basic: it has two input placeholders, **x1** and **y1**
+respectively for input patches (with size 16x16) and input reference labels (
+with size 1x1).
+We named **prediction** the tensor that predict the labels and the optimizer
+that perform the stochastic gradient descent is an operator named **optimizer
+**.
+We perform the fine-tuning and we export the new model variables directly in
+the _outmodel/variables_ folder, overwriting the existing variables of the
+model.
+We use the `TensorflowModelTrain` application to perform the training of this
+existing model.
+
+```
+otbcli_TensorflowModelTrain -model.dir /path/to/oursavedmodel \
+-training.targetnodesnames optimizer -training.source1.il samp_patches.tif \
+-training.source1.patchsizex 16 -training.source1.patchsizey 16 \
+-training.source1.placeholder x1 -training.source2.il samp_labels.tif \
+-training.source2.patchsizex 1 -training.source2.patchsizey 1 \
+-training.source2.placeholder y1 \
+-model.saveto /path/to/oursavedmodel/variables/variables
+```
+
+Note that we could also have performed validation in this step. In this case,
+the `validation.source2.placeholder` would be different than
+the `training.source2.placeholder`, and would be **prediction**. This way, the
+program know what is the target tensor to evaluate.
+
diff --git a/doc/HOWTOBUILD.md b/doc/build_from_sources.md
similarity index 68%
rename from doc/HOWTOBUILD.md
rename to doc/build_from_sources.md
index 82d3b115..e97d46cb 100644
--- a/doc/HOWTOBUILD.md
+++ b/doc/build_from_sources.md
@@ -1,9 +1,19 @@
-# How to build OTBTF from sources
+# Build OTBTF from sources
-This remote module has been tested successfully on Ubuntu 18 with last CUDA drivers, TensorFlow r2.1 and OTB 7.1.0.
+These instructions explain how to build on Ubuntu 18 with last CUDA
+drivers, TensorFlow r2.1 and OTB 7.1.0.
+
+!!! Warning
+
+ This section is no longer maintained.
+ You can take a look in the `Dockerfile` to take notes how it's done with
+ up-to-date ubuntu versions.
## Build OTB
-First, **build the *release-7.1* branch of OTB from sources**. You can check the [OTB documentation](https://www.orfeo-toolbox.org/SoftwareGuide/SoftwareGuidech2.html) which details all the steps. It is quite easy thank to the SuperBuild, a cmake script that automates the build.
+
+First, **build the *release-7.1* branch of OTB from sources**. You can check
+the [OTB documentation](https://www.orfeo-toolbox.org/SoftwareGuide/SoftwareGuidech2.html)
+which details all the steps. It is quite easy thank to the SuperBuild, a cmake script that automates the build.
Create a folder for OTB, clone sources, configure OTB SuperBuild, and build it.
@@ -12,7 +22,19 @@ Install required packages:
```
sudo apt-get update
sudo apt-get upgrade
-sudo apt-get install sudo ca-certificates curl make cmake g++ gcc git libtool swig xvfb wget autoconf automake pkg-config zip zlib1g-dev unzip freeglut3-dev libboost-date-time-dev libboost-filesystem-dev libboost-graph-dev libboost-program-options-dev libboost-system-dev libboost-thread-dev libcurl4-gnutls-dev libexpat1-dev libfftw3-dev libgdal-dev libgeotiff-dev libglew-dev libglfw3-dev libgsl-dev libinsighttoolkit4-dev libkml-dev libmuparser-dev libmuparserx-dev libopencv-core-dev libopencv-ml-dev libopenthreads-dev libossim-dev libpng-dev libqt5opengl5-dev libqwt-qt5-dev libsvm-dev libtinyxml-dev qtbase5-dev qttools5-dev default-jdk python3-pip python3.6-dev python3.6-gdal python3-setuptools libxmu-dev libxi-dev qttools5-dev-tools bison software-properties-common dirmngr apt-transport-https lsb-release gdal-bin
+sudo apt-get install sudo ca-certificates curl make cmake g++ gcc git \
+ libtool swig xvfb wget autoconf automake pkg-config zip zlib1g-dev \
+ unzip freeglut3-dev libboost-date-time-dev libboost-filesystem-dev \
+ libboost-graph-dev libboost-program-options-dev libboost-system-dev \
+ libboost-thread-dev libcurl4-gnutls-dev libexpat1-dev libfftw3-dev \
+ libgdal-dev libgeotiff-dev libglew-dev libglfw3-dev libgsl-dev \
+ libinsighttoolkit4-dev libkml-dev libmuparser-dev libmuparserx-dev \
+ libopencv-core-dev libopencv-ml-dev libopenthreads-dev libossim-dev \
+ libpng-dev libqt5opengl5-dev libqwt-qt5-dev libsvm-dev libtinyxml-dev \
+ qtbase5-dev qttools5-dev default-jdk python3-pip python3.6-dev \
+ python3.6-gdal python3-setuptools libxmu-dev libxi-dev \
+ qttools5-dev-tools bison software-properties-common dirmngr \
+ apt-transport-https lsb-release gdal-bin
```
Build OTB from sources:
@@ -23,7 +45,8 @@ sudo chown $USER /work
mkdir /work/otb
cd /work/otb
mkdir build
-git clone -b release-7.1 https://gitlab.orfeo-toolbox.org/orfeotoolbox/otb.git OTB
+git clone -b release-7.1 \
+ https://gitlab.orfeo-toolbox.org/orfeotoolbox/otb.git OTB
cd build
```
@@ -36,7 +59,16 @@ ccmake /work/otb/OTB/SuperBuild
If you don't know how to configure options, you can use the following:
```
-cmake /work/otb/OTB/SuperBuild -DUSE_SYSTEM_BOOST=ON -DUSE_SYSTEM_CURL=ON -DUSE_SYSTEM_EXPAT=ON -DUSE_SYSTEM_FFTW=ON -DUSE_SYSTEM_FREETYPE=ON -DUSE_SYSTEM_GDAL=ON -DUSE_SYSTEM_GEOS=ON -DUSE_SYSTEM_GEOTIFF=ON -DUSE_SYSTEM_GLEW=ON -DUSE_SYSTEM_GLFW=ON -DUSE_SYSTEM_GLUT=ON -DUSE_SYSTEM_GSL=ON -DUSE_SYSTEM_ITK=ON -DUSE_SYSTEM_LIBKML=ON -DUSE_SYSTEM_LIBSVM=ON -DUSE_SYSTEM_MUPARSER=ON -DUSE_SYSTEM_MUPARSERX=ON -DUSE_SYSTEM_OPENCV=ON -DUSE_SYSTEM_OPENTHREADS=ON -DUSE_SYSTEM_OSSIM=ON -DUSE_SYSTEM_PNG=ON -DUSE_SYSTEM_QT5=ON -DUSE_SYSTEM_QWT=ON -DUSE_SYSTEM_TINYXML=ON -DUSE_SYSTEM_ZLIB=ON -DUSE_SYSTEM_SWIG=OFF -DOTB_WRAP_PYTHON=OFF
+cmake /work/otb/OTB/SuperBuild -DUSE_SYSTEM_BOOST=ON -DUSE_SYSTEM_CURL=ON \
+ -DUSE_SYSTEM_EXPAT=ON -DUSE_SYSTEM_FFTW=ON -DUSE_SYSTEM_FREETYPE=ON \
+ -DUSE_SYSTEM_GDAL=ON -DUSE_SYSTEM_GEOS=ON -DUSE_SYSTEM_GEOTIFF=ON \
+ -DUSE_SYSTEM_GLEW=ON -DUSE_SYSTEM_GLFW=ON -DUSE_SYSTEM_GLUT=ON \
+ -DUSE_SYSTEM_GSL=ON -DUSE_SYSTEM_ITK=ON -DUSE_SYSTEM_LIBKML=ON \
+ -DUSE_SYSTEM_LIBSVM=ON -DUSE_SYSTEM_MUPARSER=ON \
+ -DUSE_SYSTEM_MUPARSERX=ON -DUSE_SYSTEM_OPENCV=ON \
+ -DUSE_SYSTEM_OPENTHREADS=ON -DUSE_SYSTEM_OSSIM=ON -DUSE_SYSTEM_PNG=ON \
+ -DUSE_SYSTEM_QT5=ON -DUSE_SYSTEM_QWT=ON -DUSE_SYSTEM_TINYXML=ON \
+ -DUSE_SYSTEM_ZLIB=ON -DUSE_SYSTEM_SWIG=OFF -DOTB_WRAP_PYTHON=OFF
```
Then you can build OTB:
@@ -45,7 +77,10 @@ make -j $(grep -c ^processor /proc/cpuinfo)
```
## Build TensorFlow with shared libraries
-During this step, you have to **build Tensorflow from source** except if you want to use only the sampling applications of OTBTensorflow (in this case, skip this section).
+
+During this step, you have to **build Tensorflow from source** except if you
+want to use only the sampling applications of OTBTensorflow (in this case,
+skip this section).
### Bazel
First, install Bazel.
@@ -56,7 +91,9 @@ chmod +x bazel-0.29.1-installer-linux-x86_64.sh
export PATH="$PATH:$HOME/bin"
```
-If you fail to install properly Bazel, you can read the beginning of [the instructions](https://www.tensorflow.org/install/install_sources) that present alternative methods for this.
+If you fail to install properly Bazel, you can read the beginning of
+[the instructions](https://www.tensorflow.org/install/install_sources) that
+present alternative methods for this.
### Required packages
There is a few required packages that you need to install:
@@ -65,7 +102,9 @@ sudo python3 -m pip install --upgrade pip
sudo python3 -m pip install pip six numpy wheel mock keras future setuptools
```
-For a pure python3 install, you might need to workaround a bazel bug the following way:
+For a pure python3 install, you might need to workaround a bazel bug the
+following way:
+
```
sudo ln -s /usr/bin/python3 /usr/bin/python
```
@@ -80,24 +119,36 @@ cd /work/tf
git clone https://github.com/tensorflow/tensorflow.git
```
-Now configure the project. If you have CUDA and other NVIDIA stuff installed in your system, remember that you have to tell the script that it is in `/usr/` (no symlink required!). If you have CPU-only hardware, building Intel MKL is a good choice since it provides a significant speedup in computations.
+Now configure the project. If you have CUDA and other NVIDIA stuff installed
+in your system, remember that you have to tell the script that it is in
+`/usr/` (no symlink required!). If you have CPU-only hardware, building Intel
+MKL is a good choice since it provides a significant speedup in computations.
```
cd tensorflow
./configure
```
-Then, you have to build TensorFlow with the instructions sets supported by your CPU (For instance here is AVX, AVX2, FMA, SSE4.1, SSE4.2 that play fine on a modern intel CPU). You have to tell Bazel to build:
+Then, you have to build TensorFlow with the instructions sets supported by
+your CPU (For instance here is AVX, AVX2, FMA, SSE4.1, SSE4.2 that play fine
+on a modern intel CPU). You have to tell Bazel to build:
1. The TensorFlow python pip package
- 2. The libtensorflow_cc.so library
- 3. The libtensorflow_framework.so library
+ 2. The *libtensorflow_cc.so* library
+ 3. The *libtensorflow_framework.so* library
```
-bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both --copt=-msse4.1 --copt=-msse4.2 //tensorflow:libtensorflow_framework.so //tensorflow:libtensorflow_cc.so //tensorflow:libtensorflow.so //tensorflow/tools/pip_package:build_pip_package --noincompatible_do_not_split_linking_cmdline
+bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma \
+ --copt=-mfpmath=both --copt=-msse4.1 --copt=-msse4.2 \
+ //tensorflow:libtensorflow_framework.so \
+ //tensorflow:libtensorflow_cc.so //tensorflow:libtensorflow.so \
+ //tensorflow/tools/pip_package:build_pip_package \
+ --noincompatible_do_not_split_linking_cmdline
```
-*You might fail this step (e.g. missing packages). In this case, it's recommended to clear the bazel cache, using something like `rm $HOME/.cache/bazel/* -rf` before configuring and building everything!*
+*You might fail this step (e.g. missing packages). In this case, it's
+recommended to clear the bazel cache, using something like
+`rm $HOME/.cache/bazel/* -rf` before configuring and building everything!*
### Pip package
Build and deploy the pip package.
@@ -143,17 +194,21 @@ cp -r bazel-tensorflow/external/eigen_archive/Eigen /work/tf/installdir/include
cp -r tensorflow/lite/tools/make/downloads/absl/absl /work/tf/installdir/include
```
-Now you have a working copy of TensorFlow located in `/work/tf/installdir` that is ready to use in external C++ cmake projects :)
+Now you have a working copy of TensorFlow located in `/work/tf/installdir`
+that is ready to use in external C++ cmake projects :)
## Build the OTBTF remote module
Finally, we can build the OTBTF module.
-Clone the repository inside the OTB sources directory for remote modules: `/work/otb/OTB/Modules/Remote/`.
+Clone the repository inside the OTB sources directory for remote modules:
+`/work/otb/OTB/Modules/Remote/`.
Re configure OTB with cmake of ccmake, and set the following variables
- **Module_OTBTensorflow** to **ON**
- - **OTB_USE_TENSORFLOW** to **ON** (if you set to OFF, you will have only the sampling applications)
+ - **OTB_USE_TENSORFLOW** to **ON** (if you set to OFF, you will have only
+ the sampling applications)
- **TENSORFLOW_CC_LIB** to `/work/tf/installdir/lib/libtensorflow_cc.so`
- - **TENSORFLOW_FRAMEWORK_LIB** to `/work/tf/installdir/lib/libtensorflow_framework.so`
+ - **TENSORFLOW_FRAMEWORK_LIB** to
+ `/work/tf/installdir/lib/libtensorflow_framework.so`
- **tensorflow_include_dir** to `/work/tf/installdir/include`
Re build and re install OTB.
diff --git a/doc/deprecated.md b/doc/deprecated.md
new file mode 100644
index 00000000..c0477962
--- /dev/null
+++ b/doc/deprecated.md
@@ -0,0 +1,38 @@
+!!! Warning
+
+ The `tricks` module is deprecated since OTBTF 2.0
+
+The Tensorflow python API has changed significantly (for the best) after the
+Tensorflow 2.0 release. OTBTF used to provide the `tricks` module, providing
+useful methods to generate the SavedModels, or convert checkpoints into
+SavedModels.
+
+[Source code :fontawesome-brands-github:](https://github.com/remicres/otbtf/tree/master/otbtf/tricks/){ .md-button }
+
+## What is best in Tensorflow 2.X?
+
+- Shorter and simpler code
+- Easy to build and train a model with Keras, which has become the principal
+interface for Tensorflow
+- More hardware-agnostic than ever: with the exact same code, you can run on
+a single-cpu, GPU, or a pool of GPU servers.
+
+## Major changes between Tensorflow 1 and Tensorflow 2 APIs
+
+Here are a few tips and tricks for people that want to move from
+Tensorflow 1 to Tensorflow 2 API.
+Models built for OTBTF have to take in account the following changes:
+
+- Models built with `otbtf.ModelBase` or `tensorflow.keras.model.Model` have
+no longer to use `tensorflow.compat.v1.placeholder` but
+`tensorflow.keras.Input` instead,
+- Tensorflow variable scopes are no longer used when the training is done from
+Keras,
+- SavedModel can be created directly from the model instance! (as simple as
+`mymodel.save("mymodel_v1_savedmode")`),
+- Switching between single cpu/gpu or multiple computing nodes, distributed
+training, etc. is done using the so-called `tensorflow.Strategy`
+
+!!! Note
+
+ Read our [tutorial](#api_tutorial.html) to know more on working with Keras!
\ No newline at end of file
diff --git a/doc/doc_requirements.txt b/doc/doc_requirements.txt
new file mode 100644
index 00000000..e5740205
--- /dev/null
+++ b/doc/doc_requirements.txt
@@ -0,0 +1,8 @@
+mkdocstrings
+mkdocstrings[crystal,python]
+mkdocs-material
+mkdocs-gen-files
+mkdocs-section-index
+mkdocs-literate-nav
+mkdocs-mermaid2-plugin
+python-markdown-math
diff --git a/doc/docker_build.md b/doc/docker_build.md
new file mode 100644
index 00000000..c7a3c1e9
--- /dev/null
+++ b/doc/docker_build.md
@@ -0,0 +1,211 @@
+# Build your own docker images
+
+Docker build has to be called from the root of the repository (i.e. `docker
+build .` or `bash tools/docker/multibuild.sh`).
+You can build a custom image using `--build-arg` and several config files :
+
+- **Ubuntu** : `BASE_IMG` should accept any version, for additional packages
+see *tools/docker/build-deps-cli.txt* and *tools/docker/build-deps-gui.txt*.
+- **TensorFlow** : `TF` arg for the git branch or tag + *build-env-tf.sh* and
+BZL_* arguments for the build configuration. `ZIP_TF_BIN` allows you to save
+compiled binaries if you want to install it elsewhere.
+- **OrfeoToolBox** : `OTB` arg for the git branch or tag +
+*tools/docker/build-flags-otb.txt* to edit cmake flags. Set `KEEP_SRC_OTB` in
+order to preserve OTB git directory.
+
+### Base images
+
+```bash
+CPU_IMG=ubuntu:22.04
+GPU_IMG=nvidia/cuda:12.1.0-devel-ubuntu22.04
+```
+
+### Default arguments
+
+```bash
+BASE_IMG # mandatory
+CPU_RATIO=1
+GUI=false
+NUMPY_SPEC="==1.19.*"
+TF=v2.12.0
+OTB=8.1.0
+BZL_TARGETS="//tensorflow:libtensorflow_cc.so //tensorflow/tools/pip_package:build_pip_package"
+BZL_CONFIGS="--config=nogcp --config=noaws --config=nohdfs --config=opt"
+BZL_OPTIONS="--verbose_failures --remote_cache=http://localhost:9090"
+ZIP_TF_BIN=false
+KEEP_SRC_OTB=false
+SUDO=true
+
+# NumPy version requirement :
+# TF < 2.4 : "numpy<1.19.0,>=1.16.0"
+# TF >= 2.4 : "numpy==1.19.*"
+# TF >= 2.8 : "numpy==1.22.*"
+```
+
+### Bazel remote cache daemon
+
+If you just need to rebuild with different GUI or KEEP_SRC arguments, or may
+be a different branch of OTB, bazel cache will help you to rebuild everything
+except TF, even if the docker cache was purged (after `docker
+[system|builder] prune`).
+In order to recycle the cache, bazel config and TF git tag should be exactly
+the same, any change in [build-env-tf.sh](build-env-tf.sh) and `--build-arg`
+(if related to bazel env, cuda, mkl, xla...) may result in a fresh new build.
+
+Start a cache daemon - here with max 20GB but 10GB should be enough to save 2
+TF builds (GPU and CPU):
+
+```bash
+mkdir -p $HOME/.cache/bazel-remote
+docker run --detach -u 1000:1000 -v $HOME/.cache/bazel-remote:/data \
+ -p 9090:8080 buchgr/bazel-remote-cache --max_size=20
+```
+
+Then just add ` --network='host'` to the docker build command, or connect
+bazel to a remote server - see 'BZL_OPTIONS'.
+The other way of docker is a virtual bridge, but you'll need to edit the IP
+address.
+
+## Images build examples
+
+```bash
+# Build for CPU using default Dockerfiles args (without AWS, HDFS or GCP
+# support)
+docker build --network='host' -t otbtf:cpu --build-arg BASE_IMG=ubuntu:22.04 .
+
+# Clear bazel config var (deactivate default optimizations and unset
+# noaws/nogcp/nohdfs)
+docker build --network='host' -t otbtf:cpu \
+ --build-arg BASE_IMG=ubuntu:22.04 \
+ --build-arg BZL_CONFIGS= .
+
+# Enable MKL
+MKL_CONFIG="--config=nogcp --config=noaws --config=nohdfs --config=opt --config=mkl"
+docker build --network='host' -t otbtf:cpu-mkl \
+ --build-arg BZL_CONFIGS="$MKL_CONFIG" \
+ --build-arg BASE_IMG=ubuntu:22.04 .
+
+# Build for GPU (if you're building for your system only you should edit
+# CUDA_COMPUTE_CAPABILITIES in build-env-tf.sh)
+docker build --network='host' -t otbtf:gpu \
+ --build-arg BASE_IMG=nvidia/cuda:12.1.0-devel-ubuntu22.04 .
+
+# Build latest TF and OTB, set git branches/tags to clone
+docker build --network='host' -t otbtf:gpu-dev \
+ --build-arg BASE_IMG=nvidia/cuda:12.1.0-devel-ubuntu22.04 \
+ --build-arg KEEP_SRC_OTB=true \
+ --build-arg TF=nightly \
+ --build-arg OTB=develop .
+
+# Build old release (TF-2.1)
+docker build --network='host' -t otbtf:oldstable-gpu \
+ --build-arg BASE_IMG=nvidia/cuda:10.1-cudnn7-devel-ubuntu18.04 \
+ --build-arg TF=r2.1 \
+ --build-arg NUMPY_SPEC="<1.19" \
+ --build-arg BAZEL_OPTIONS="--noincompatible_do_not_split_linking_cmdline --verbose_failures --remote_cache=http://localhost:9090" .
+# You could edit the Dockerfile in order to clone an old branch of the repo
+# instead of copying files from the build context
+```
+
+### Build for another machine and save TF compiled files
+
+Example with TF 2.5
+
+```bash
+# Use same ubuntu and CUDA version than your target machine, beware of CC
+# optimization and CPU compatibility (set env variable CC_OPT_FLAGS and avoid
+# "-march=native" if your Docker's CPU is optimized with AVX2/AVX512 but your
+# target CPU isn't)
+docker build --network='host' -t otbtf:custom \
+ --build-arg BASE_IMG=nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04 \
+ --build-arg TF=v2.5.0 \
+ --build-arg ZIP_TF_BIN=true .
+# Retrieve zip file
+docker run -v $HOME:/home/otbuser/volume otbtf:custom \
+ cp /opt/otbtf/tf-v2.5.0.zip /home/otbuser/volume
+
+# Target machine shell
+cd $HOME
+unzip tf-v2.5.0.zip
+sudo mkdir -p /opt/tensorflow/lib
+sudo mv tf-v2.5.0/libtensorflow_cc* /opt/tensorflow/lib
+# You may need to create a virtualenv, here TF and dependencies are installed
+# next to user's pip packages
+pip3 install -U pip wheel mock six future deprecated "numpy==1.19.*"
+pip3 install --no-deps keras_applications keras_preprocessing
+pip3 install tf-v2.5.0/tensorflow-2.5.0-cp38-cp38-linux_x86_64.whl
+
+TF_WHEEL_DIR="$HOME/.local/lib/python3.8/site-packages/tensorflow"
+# If you installed the wheel as regular user, with root pip it should be in
+# /usr/local/lib/python3.*, or in your virtualenv lib/ directory
+mv tf-v2.5.0/tag_constants.h $TF_WHEEL_DIR/include/tensorflow/cc/saved_model/
+# Then recompile OTB with OTBTF using libraries in /opt/tensorflow/lib and
+# instructions in build_from_sources.md.
+cmake $OTB_GIT \
+ -DOTB_USE_TENSORFLOW=ON -DModule_OTBTensorflow=ON \
+ -DTENSORFLOW_CC_LIB=/opt/tensorflow/lib/libtensorflow_cc.so.2 \
+ -Dtensorflow_include_dir=$TF_WHEEL_DIR/include \
+ -DTENSORFLOW_FRAMEWORK_LIB=$TF_WHEEL_DIR/libtensorflow_framework.so.2 \
+&& make install -j
+```
+
+### Debug build
+
+If you fail to build, you can log into the last layer and check CMake logs.
+Run `docker images`, find the latest layer ID and run a tmp container
+(`docker run -it d60496d9612e bash`).
+You may also need to split some multi-command layers in the Dockerfile.
+If you see OOM errors during SuperBuild you should decrease CPU_RATIO (e.g.
+0.75).
+
+## Container examples
+
+```bash
+# Pull GPU image and create a new container with your home directory as volume
+# (requires apt package nvidia-docker2 and CUDA>=11.0)
+docker create --gpus=all --volume $HOME:/home/otbuser/volume -it \
+ --name otbtf-gpu mdl4eo/otbtf:3.3.2-gpu
+
+# Run interactive
+docker start -i otbtf-gpu
+
+# Run in background
+docker start otbtf-gpu
+docker exec otbtf-gpu \
+ python -c 'import tensorflow as tf; print(tf.test.is_gpu_available())'
+```
+
+### Rebuild OTB with more modules
+
+Enter a development ready docker image:
+
+```bash
+docker create --gpus=all -it --name otbtf-gpu-dev mdl4eo/otbtf:3.3.2-gpu-dev
+docker start -i otbtf-gpu-dev
+```
+
+Then, from the container shell:
+
+```bash
+sudo -i
+cd /src/otb/otb/Modules/Remote
+git clone https://gitlab.irstea.fr/raffaele.gaetano/otbSelectiveHaralickTextures.git
+cd /src/otb/build/OTB/build
+cmake -DModule_OTBAppSelectiveHaralickTextures=ON /src/otb/otb && make install -j
+```
+
+### Container with GUI
+
+GUI is disabled by default in order to save space, and because docker xvfb
+isn't working properly with OpenGL.
+OTB GUI seems OK but monteverdi isn't working
+
+```bash
+docker build --network='host' -t otbtf:cpu-gui \
+ --build-arg BASE_IMG=ubuntu:22.04 \
+ --build-arg GUI=true .
+docker create -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -it \
+ --name otbtf-gui otbtf:cpu-gui
+docker start -i otbtf-gui
+$ mapla
+```
diff --git a/doc/docker_troubleshooting.md b/doc/docker_troubleshooting.md
new file mode 100644
index 00000000..c34b7d2d
--- /dev/null
+++ b/doc/docker_troubleshooting.md
@@ -0,0 +1,201 @@
+# Docker troubleshooting
+
+You can find plenty of help on the web about docker.
+This section only provides the basics for newcomers that are eager to use
+OTBTF!
+This section is largely inspired from the
+[moringa docker help](https://gitlab.irstea.fr/raffaele.gaetano/moringa/blob/develop/docker/README.md).
+Big thanks to the authors.
+
+## Common errors
+
+### Manifest unknown
+
+```
+Error response from daemon:
+manifest for nvidia/cuda:11.0-cudnn8-devel-ubuntu20.04 not found:
+manifest unknown: manifest unknown
+```
+
+This means that the docker image is missing from dockerhub.
+
+### failed call to cuInit
+
+```
+failed call to cuInit:
+UNKNOWN ERROR (303) / no NVIDIA GPU device is present:
+/dev/nvidia0 does not exist
+```
+
+Nvidia driver is missing or disabled, make sure to add
+` --gpus=all` to your docker run or create command
+
+## Useful diagnostic commands
+
+Here are some useful commands.
+
+```bash
+docker info # System info
+docker images # List local images
+docker container ls # List containers
+docker ps # Show running containers
+```
+
+On Linux, control state with `service`:
+
+```bash
+sudo service docker {status,enable,disable,start,stop,restart}
+```
+
+### Run some commands
+
+Run a simple command in a one-shot container:
+
+```bash
+docker run mdl4eo/otbtf:3.4.0-cpu otbcli_PatchesExtraction
+```
+
+You can also use the image in interactive mode with bash:
+
+```bash
+docker run -ti mdl4eo/otbtf:3.4.0-cpu bash
+```
+
+### Mounting file systems
+
+You can mount filesystem in the docker image.
+For instance, suppose you have some data in `/mnt/disk1/` that you want
+to use inside the container:
+
+The following command shows you how to access the folder from the docker image.
+
+```bash
+docker run -v /mnt/disk1/:/data/ -ti mdl4eo/otbtf:3.4.0-cpu bash -c "ls /data"
+```
+Beware of ownership issues! see the last section of this doc.
+
+### Persistent container
+
+Persistent (named) container with volume, here with home dir, but it can be
+any directory.
+
+```bash
+docker create --interactive --tty --volume /home/$USER:/home/otbuser/ \
+ --name otbtf mdl4eo/otbtf:3.4.0-cpu /bin/bash
+```
+
+!!! warning
+
+ Beware of ownership issues, see
+ [this section](#fix-volume-ownership-sissues).
+
+### Interactive session
+
+```bash
+docker start -i otbtf
+```
+
+### Background container
+
+```bash
+docker start otbtf
+docker exec otbtf ls -alh
+docker stop otbtf
+```
+
+### Running commands with root user
+
+Background container is one easy way:
+
+```bash
+docker start otbtf
+# Example with apt update
+# (you can't use &&, one docker exec is
+# required for each command)
+docker exec --user root otbtf apt-get update
+docker exec --user root otbtf apt-get upgrade -y
+```
+
+### Container-specific commands, especially for background containers:
+
+```bash
+docker inspect otbtf # See full container info dump
+docker logs otbtf # See command logs and outputs
+docker stats otbtf # Real time container statistics
+docker {pause,unpause} otbtf # Freeze container
+```
+
+### Stop a background container
+
+Don't forget to stop the container after you have done.
+
+```bash
+docker stop otbtf
+```
+
+### Remove a persistent container
+
+```bash
+docker rm otbtf
+```
+
+## Fix volume ownership issues
+
+Generally, this is required if host's UID > 1000.
+
+When mounting a volume, you may experience errors while trying to write files
+from within the container.
+Since the default user (**otbuser**) is UID 1000, you won't be able to write
+files into your volume
+which is mounted with the same UID than your linux host user (may be UID 1001
+or more).
+In order to address this, you need to edit the container's user UID and GID to
+match the right numerical value.
+This will only persist in a named container, it is required every time you're
+creating a new one.
+
+
+Create a named container (here with your HOME as volume), Docker will
+automatically pull image
+
+```bash
+docker create --interactive --tty --volume /home/$USER:/home/otbuser \
+ --name otbtf mdl4eo/otbtf:3.4.0-cpu /bin/bash
+```
+
+Start a background container process:
+
+```bash
+docker start otbtf
+```
+
+Exec required commands with user root (here with host's ID, replace $UID and
+$GID with desired values):
+
+```bash
+docker exec --user root otbtf usermod otbuser -u $UID
+docker exec --user root otbtf groupmod otbuser -g $GID
+```
+
+Force reset ownership with updated UID and GID.
+Make sure to double check that `docker exec otbtf id` because recursive chown
+will apply to your volume in `/home/otbuser`
+
+```bash
+docker exec --user root otbtf chown -R otbuser:otbuser /home/otbuser
+```
+
+Stop the background container and start a new interactive shell:
+
+```bash
+docker stop otbtf
+docker start -i otbtf
+```
+
+Check if ownership is right
+
+```bash
+id
+ls -Alh /home/otbuser
+touch /home/otbuser/test.txt
+```
diff --git a/doc/DOCKERUSE.md b/doc/docker_use.md
similarity index 63%
rename from doc/DOCKERUSE.md
rename to doc/docker_use.md
index 4c92b614..ba3c083d 100644
--- a/doc/DOCKERUSE.md
+++ b/doc/docker_use.md
@@ -1,241 +1,110 @@
-# OTBTF docker images overview
+# Install from docker
-### Available images
+We recommend to use OTBTF from official docker images.
-Here is the list of the latest OTBTF docker images hosted on [dockerhub](https://hub.docker.com/u/mdl4eo).
-Since OTBTF >= 3.2.1 you can find latest docker images on [gitlab.irstea.fr](https://gitlab.irstea.fr/remi.cresson/otbtf/container_registry).
+Latest CPU-only docker image:
-| Name | Os | TF | OTB | Description | Dev files | Compute capability |
-|------------------------------------------------------------------------------------| ------------- | ------ |-------| ---------------------- | --------- | ------------------ |
-| **mdl4eo/otbtf:3.4.0-cpu** | Ubuntu Focal | r2.8 | 8.1.0 | CPU, no optimization | no | 5.2,6.1,7.0,7.5,8.6|
-| **mdl4eo/otbtf:3.4.0-cpu-dev** | Ubuntu Focal | r2.8 | 8.1.0 | CPU, no optimization (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
-| **mdl4eo/otbtf:3.4.0-gpu** | Ubuntu Focal | r2.8 | 8.1.0 | GPU, no optimization | no | 5.2,6.1,7.0,7.5,8.6|
-| **mdl4eo/otbtf:3.4.0-gpu-dev** | Ubuntu Focal | r2.8 | 8.1.0 | GPU, no optimization (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
-| **gitlab.irstea.fr/remi.cresson/otbtf/container_registry/otbtf:3.4.0-gpu-opt** | Ubuntu Focal | r2.8 | 8.1.0 | GPU with opt. | no | 5.2,6.1,7.0,7.5,8.6|
-| **gitlab.irstea.fr/remi.cresson/otbtf/container_registry/otbtf:3.4.0-gpu-opt-dev** | Ubuntu Focal | r2.8 | 8.1.0 | GPU with opt. (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
-
-The list of older releases is available [here](#older-docker-releases).
-
-You can also find more interesting OTBTF flavored images at [LaTelescop gitlab registry](https://gitlab.com/latelescop/docker/otbtf/container_registry/).
+```commandline
+docker pull mdl4eo/otbtf:4.0.0-cpu
+```
+Latest GPU-ready docker image:
-### Development ready images
+```commandline
+docker pull mdl4eo/otbtf:4.0.0-gpu
+```
-Until r2.4, all images are development-ready, and the sources are located in `/work/`.
-Since r2.4, development-ready images have the source in `/src/`.
+Read more in the following sections.
-### Build your own images
+## Latest images
-If you want to use optimization flags, change GPUs compute capability, etc. you can build your own docker image using the provided dockerfile.
-See the [docker build documentation](../tools/docker/README.md).
+Here is the list of the latest OTBTF docker images hosted on
+[dockerhub](https://hub.docker.com/u/mdl4eo).
+Since OTBTF >= 3.2.1 you can find the latest docker images on
+[gitlab.irstea.fr](https://gitlab.irstea.fr/remi.cresson/otbtf/container_registry).
-# Mounting file systems
+| Name | Os | TF | OTB | Description | Dev files | Compute capability |
+|------------------------------------------------------------------------------------| ------------- |-------|-------| ---------------------- | --------- | ------------------ |
+| **mdl4eo/otbtf:4.0.0-cpu** | Ubuntu Focal | r2.12 | 8.1.0 | CPU, no optimization | no | 5.2,6.1,7.0,7.5,8.6|
+| **mdl4eo/otbtf:4.0.0-cpu-dev** | Ubuntu Focal | r2.12 | 8.1.0 | CPU, no optimization (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
+| **mdl4eo/otbtf:4.0.0-gpu** | Ubuntu Focal | r2.12 | 8.1.0 | GPU, no optimization | no | 5.2,6.1,7.0,7.5,8.6|
+| **mdl4eo/otbtf:4.0.0-gpu-dev** | Ubuntu Focal | r2.12 | 8.1.0 | GPU, no optimization (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
+| **gitlab.irstea.fr/remi.cresson/otbtf/container_registry/otbtf:4.0.0-gpu-opt** | Ubuntu Focal | r2.12 | 8.1.0 | GPU with opt. | no | 5.2,6.1,7.0,7.5,8.6|
+| **gitlab.irstea.fr/remi.cresson/otbtf/container_registry/otbtf:4.0.0-gpu-opt-dev** | Ubuntu Focal | r2.12 | 8.1.0 | GPU with opt. (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
-You can mount filesystem in the docker image.
-For instance, suppose you have some data in `/mnt/my_device/` that you want to use inside the container:
+The list of older releases is available [here](#older-images).
-The following command shows you how to access the folder from the docker image.
+!!! Warning
-```bash
-docker run -v /mnt/my_device/:/data/ -ti mdl4eo/otbtf:3.4.0-cpu bash -c "ls /data"
-```
-Beware of ownership issues! see the last section of this doc.
+ Until r2.4, all images are development-ready, and the sources are located
+ in `/work/`.
+ Since r2.4, development-ready images have the source in `/src/` and are
+ tagged "...-dev".
-# GPU enabled docker
+## GPU enabled docker
In Linux, this is quite straightforward.
-Just follow the steps described in the [nvidia-docker documentation](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html).
+Just follow the steps described in the
+[nvidia-docker documentation](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html).
You can then use the OTBTF `gpu` tagged docker images with the **NVIDIA runtime** :
With Docker version earlier than 19.03 :
```bash
-docker run --runtime=nvidia -ti mdl4eo/otbtf:3.4.0-gpu bash
+docker run --runtime=nvidia -ti mdl4eo/otbtf:4.0.0-gpu bash
```
With Docker version including and after 19.03 :
```bash
-docker run --gpus all -ti mdl4eo/otbtf:3.4.0-gpu bash
+docker run --gpus all -ti mdl4eo/otbtf:4.0.0-gpu bash
```
-You can find some details on the **GPU docker image** and some **docker tips and tricks** on [this blog](https://mdl4eo.irstea.fr/2019/10/15/otbtf-docker-image-with-gpu/).
+You can find some details on the **GPU docker image** and some **docker tips
+and tricks** on
+[this blog](https://mdl4eo.irstea.fr/2019/10/15/otbtf-docker-image-with-gpu/).
Be careful though, these infos might be a bit outdated...
-# Docker Installation
+## Docker Installation
+
+This section is a very small insight on the installation of docker on Linux
+and Windows.
+
+### Debian and Ubuntu
-### Installation and first steps on Windows 10
+See here how to install docker on Ubuntu
+[here](https://docs.docker.com/engine/install/ubuntu/).
+
+### Windows 10
1. Install [WSL2](https://docs.microsoft.com/en-us/windows/wsl/install-win10#manual-installation-steps) (Windows Subsystem for Linux)
2. Install [docker desktop](https://www.docker.com/products/docker-desktop)
3. Start **docker desktop** and **enable WSL2** from *Settings* > *General* then tick the box *Use the WSL2 based engine*
-3. Open a **cmd.exe** or **PowerShell** terminal, and type `docker create --name otbtf-cpu --interactive --tty mdl4eo/otbtf:3.4.0-cpu`
+3. Open a **cmd.exe** or **PowerShell** terminal, and type `docker create --name otbtf-cpu --interactive --tty mdl4eo/otbtf:4.0.0-cpu`
4. Open **docker desktop**, and check that the docker is running in the **Container/Apps** menu

5. From **docker desktop**, click on the icon highlighted as shown below, and use the bash terminal that should pop up!

Troubleshooting:
+
- [Docker for windows WSL documentation](https://docs.docker.com/docker-for-windows/wsl)
- [WSL2 installation steps](https://docs.microsoft.com/en-us/windows/wsl/install-win10)
-### Use the GPU with Windows 10 + WSL2
-
-*Work in progress*
-
-Some users have reported to use OTBTF with GPU in windows 10 using WSL2.
-How to install WSL2 with Cuda on windows 10:
-https://docs.nvidia.com/cuda/wsl-user-guide/index.html
-https://docs.docker.com/docker-for-windows/wsl/#gpu-support
-
-
-### Debian and Ubuntu
-
-See here how to install docker on Ubuntu [here](https://docs.docker.com/engine/install/ubuntu/).
-
-# Docker Usage
-
-This section is largely inspired from the [moringa docker help](https://gitlab.irstea.fr/raffaele.gaetano/moringa/blob/develop/docker/README.md). Big thanks to them.
-
-## Useful diagnostic commands
-
-Here are some useful commands.
-
-```bash
-docker info # System info
-docker images # List local images
-docker container ls # List containers
-docker ps # Show running containers
-```
-
-On Linux, control state with systemd:
-```bash
-sudo systemctl {status,enable,disable,start,stop} docker
-```
-
-### Run some commands
-
-Run a simple command in a one-shot container:
-
-```bash
-docker run mdl4eo/otbtf:3.4.0-cpu otbcli_PatchesExtraction
-```
-
-You can also use the image in interactive mode with bash:
-```bash
-docker run -ti mdl4eo/otbtf:3.4.0-cpu bash
-```
-
-### Persistent container
-
-Persistent (named) container with volume, here with home dir, but it can be any directory.
-Beware of ownership issues, see the last section of this doc.
-
-```bash
-docker create --interactive --tty --volume /home/$USER:/home/otbuser/ \
- --name otbtf mdl4eo/otbtf:3.4.0-cpu /bin/bash
-```
-
-### Interactive session
-
-```bash
-docker start -i otbtf
-```
-
-### Background container
-
-```bash
-docker start otbtf
-docker exec otbtf ls -alh
-docker stop otbtf
-```
-
-### Running commands with root user
-
-Background container is the easiest way:
-
-```bash
-docker start otbtf
-# Example with apt update (you can't use &&, one docker exec is required for each command)
-docker exec --user root otbtf apt-get update
-docker exec --user root otbtf apt-get upgrade -y
-```
-
-### Container-specific commands, especially for background containers:
-
-```bash
-docker inspect otbtf # See full container info dump
-docker logs otbtf # See command logs and outputs
-docker stats otbtf # Real time container statistics
-docker {pause,unpause} otbtf # Freeze container
-```
-
-### Stop a background container
-
-Don't forget to stop the container after you have done.
-
-```bash
-docker stop otbtf
-```
-
-### Remove a persistent container
-
-```bash
-docker rm otbtf
-```
-
-# Fix volume ownership issue (required if host's UID > 1000)
-
-When mounting a volume, you may experience errors while trying to write files from within the container.
-Since the default user (**otbuser**) is UID 1000, you won't be able to write files into your volume
-which is mounted with the same UID than your linux host user (may be UID 1001 or more).
-In order to address this, you need to edit the container's user UID and GID to match the right numerical value.
-This will only persist in a named container, it is required every time you're creating a new one.
-
-
-Create a named container (here with your HOME as volume), Docker will automatically pull image
+!!! Info
-```bash
-docker create --interactive --tty --volume /home/$USER:/home/otbuser \
- --name otbtf mdl4eo/otbtf:3.4.0-cpu /bin/bash
-```
-
-Start a background container process:
-
-```bash
-docker start otbtf
-```
-
-Exec required commands with user root (here with host's ID, replace $UID and $GID with desired values):
-
-```bash
-docker exec --user root otbtf usermod otbuser -u $UID
-docker exec --user root otbtf groupmod otbuser -g $GID
-```
-
-Force reset ownership with updated UID and GID.
-Make sure to double check that `docker exec otbtf id` because recursive chown will apply to your volume in `/home/otbuser`
-
-```bash
-docker exec --user root otbtf chown -R otbuser:otbuser /home/otbuser
-```
-
-Stop the background container and start a new interactive shell:
+ Some users have reported to use OTBTF with GPU in windows 10 using WSL2.
+ How to install WSL2 with Cuda on windows 10:
+ https://docs.nvidia.com/cuda/wsl-user-guide/index.html
+ https://docs.docker.com/docker-for-windows/wsl/#gpu-support
-```bash
-docker stop otbtf
-docker start -i otbtf
-```
+## Build your own images
-Check if ownership is right
-
-```bash
-id
-ls -Alh /home/otbuser
-touch /home/otbuser/test.txt
-```
+If you want to use optimization flags, change GPUs compute capability, etc.
+you can build your own docker image using the provided dockerfile.
+See the [docker build documentation](#docker_build.html).
-# Older docker releases
+## Older images
Here you can find the list of older releases of OTBTF:
@@ -283,4 +152,10 @@ Here you can find the list of older releases of OTBTF:
| **mdl4eo/otbtf:3.3.3-gpu-dev** | Ubuntu Focal | r2.8 | 8.1.0 | GPU, no optimization (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
| **gitlab.irstea.fr/remi.cresson/otbtf/container_registry/otbtf:3.3.3-gpu-opt** | Ubuntu Focal | r2.8 | 8.1.0 | GPU with opt. | no | 5.2,6.1,7.0,7.5,8.6|
| **gitlab.irstea.fr/remi.cresson/otbtf/container_registry/otbtf:3.3.3-gpu-opt-dev** | Ubuntu Focal | r2.8 | 8.1.0 | GPU with opt. (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
+| **mdl4eo/otbtf:3.4.0-cpu** | Ubuntu Focal | r2.8 | 8.1.0 | CPU, no optimization | no | 5.2,6.1,7.0,7.5,8.6|
+| **mdl4eo/otbtf:3.4.0-cpu-dev** | Ubuntu Focal | r2.8 | 8.1.0 | CPU, no optimization (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
+| **mdl4eo/otbtf:3.4.0-gpu** | Ubuntu Focal | r2.8 | 8.1.0 | GPU, no optimization | no | 5.2,6.1,7.0,7.5,8.6|
+| **mdl4eo/otbtf:3.4.0-gpu-dev** | Ubuntu Focal | r2.8 | 8.1.0 | GPU, no optimization (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
+| **gitlab.irstea.fr/remi.cresson/otbtf/container_registry/otbtf:3.4.0-gpu-opt** | Ubuntu Focal | r2.8 | 8.1.0 | GPU with opt. | no | 5.2,6.1,7.0,7.5,8.6|
+| **gitlab.irstea.fr/remi.cresson/otbtf/container_registry/otbtf:3.4.0-gpu-opt-dev** | Ubuntu Focal | r2.8 | 8.1.0 | GPU with opt. (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
diff --git a/doc/gen_ref_pages.py b/doc/gen_ref_pages.py
new file mode 100644
index 00000000..93fc1b4b
--- /dev/null
+++ b/doc/gen_ref_pages.py
@@ -0,0 +1,33 @@
+"""Generate the code reference pages."""
+
+from pathlib import Path
+
+import mkdocs_gen_files
+
+for path in sorted(Path("otbtf").rglob("*.py")): #
+ module_path = path.relative_to(".").with_suffix("") #
+ doc_path = path.relative_to(".").with_suffix(".md") #
+ full_doc_path = Path("reference", doc_path) #
+
+ parts = list(module_path.parts)
+
+ if parts[-1] == "__init__": #
+ parts = parts[:-1]
+ elif parts[-1] == "__main__":
+ continue
+
+ with mkdocs_gen_files.open(full_doc_path, "w") as fd: #
+ identifier = ".".join(parts) #
+ print("::: " + identifier)
+ print("::: " + identifier, file=fd) #
+
+ mkdocs_gen_files.set_edit_path(full_doc_path, path)
+
+# Workaround to install and execute git-lfs on Read the Docs
+import os
+if not os.path.exists('./git-lfs'):
+ os.system('wget https://github.com/git-lfs/git-lfs/releases/download/v2.7.1/git-lfs-linux-amd64-v2.7.1.tar.gz')
+ os.system('tar xvfz git-lfs-linux-amd64-v2.7.1.tar.gz')
+ os.system('./git-lfs install') # make lfs available in current repository
+ os.system('./git-lfs fetch') # download content from remote
+ os.system('./git-lfs checkout') # make local files to have the real content on them
diff --git a/doc/images/modelbase.png b/doc/images/modelbase.png
new file mode 100644
index 00000000..1b5807d5
--- /dev/null
+++ b/doc/images/modelbase.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:dbb9e80568c04da7f96423ce7bebe25e6289e57bd9ccff8a6f183b4eddead2f0
+size 103824
diff --git a/doc/images/modelbase_1.png b/doc/images/modelbase_1.png
new file mode 100644
index 00000000..39fe2f30
--- /dev/null
+++ b/doc/images/modelbase_1.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:dd13daaf55b097fb1bb2c4834fad45c267436db7d308684543785aba689b3957
+size 94962
diff --git a/doc/images/modelbase_2.png b/doc/images/modelbase_2.png
new file mode 100644
index 00000000..14ff47b5
--- /dev/null
+++ b/doc/images/modelbase_2.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:64c81033c7d14432fbac517ed7d18ff9b5fd45999b4dca0168d9b070cd8baee9
+size 95149
diff --git a/doc/images/modelbase_3.png b/doc/images/modelbase_3.png
new file mode 100644
index 00000000..4cf48fb4
--- /dev/null
+++ b/doc/images/modelbase_3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:d17b96e940ed7957fb08c02485c6e103124582bd815e857728365e9c9dcaca35
+size 88527
diff --git a/doc/images/modelbase_4.png b/doc/images/modelbase_4.png
new file mode 100644
index 00000000..1b442d9a
--- /dev/null
+++ b/doc/images/modelbase_4.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9647cd300df533b1550170da2cf500f17c914cb77d7b61c9585249501ae54d2e
+size 151715
diff --git a/doc/images/pipeline.png b/doc/images/pipeline.png
new file mode 100644
index 00000000..546ac7c5
--- /dev/null
+++ b/doc/images/pipeline.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:927369acc474e03d388c5efb3d142e4657ad8c28dbbd1195a6ba370f7dcd2d40
+size 153406
diff --git a/doc/index.md b/doc/index.md
new file mode 100644
index 00000000..4bb28c76
--- /dev/null
+++ b/doc/index.md
@@ -0,0 +1,112 @@
+# OTBTF: Orfeo ToolBox meets TensorFlow
+
+<p align="center">
+<img src="images/logo.png" width="160px">
+<br>
+<a href="https://gitlab.irstea.fr/remi.cresson/otbtf/-/releases">
+<img src="https://gitlab.irstea.fr/remi.cresson/otbtf/-/badges/release.svg">
+</a>
+<a href="https://gitlab.irstea.fr/remi.cresson/otbtf/-/commits/master">
+<img src="https://gitlab.irstea.fr/remi.cresson/otbtf/badges/master/pipeline.svg">
+</a>
+<a href="LICENSE">
+<img src="https://img.shields.io/badge/License-Apache%202.0-blue.svg">
+</a>
+</p>
+
+
+This remote module of the [Orfeo ToolBox](https://www.orfeo-toolbox.org)
+provides a generic, multi-purpose deep learning framework, targeting remote
+sensing images processing. It contains a set of new process objects for OTB
+that internally invoke [Tensorflow](https://www.tensorflow.org/), and new [OTB
+applications](#otb-applications) to perform deep learning with real-world
+remote sensing images. Applications can be used to build OTB pipelines from
+Python or C++ APIs. OTBTF also includes a [python API](#python-api) to build
+Keras compliant models, easy to train in distributed environments.
+
+
+## Features
+
+### OTB Applications
+
+- Sample patches in remote sensing images with `PatchesExtraction`,
+- Inference with support of OTB streaming mechanism with
+`TensorflowModelServe`: this means that inference is not limited by images
+number, size, of channels depths, and can be used as a "lego" in any pipeline
+composed of OTB applications and preserving streaming.
+- Model training, supporting save/restore/import operations (a model can be
+trained from scratch or fine-tuned) with `TensorflowModelTrain`. This
+application targets mostly newcomers and is nice for educational purpose, but
+deep learning practitioners will for sure prefer the Python API of OTBTF.
+
+### Python API
+
+The `otbtf` module targets python developers that want to train their own
+model from python with TensorFlow or Keras.
+It provides various classes for datasets and iterators to handle the
+_patches images_ generated from the `PatchesExtraction` OTB application.
+For instance, the `otbtf.DatasetFromPatchesImages` can be instantiated from a
+set of _patches images_ and delivering samples as `tf.dataset` that can be
+used in your favorite TensorFlow pipelines, or convert your patches into
+TFRecords. The `otbtf.TFRecords` enables you train networks from TFRecords
+files, which is quite suited for distributed training. Read more in the
+[tutorial for keras](otbtf/examples/tensorflow_v2x/fcnn/README.md).
+
+## Examples
+
+Below are some screen captures of deep learning applications performed at
+large scale with OTBTF.
+
+ - Landcover mapping (Spot-7 images --> Building map using semantic
+segmentation)
+
+
+
+ - Super resolution (Sentinel-2 images upsampled with the
+[SR4RS software](https://github.com/remicres/sr4rs), which is based on OTBTF)
+
+
+
+ - Sentinel-2 reconstruction with Sentinel-1 VV/VH with the
+[Decloud software](https://github.com/CNES/decloud), which is based on OTBTF
+
+
+
+ - Image to image translation (Spot-7 image --> Wikimedia Map using CGAN.
+So unnecessary but fun!)
+
+
+
+## Contribute
+
+Every one can **contribute** to OTBTF. Just open a PR :)
+
+## Cite
+
+```
+@article{cresson2018framework,
+ title={A framework for remote sensing images processing using deep learning techniques},
+ author={Cresson, R{\'e}mi},
+ journal={IEEE Geoscience and Remote Sensing Letters},
+ volume={16},
+ number={1},
+ pages={25--29},
+ year={2018},
+ publisher={IEEE}
+}
+```
+
+## Additional resources
+
+- The [*test* folder](https://github.com/remicres/otbtf/tree/master/test/)
+of this repository contains various use-cases with commands, python codes, and
+input/baseline data,
+- This [book](https://doi.org/10.1201/9781003020851) contains 130 pages to
+learn how to use OTBTF with OTB and QGIS to perform various kind of deep
+learning sorcery on remote sensing images (patch-based classification for
+landcover mapping, semantic segmentation of buildings, optical image
+restoration from joint SAR/Optical time series): *Cresson, R. (2020). Deep
+Learning for Remote Sensing Images with Open Source Software. CRC Press.*
+- A small [tutorial](https://mdl4eo.irstea.fr/2019/01/04/an-introduction-to-deep-learning-on-remote-sensing-images-tutorial/) on MDL4EO's blog
+- Check [our repository](https://github.com/remicres/otbtf_tutorials_resources)
+containing stuff (data and models) to begin with!
diff --git a/mkdocs.yml b/mkdocs.yml
new file mode 100644
index 00000000..bef032e1
--- /dev/null
+++ b/mkdocs.yml
@@ -0,0 +1,84 @@
+# mkdocs.yml
+theme:
+ name: "material"
+ logo: images/logo.png
+ icon:
+ repo: fontawesome/brands/github
+ features:
+ - navigation.instant
+ - content.code.copy
+ - content.code.annotate
+ - toc.follow
+
+plugins:
+- search
+- gen-files:
+ scripts:
+ - doc/gen_ref_pages.py
+- mkdocstrings:
+ watch:
+ - otbtf/
+- literate-nav:
+ nav_file: SUMMARY.md
+- section-index
+- mermaid2
+
+nav:
+- Home: index.md
+- Installation:
+ - Install from docker: docker_use.md
+ - Build your own docker images: docker_build.md
+ - Docker troubleshooting: docker_troubleshooting.md
+ - Build from source: build_from_sources.md
+- Applications:
+ - Overview: app_overview.md
+ - Sampling: app_sampling.md
+ - Training: app_training.md
+ - Inference: app_inference.md
+- Python API:
+ - Model generalities: api_model_generalities.md
+ - Deterministic models: reference/otbtf/examples/tensorflow_v2x/deterministic/__init__.md
+ - Build and train deep learning models: api_tutorial.md
+ - Distributed training: api_distributed.md
+- Python API references:
+ - dataset: reference/otbtf/dataset.md
+ - tfrecords: reference/otbtf/tfrecords.md
+ - model: reference/otbtf/model.md
+- Tensorflow v1:
+ - Tricks (deprecated): deprecated.md
+ - Models examples: reference/otbtf/examples/tensorflow_v1x/__init__.md
+
+# Customization
+extra:
+ feature:
+ tabs: true
+ social:
+ - icon: fontawesome/brands/github
+ link: https://github.com/remicres/otbtf
+use_directory_urls: false # this creates some otbtf/core.html pages instead of otbtf/core/index.html
+
+markdown_extensions:
+ - attr_list
+ - admonition
+ - toc:
+ permalink: true
+ title: On this page
+ toc_depth: 1-2
+ - pymdownx.highlight:
+ anchor_linenums: true
+ - pymdownx.inlinehilite
+ - pymdownx.snippets
+ - pymdownx.details
+ - pymdownx.superfences
+ - mdx_math
+ - pymdownx.emoji:
+ emoji_index: !!python/name:materialx.emoji.twemoji
+ emoji_generator: !!python/name:materialx.emoji.to_svg
+
+# Rest of the navigation..
+site_name: "OTBTF"
+repo_url: https://github.com/remicres/otbtf
+repo_name: otbtf
+docs_dir: doc/
+extra_javascript:
+ - https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.4/MathJax.js?config=TeX-AMS-MML_HTMLorMML
diff --git a/otbtf/__init__.py b/otbtf/__init__.py
index 6ee17f9e..04ac11db 100644
--- a/otbtf/__init__.py
+++ b/otbtf/__init__.py
@@ -20,12 +20,17 @@
"""
OTBTF python module
"""
+import pkg_resources
try:
- from otbtf.utils import read_as_np_arr, gdal_open
- from otbtf.dataset import Buffer, PatchesReaderBase, PatchesImagesReader, IteratorBase, RandomIterator, Dataset, \
- DatasetFromPatchesImages
+ from otbtf.utils import read_as_np_arr, gdal_open # noqa
+ from otbtf.dataset import Buffer, PatchesReaderBase, PatchesImagesReader, \
+ IteratorBase, RandomIterator, Dataset, DatasetFromPatchesImages # noqa
except ImportError:
- print("Warning: otbtf.utils and otbtf.dataset were not imported. Using OTBTF without GDAL.")
+ print(
+ "Warning: otbtf.utils and otbtf.dataset were not imported. "
+ "Using OTBTF without GDAL."
+ )
-from otbtf.tfrecords import TFRecords
-from otbtf.model import ModelBase
+from otbtf.tfrecords import TFRecords # noqa
+from otbtf.model import ModelBase # noqa
+__version__ = pkg_resources.require("otbtf")[0].version
diff --git a/otbtf/dataset.py b/otbtf/dataset.py
index b7ca2025..cf2a0759 100644
--- a/otbtf/dataset.py
+++ b/otbtf/dataset.py
@@ -2,7 +2,7 @@
# ==========================================================================
#
# Copyright 2018-2019 IRSTEA
-# Copyright 2020-2022 INRAE
+# Copyright 2020-2023 INRAE
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
@@ -18,151 +18,211 @@
#
# ==========================================================================*/
"""
-Contains stuff to help working with TensorFlow and geospatial data in the OTBTF framework.
+[Source code :fontawesome-brands-github:](https://github.com/remicres/otbtf/
+tree/master/otbtf/dataset.py){ .md-button }
+
+Contains stuff to help working with TensorFlow and geospatial data in the
+OTBTF framework.
"""
-import threading
+import logging
import multiprocessing
+import threading
import time
-import logging
from abc import ABC, abstractmethod
+
+from typing import Any, List, Dict, Type, Callable
import numpy as np
import tensorflow as tf
-from otbtf.utils import read_as_np_arr, gdal_open
-from otbtf.tfrecords import TFRecords
+import otbtf.tfrecords
+import otbtf.utils
-# -------------------------------------------------- Buffer class ------------------------------------------------------
class Buffer:
"""
Used to store and access list of objects
"""
- def __init__(self, max_length):
+ def __init__(self, max_length: int):
+ """
+ Params:
+ max_length: length of the buffer
+ """
self.max_length = max_length
self.container = []
- def size(self):
+ def size(self) -> int:
"""
- Returns the buffer size
+ Returns:
+ the buffer size
"""
return len(self.container)
- def add(self, new_element):
+ def add(self, new_element: Any):
"""
- Add an element in the buffer
- :param new_element: new element to add
+ Add an element in the buffer.
+
+ Params:
+ new_element: new element to add
+
"""
self.container.append(new_element)
assert self.size() <= self.max_length
- def is_complete(self):
+ def is_complete(self) -> bool:
"""
- Return True if the buffer is at full capacity
+ Returns:
+ True if the buffer is full, False else
"""
return self.size() == self.max_length
-# ---------------------------------------------- PatchesReaderBase class -----------------------------------------------
-
class PatchesReaderBase(ABC):
"""
Base class for patches delivery
"""
@abstractmethod
- def get_sample(self, index):
+ def get_sample(self, index: int) -> Any:
"""
Return one sample.
- :return One sample instance, whatever the sample structure is (dict, numpy array, ...)
+
+ Params:
+ index: sample index
+
+ Returns:
+ One sample instance, whatever the sample structure is (dict, numpy
+ array, ...)
"""
@abstractmethod
def get_stats(self) -> dict:
"""
Compute some statistics for each source.
- Depending if streaming is used, the statistics are computed directly in memory, or chunk-by-chunk.
-
- :return a dict having the following structure:
- {
- "src_key_0":
- {"min": np.array([...]),
- "max": np.array([...]),
- "mean": np.array([...]),
- "std": np.array([...])},
- ...,
- "src_key_M":
- {"min": np.array([...]),
- "max": np.array([...]),
- "mean": np.array([...]),
- "std": np.array([...])},
- }
+ Depending on if streaming is used, the statistics are computed
+ directly in memory, or chunk-by-chunk.
+
+ Returns:
+ a dict having the following structure:
+ {
+ "src_key_0":
+ {"min": np.array([...]),
+ "max": np.array([...]),
+ "mean": np.array([...]),
+ "std": np.array([...])},
+ ...,
+ "src_key_M":
+ {"min": np.array([...]),
+ "max": np.array([...]),
+ "mean": np.array([...]),
+ "std": np.array([...])},
+ }
+
"""
@abstractmethod
- def get_size(self):
+ def get_size(self) -> int:
"""
Returns the total number of samples
- :return: number of samples (int)
- """
+ Returns:
+ number of samples (int)
+
+ """
-# --------------------------------------------- PatchesImagesReader class ----------------------------------------------
class PatchesImagesReader(PatchesReaderBase):
"""
This class provides a read access to a set of patches images.
- A patches image is an image of patches stacked in rows, as produced from the OTBTF "PatchesExtraction"
- application, and is stored in a raster format (e.g. GeoTiff).
- A source can be a particular domain in which the patches are extracted (remember that in OTBTF applications,
- the number of sources is controlled by the OTB_TF_NSOURCES environment variable).
+ A patches image is an image of patches stacked in rows, as produced from
+ the OTBTF "PatchesExtraction" application, and is stored in a raster
+ format (e.g. GeoTiff).
+ A source can be a particular domain in which the patches are extracted
+ (remember that in OTBTF applications, the number of sources is controlled
+ by the `OTB_TF_NSOURCES` environment variable).
This class enables to use:
- multiple sources
- multiple patches images per source
- Each patch can be independently accessed using the get_sample(index) function, with index in [0, self.size),
- self.size being the total number of patches (must be the same for each sources).
+ Each patch can be independently accessed using the get_sample(index)
+ function, with index in [0, self.size), self.size being the total number
+ of patches (must be the same for each sources).
+
+ See `PatchesReaderBase`.
- :see PatchesReaderBase
"""
- def __init__(self, filenames_dict, use_streaming=False, scalar_dict=None):
- """
- :param filenames_dict: A dict() structured as follow:
- {src_name1: [src1_patches_image_1.tif, ..., src1_patches_image_N.tif],
- src_name2: [src2_patches_image_1.tif, ..., src2_patches_image_N.tif],
- ...
- src_nameM: [srcM_patches_image_1.tif, ..., srcM_patches_image_N.tif]}
- :param use_streaming: if True, the patches are read on the fly from the disc, nothing is kept in memory.
- :param scalar_dict: (optional) a dict containing list of scalars (int, float, str) as follow:
- {scalar_name1: ["value_1", ..., "value_N"],
- scalar_name2: [value_1, ..., value_N],
- ...
- scalar_nameM: [value1, ..., valueN]}
+ def __init__(
+ self,
+ filenames_dict: Dict[str, List[str]],
+ use_streaming: bool = False,
+ scalar_dict: Dict[str, List[Any]] = None
+ ):
+ """
+ Params:
+ filenames_dict: A dict structured as follow:
+ {
+ src_name1: [
+ src1_patches_image_1.tif, ..., src1_patches_image_N.tif
+ ],
+ src_name2: [
+ src2_patches_image_1.tif, ..., src2_patches_image_N.tif
+ ],
+ ...
+ src_nameM: [
+ srcM_patches_image_1.tif, ..., srcM_patches_image_N.tif
+ ]
+ }
+ use_streaming: if True, the patches are read on the fly from the
+ disc, nothing is kept in memory. Else, everything is packed in
+ memory.
+ scalar_dict: (optional) a dict containing list of scalars (int,
+ float, str) as follow:
+ {
+ scalar_name1: ["value_1", ..., "value_N"],
+ scalar_name2: [value_1, ..., value_N],
+ ...
+ scalar_nameM: [value1, ..., valueN]
+ }
+
"""
assert len(filenames_dict.values()) > 0
# gdal_ds dict
- self.gdal_ds = {key: [gdal_open(src_fn) for src_fn in src_fns] for key, src_fns in filenames_dict.items()}
+ self.gdal_ds = {
+ key: [otbtf.utils.gdal_open(src_fn) for src_fn in src_fns]
+ for key, src_fns in filenames_dict.items()
+ }
# streaming on/off
self.use_streaming = use_streaming
# Scalar dict (e.g. for metadata)
# If the scalars are not numpy.ndarray, convert them
- self.scalar_dict = {key: [i if isinstance(i, np.ndarray) else np.asarray(i) for i in scalars]
- for key, scalars in scalar_dict.items()} if scalar_dict else {}
+ self.scalar_dict = {
+ key: [
+ i if isinstance(i, np.ndarray) else np.asarray(i)
+ for i in scalars
+ ]
+ for key, scalars in scalar_dict.items()
+ } if scalar_dict else {}
# check number of patches in each sources
- if len({len(ds_list) for ds_list in list(self.gdal_ds.values()) + list(self.scalar_dict.values())}) != 1:
- raise Exception("Each source must have the same number of patches images")
+ if len({
+ len(ds_list)
+ for ds_list in
+ list(self.gdal_ds.values()) + list(self.scalar_dict.values())
+ }) != 1:
+ raise Exception(
+ "Each source must have the same number of patches images"
+ )
# gdal_ds check
nb_of_patches = {key: 0 for key in self.gdal_ds}
- self.nb_of_channels = dict()
+ self.nb_of_channels = {}
for src_key, ds_list in self.gdal_ds.items():
for gdal_ds in ds_list:
nb_of_patches[src_key] += self._get_nb_of_patches(gdal_ds)
@@ -170,20 +230,33 @@ class PatchesImagesReader(PatchesReaderBase):
self.nb_of_channels[src_key] = gdal_ds.RasterCount
else:
if self.nb_of_channels[src_key] != gdal_ds.RasterCount:
- raise Exception("All patches images from one source must have the same number of channels!"
- f"Error happened for source: {src_key}")
+ raise Exception(
+ "All patches images from one source must have the "
+ "same number of channels! "
+ f"Error happened for source: {src_key}"
+ )
if len(set(nb_of_patches.values())) != 1:
- raise Exception(f"Sources must have the same number of patches! Number of patches: {nb_of_patches}")
+ raise Exception(
+ "Sources must have the same number of patches! "
+ f"Number of patches: {nb_of_patches}"
+ )
# gdal_ds sizes
src_key_0 = list(self.gdal_ds)[0] # first key
- self.ds_sizes = [self._get_nb_of_patches(ds) for ds in self.gdal_ds[src_key_0]]
+ self.ds_sizes = [
+ self._get_nb_of_patches(ds)
+ for ds in self.gdal_ds[src_key_0]
+ ]
self.size = sum(self.ds_sizes)
# if use_streaming is False, we store in memory all patches images
if not self.use_streaming:
- self.patches_buffer = {src_key: np.concatenate([read_as_np_arr(ds) for ds in src_ds], axis=0) for
- src_key, src_ds in self.gdal_ds.items()}
+ self.patches_buffer = {
+ src_key: np.concatenate([
+ otbtf.utils.read_as_np_arr(ds) for ds in src_ds
+ ], axis=0)
+ for src_key, src_ds in self.gdal_ds.items()
+ }
def _get_ds_and_offset_from_index(self, index):
offset = index
@@ -211,48 +284,73 @@ class PatchesImagesReader(PatchesReaderBase):
return np.transpose(buffer, axes=(1, 2, 0))
return np.expand_dims(buffer, axis=2)
- def get_sample(self, index):
+ def get_sample(self, index: int) -> Dict[str, np.array]:
"""
Return one sample of the dataset.
- :param index: the sample index. Must be in the [0, self.size) range.
- :return: The sample is stored in a dict() with the following structure:
- {"src_key_0": np.array((psz_y_0, psz_x_0, nb_ch_0)),
- "src_key_1": np.array((psz_y_1, psz_x_1, nb_ch_1)),
- ...
- "src_key_M": np.array((psz_y_M, psz_x_M, nb_ch_M))}
+
+ Params:
+ index: the sample index. Must be in the [0, self.size) range.
+
+ Returns:
+ The sample is stored in a dict with the following structure:
+ {
+ "src_key_0": np.array((psz_y_0, psz_x_0, nb_ch_0)),
+ "src_key_1": np.array((psz_y_1, psz_x_1, nb_ch_1)),
+ ...
+ "src_key_M": np.array((psz_y_M, psz_x_M, nb_ch_M))
+ }
+
"""
assert index >= 0
assert index < self.size
i, offset = self._get_ds_and_offset_from_index(index)
- res = {src_key: scalar[i] for src_key, scalar in self.scalar_dict.items()}
+ res = {
+ src_key: scalar[i]
+ for src_key, scalar in self.scalar_dict.items()
+ }
if not self.use_streaming:
- res.update({src_key: arr[index, :, :, :] for src_key, arr in self.patches_buffer.items()})
+ res.update({
+ src_key: arr[index, :, :, :]
+ for src_key, arr in self.patches_buffer.items()
+ })
else:
- res.update({src_key: self._read_extract_as_np_arr(self.gdal_ds[src_key][i], offset)
- for src_key in self.gdal_ds})
+ res.update({
+ src_key: self._read_extract_as_np_arr(
+ self.gdal_ds[src_key][i], offset
+ )
+ for src_key in self.gdal_ds
+ })
return res
- def get_stats(self):
+ def get_stats(self) -> Dict[str, List[float]]:
"""
Compute some statistics for each source.
- When streaming is used, chunk-by-chunk. Else, the statistics are computed directly in memory.
+ When streaming is used, chunk-by-chunk. Else, the statistics are
+ computed directly in memory.
- :return statistics dict
+ Returns:
+ statistics dict
"""
logging.info("Computing stats")
if not self.use_streaming:
axis = (0, 1, 2) # (row, col)
- stats = {src_key: {"min": np.amin(patches_buffer, axis=axis),
- "max": np.amax(patches_buffer, axis=axis),
- "mean": np.mean(patches_buffer, axis=axis),
- "std": np.std(patches_buffer, axis=axis)} for src_key, patches_buffer in
- self.patches_buffer.items()}
+ stats = {
+ src_key: {
+ "min": np.amin(patches_buffer, axis=axis),
+ "max": np.amax(patches_buffer, axis=axis),
+ "mean": np.mean(patches_buffer, axis=axis),
+ "std": np.std(patches_buffer, axis=axis)
+ }
+ for src_key, patches_buffer in self.patches_buffer.items()
+ }
else:
axis = (0, 1) # (row, col)
def _filled(value):
- return {src_key: value * np.ones((self.nb_of_channels[src_key])) for src_key in self.gdal_ds}
+ return {
+ src_key: value * np.ones((self.nb_of_channels[src_key]))
+ for src_key in self.gdal_ds}
_maxs = _filled(0.0)
_mins = _filled(float("inf"))
@@ -262,26 +360,44 @@ class PatchesImagesReader(PatchesReaderBase):
sample = self.get_sample(index=index)
for src_key, np_arr in sample.items():
rnumel = 1.0 / float(np_arr.shape[0] * np_arr.shape[1])
- _mins[src_key] = np.minimum(np.amin(np_arr, axis=axis).flatten(), _mins[src_key])
- _maxs[src_key] = np.maximum(np.amax(np_arr, axis=axis).flatten(), _maxs[src_key])
- _sums[src_key] += rnumel * np.sum(np_arr, axis=axis).flatten()
- _sqsums[src_key] += rnumel * np.sum(np.square(np_arr), axis=axis).flatten()
+ _mins[src_key] = np.minimum(
+ np.amin(np_arr, axis=axis).flatten(), _mins[src_key]
+ )
+ _maxs[src_key] = np.maximum(
+ np.amax(np_arr, axis=axis).flatten(), _maxs[src_key]
+ )
+ _sums[src_key] += rnumel * np.sum(
+ np_arr, axis=axis
+ ).flatten()
+ _sqsums[src_key] += rnumel * np.sum(
+ np.square(np_arr), axis=axis
+ ).flatten()
rsize = 1.0 / float(self.size)
- stats = {src_key: {"min": _mins[src_key],
- "max": _maxs[src_key],
- "mean": rsize * _sums[src_key],
- "std": np.sqrt(rsize * _sqsums[src_key] - np.square(rsize * _sums[src_key]))
- } for src_key in self.gdal_ds}
+ stats = {
+ src_key: {
+ "min": _mins[src_key],
+ "max": _maxs[src_key],
+ "mean": rsize * _sums[src_key],
+ "std": np.sqrt(
+ rsize * _sqsums[src_key] - np.square(
+ rsize * _sums[src_key]
+ )
+ )
+ }
+ for src_key in self.gdal_ds
+ }
logging.info("Stats: %s", stats)
return stats
- def get_size(self):
+ def get_size(self) -> int:
+ """
+ Returns:
+ size
+ """
return self.size
-# ----------------------------------------------- IteratorBase class ---------------------------------------------------
-
class IteratorBase(ABC):
"""
Base class for iterators
@@ -292,14 +408,16 @@ class IteratorBase(ABC):
pass
-# ---------------------------------------------- RandomIterator class --------------------------------------------------
-
class RandomIterator(IteratorBase):
"""
Pick a random number in the [0, handler.size) range.
"""
- def __init__(self, patches_reader):
+ def __init__(self, patches_reader: PatchesReaderBase):
+ """
+ Params:
+ patches_reader: patches reader
+ """
super().__init__(patches_reader=patches_reader)
self.indices = np.arange(0, patches_reader.get_size())
self._shuffle()
@@ -321,42 +439,51 @@ class RandomIterator(IteratorBase):
np.random.shuffle(self.indices)
-# ------------------------------------------------- Dataset class ------------------------------------------------------
-
class Dataset:
"""
Handles the "mining" of patches.
- This class has a thread that extract tuples from the readers, while ensuring the access of already gathered tuples.
+ This class has a thread that extract tuples from the readers, while
+ ensuring the access of already gathered tuples.
+
+ See `PatchesReaderBase` and `Buffer`
- :see PatchesReaderBase
- :see Buffer
"""
- def __init__(self, patches_reader: PatchesReaderBase = None, buffer_length: int = 128,
- Iterator=RandomIterator, max_nb_of_samples=None):
+ def __init__(
+ self,
+ patches_reader: PatchesReaderBase = None,
+ buffer_length: int = 128,
+ iterator_cls: Type[IteratorBase] = RandomIterator,
+ max_nb_of_samples: int = None
+ ):
"""
- :param patches_reader: The patches reader instance
- :param buffer_length: The number of samples that are stored in the buffer
- :param Iterator: The iterator class used to generate the sequence of patches indices.
- :param max_nb_of_samples: Optional, max number of samples to consider
+ Params:
+ patches_reader: The patches reader instance
+ buffer_length: The number of samples that are stored in the
+ buffer
+ iterator_cls: The iterator class used to generate the sequence of
+ patches indices.
+ max_nb_of_samples: Optional, max number of samples to consider
+
"""
# patches reader
self.patches_reader = patches_reader
# If necessary, limit the nb of samples
logging.info('Number of samples: %s', self.patches_reader.get_size())
- if max_nb_of_samples and self.patches_reader.get_size() > max_nb_of_samples:
+ if max_nb_of_samples and \
+ self.patches_reader.get_size() > max_nb_of_samples:
logging.info('Reducing number of samples to %s', max_nb_of_samples)
self.size = max_nb_of_samples
else:
self.size = self.patches_reader.get_size()
# iterator
- self.iterator = Iterator(patches_reader=self.patches_reader)
+ self.iterator = iterator_cls(patches_reader=self.patches_reader)
# Get patches sizes and type, of the first sample of the first tile
- self.output_types = dict()
- self.output_shapes = dict()
+ self.output_types = {}
+ self.output_shapes = {}
one_sample = self.patches_reader.get_sample(index=0)
for src_key, np_arr in one_sample.items():
self.output_shapes[src_key] = np_arr.shape
@@ -378,39 +505,60 @@ class Dataset:
self._dump()
# Prepare tf dataset for one epoch
- self.tf_dataset = tf.data.Dataset.from_generator(self._generator,
- output_types=self.output_types,
- output_shapes=self.output_shapes).repeat(1)
-
- def to_tfrecords(self, output_dir, n_samples_per_shard=100, drop_remainder=True):
+ self.tf_dataset = tf.data.Dataset.from_generator(
+ self._generator,
+ output_types=self.output_types,
+ output_shapes=self.output_shapes
+ ).repeat(1)
+
+ def to_tfrecords(
+ self,
+ output_dir: str,
+ n_samples_per_shard: int = 100,
+ drop_remainder: bool = True
+ ):
"""
Save the dataset into TFRecord files
- :param output_dir: output directory
- :param n_samples_per_shard: number of samples per TFRecord file
- :param drop_remainder: drop remainder samples
+ Params:
+ output_dir: output directory
+ n_samples_per_shard: number of samples per TFRecord file
+ drop_remainder: drop remaining samples
+
"""
- tfrecord = TFRecords(output_dir)
- tfrecord.ds2tfrecord(self, n_samples_per_shard=n_samples_per_shard, drop_remainder=drop_remainder)
+ tfrecord = otbtf.tfrecords.TFRecords(output_dir)
+ tfrecord.ds2tfrecord(
+ self,
+ n_samples_per_shard=n_samples_per_shard,
+ drop_remainder=drop_remainder
+ )
- def get_stats(self) -> dict:
+ def get_stats(self) -> Dict[str, List[float]]:
"""
Compute dataset statistics
- :return: the dataset statistics, computed by the patches reader
+ Return:
+ the dataset statistics, computed by the patches reader
+
"""
with self.mining_lock:
return self.patches_reader.get_stats()
- def read_one_sample(self):
+ def read_one_sample(self) -> Dict[str, Any]:
"""
Read one element of the consumer_buffer
- The lock is used to prevent different threads to read and update the internal counter concurrently
+ The lock is used to prevent different threads to read and update the
+ internal counter concurrently
+
+ Return:
+ one sample
+
"""
with self.read_lock:
output = None
if self.consumer_buffer_pos < self.consumer_buffer.max_length:
- output = self.consumer_buffer.container[self.consumer_buffer_pos]
+ output = self.consumer_buffer.container[
+ self.consumer_buffer_pos]
self.consumer_buffer_pos += 1
if self.consumer_buffer_pos == self.consumer_buffer.max_length:
self._dump()
@@ -419,7 +567,9 @@ class Dataset:
def _dump(self):
"""
- This function dumps the miner_buffer into the consumer_buffer, and restart the miner_thread
+ This function dumps the miner_buffer into the consumer_buffer, and
+ restarts the miner_thread
+
"""
# Wait for miner to finish his job
date_t = time.time()
@@ -439,6 +589,7 @@ class Dataset:
"""
This function collects samples.
It is threaded by the miner_thread.
+
"""
# Fill the miner_container until it's full
while not self.miner_buffer.is_complete():
@@ -447,7 +598,7 @@ class Dataset:
new_sample = self.patches_reader.get_sample(index=index)
self.miner_buffer.add(new_sample)
- def _summon_miner_thread(self):
+ def _summon_miner_thread(self) -> threading.Thread:
"""
Create and starts the thread for the data collect
"""
@@ -462,52 +613,80 @@ class Dataset:
for _ in range(self.size):
yield self.read_one_sample()
- def get_tf_dataset(self, batch_size, drop_remainder=True, preprocessing_fn=None, targets_keys=None):
+ def get_tf_dataset(
+ self,
+ batch_size: int,
+ drop_remainder: bool = True,
+ preprocessing_fn: Callable = None,
+ targets_keys: List[str] = None
+ ) -> tf.data.Dataset:
"""
Returns a TF dataset, ready to be used with the provided batch size
- :param batch_size: the batch size
- :param drop_remainder: drop incomplete batches
- :param preprocessing_fn: Optional. A preprocessing function that takes input examples as args and returns the
- preprocessed input examples. Typically, examples are composed of model inputs and
- targets. Model inputs and model targets must be computed accordingly to (1) what the
- model outputs and (2) what training loss needs. For instance, for a classification
- problem, the model will likely output the softmax, or activation neurons, for each
- class, and the cross entropy loss requires labels in one hot encoding. In this case,
- the preprocessing_fn has to transform the labels values (integer ranging from
- [0, n_classes]) in one hot encoding (vector of 0 and 1 of length n_classes). The
- preprocessing_fn should not implement such things as radiometric transformations from
- input to input_preprocessed, because those are performed inside the model itself
- (see `otbtf.ModelBase.normalize_inputs()`).
- :param targets_keys: Optional. When provided, the dataset returns a tuple of dicts (inputs_dict, target_dict) so
- it can be straightforwardly used with keras models objects.
- :return: The TF dataset
+
+ Params:
+ batch_size: the batch size
+ drop_remainder: drop incomplete batches
+ preprocessing_fn: An optional preprocessing function that takes
+ input examples as args and returns the preprocessed input
+ examples. Typically, examples are composed of model inputs and
+ targets. Model inputs and model targets must be computed
+ accordingly to (1) what the model outputs and (2) what
+ training loss needs. For instance, for a classification
+ problem, the model will likely output the softmax, or
+ activation neurons, for each class, and the cross entropy loss
+ requires labels in one hot encoding. In this case, the
+ preprocessing_fn has to transform the labels values (integer
+ ranging from [0, n_classes]) in one hot encoding (vector of 0
+ and 1 of length n_classes). The preprocessing_fn should not
+ implement such things as radiometric transformations from
+ input to input_preprocessed, because those are performed
+ inside the model itself (see
+ `otbtf.ModelBase.normalize_inputs()`).
+ targets_keys: Optional. When provided, the dataset returns a tuple
+ of dicts (inputs_dict, target_dict) so it can be
+ straightforwardly used with keras models objects.
+
+ Returns:
+ The TF dataset
+
"""
if 2 * batch_size >= self.miner_buffer.max_length:
- logging.warning("Batch size is %s but dataset buffer has %s elements. Consider using a larger dataset "
- "buffer to avoid I/O bottleneck", batch_size, self.miner_buffer.max_length)
- tf_ds = self.tf_dataset.map(preprocessing_fn) if preprocessing_fn else self.tf_dataset
+ logging.warning(
+ "Batch size is %s but dataset buffer has %s elements. "
+ "Consider using a larger dataset buffer to avoid I/O "
+ "bottleneck", batch_size, self.miner_buffer.max_length
+ )
+ tf_ds = self.tf_dataset.map(preprocessing_fn) \
+ if preprocessing_fn else self.tf_dataset
if targets_keys:
def _split_input_and_target(example):
# Differentiating inputs and outputs for keras
- inputs = {key: value for (key, value) in example.items() if key not in targets_keys}
- targets = {key: value for (key, value) in example.items() if key in targets_keys}
+ inputs = {
+ key: value for (key, value) in example.items()
+ if key not in targets_keys
+ }
+ targets = {
+ key: value for (key, value) in example.items()
+ if key in targets_keys
+ }
return inputs, targets
tf_ds = tf_ds.map(_split_input_and_target)
return tf_ds.batch(batch_size, drop_remainder=drop_remainder)
- def get_total_wait_in_seconds(self):
+ def get_total_wait_in_seconds(self) -> int:
"""
- Returns the number of seconds during which the data gathering was delayed because of I/O bottleneck
- :return: duration in seconds
+ Returns the number of seconds during which the data gathering was
+ delayed because I/O bottleneck
+
+ Returns:
+ duration in seconds
"""
return self.tot_wait
-# ----------------------------------------- DatasetFromPatchesImages class ---------------------------------------------
-
class DatasetFromPatchesImages(Dataset):
"""
Handles the "mining" of a set of patches images.
@@ -516,19 +695,38 @@ class DatasetFromPatchesImages(Dataset):
:see Dataset
"""
- def __init__(self, filenames_dict, use_streaming=False, buffer_length: int = 128,
- Iterator=RandomIterator):
- """
- :param filenames_dict: A dict() structured as follow:
- {src_name1: [src1_patches_image1, ..., src1_patches_imageN1],
- src_name2: [src2_patches_image2, ..., src2_patches_imageN2],
- ...
- src_nameM: [srcM_patches_image1, ..., srcM_patches_imageNM]}
- :param use_streaming: if True, the patches are read on the fly from the disc, nothing is kept in memory.
- :param buffer_length: The number of samples that are stored in the buffer (used when "use_streaming" is True).
- :param Iterator: The iterator class used to generate the sequence of patches indices.
+ def __init__(
+ self,
+ filenames_dict: Dict[str, List[str]],
+ use_streaming: bool = False,
+ buffer_length: int = 128,
+ iterator_cls=RandomIterator
+ ):
+ """
+ Params:
+ filenames_dict: A dict structured as follow:
+ {
+ src_name1: [src1_patches_image1, ..., src1_patches_imageN1],
+ src_name2: [src2_patches_image2, ..., src2_patches_imageN2],
+ ...
+ src_nameM: [srcM_patches_image1, ..., srcM_patches_imageNM]
+ }
+ use_streaming: if True, the patches are read on the fly from the disc,
+ nothing is kept in memory.
+ buffer_length: The number of samples that are stored in the buffer
+ (used when "use_streaming" is True).
+ iterator_cls: The iterator class used to generate the sequence of
+ patches indices.
+
"""
# patches reader
- patches_reader = PatchesImagesReader(filenames_dict=filenames_dict, use_streaming=use_streaming)
-
- super().__init__(patches_reader=patches_reader, buffer_length=buffer_length, Iterator=Iterator)
+ patches_reader = PatchesImagesReader(
+ filenames_dict=filenames_dict,
+ use_streaming=use_streaming
+ )
+
+ super().__init__(
+ patches_reader=patches_reader,
+ buffer_length=buffer_length,
+ iterator_cls=iterator_cls
+ )
diff --git a/otbtf/examples/__init__.py b/otbtf/examples/__init__.py
new file mode 100644
index 00000000..c49c8f05
--- /dev/null
+++ b/otbtf/examples/__init__.py
@@ -0,0 +1,4 @@
+"""
+# Examples
+
+"""
diff --git a/otbtf/examples/tensorflow_v1x/__init__.py b/otbtf/examples/tensorflow_v1x/__init__.py
new file mode 100644
index 00000000..c77256a4
--- /dev/null
+++ b/otbtf/examples/tensorflow_v1x/__init__.py
@@ -0,0 +1,456 @@
+"""
+
+This section provides some examples of ready-to-use deep learning
+architectures built with the TensorFlow API v1 from python.
+
+!!! warning
+
+ This section is no longer maintained. We recommend to build and train
+ models using Keras, which has become the primary interface for Tensorflow
+ after version 2.0 (see OTBTF [Python API](#api_tutorial.html)).
+
+ However, while we recommend to use the Tensorflow API v2, the following
+ examples are great to understand how the models work, in particular in
+ inference mode. Models based on the Tensorflow API v1 can be trained easily
+ with the `TensorflowModelTrain` application, which allows beginners to
+ focus more on the overall process rather than the code.
+ Besides, some people still stick with the Tensorflow v1 API: this section
+
+
+**Table of Contents**
+
+1. [Simple CNN](#simple-cnn)
+2. [Fully convolutional network](#fully-convolutional-network)
+3. [M3Fusion Model](#m3fusion-model)
+4. [Maggiori model](#maggiori-model)
+5. [Fully convolutional network with separate channels](#fully-convolutional-network-with-separate-channels)
+
+# Simple CNN
+
+[Source code :fontawesome-brands-github:](https://github.com/remicres/otbtf/blob/develop/otbtf/examples/tensorflow_v1x/create_savedmodel_simple_cnn.py){ .md-button }
+
+This simple model estimates the class of an input patch of image.
+This model consists in successive convolutions/pooling/relu of the input (*x* placeholder).
+At some point, the feature map is connected to a dense layer which has N neurons, N being the number of classes we want.
+The training operator (*optimizer* node) performs the gradient descent of the loss function corresponding to the cross entropy of (the softmax of) the N neurons output and the reference labels (*y* placeholder).
+Predicted label is the argmax of the N neurons (*prediction* tensor).
+Predicted label is a single pixel, for an input patch of size 16x16 (for an input *x* of size 16x16, the *prediction* has a size of 1x1).
+The learning rate of the training operator can be adjusted using the *lr* placeholder.
+The following figure summarizes this architecture.
+
+<img src ="https://gitlab.irstea.fr/remi.cresson/otbtf/-/raw/develop/doc/images/savedmodel_simple_cnn.png" />
+
+## Generate the model
+
+Use the python script to generate the SavedModel that will be used by OTBTF applications.
+
+```
+python create_savedmodel_simple_cnn.py --outdir $modeldir
+```
+
+Note that you can adjust the number of classes for the model with the `--nclasses` option.
+
+!!! Warning
+
+ If you take a look in *create_savedmode_simple_cnn.py*, you will notice
+ that the `tricks` module is imported at the top of the file.
+ `tricks` is here for backward compatibility with codes based on
+ OTBTF<3.0, and might be deleted in future releases.
+
+## Train the model with the CLI
+
+Use **TensorflowModelTrain** in the command line interface to train this model.
+
+```commandLine
+otbcli_TensorflowModelTrain \\
+-model.dir $modeldir \\
+-model.saveto "$modeldir/variables/variables" \\
+-training.source1.il $patches_train -training.source1.placeholder "x" \\
+-training.source1.patchsizex 1 -training.source1.patchsizey 1 \\
+-training.source2.il $labels_train -training.source2.placeholder "y" \\
+-training.source2.patchsizex 1 -training.source2.patchsizey 1 \\
+-training.targetnodes "optimizer" \\
+-validation.mode "class" \\
+-validation.source1.il $patches_valid -validation.source1.name "x" \\
+-validation.source2.il $labels_valid -validation.source2.name "prediction"
+```
+
+Type `otbcli_TensorflowModelTrain --help` to display the help.
+
+You can change the number of epochs to 50 with `-training.epochs 50` or you
+can change the batch size to 8 with `-training.batchsize 8`.
+In addition, it is possible to feed some scalar values to scalar placeholder
+of the model (currently, bool, int and float are supported).
+For instance, our model has a placeholder called *lr* that controls the
+learning rate of the optimizer.
+We can change this value at runtime using
+`-training.userplaceholders "lr=0.0002"`
+
+## Inference
+
+This model can be used either in patch-based mode or in fully convolutional
+mode.
+
+### Patch-based mode
+
+You can estimate the class of every pixels of your input image.
+Since the model is able to estimate the class of the center value of a 16x16
+patch, you can run the model over the whole image in patch-based mode.
+
+```
+otbcli_TensorflowModelServe \\
+-source1.il $image" \\
+-source1.rfieldx 16 \\
+-source1.rfieldy 16 \\
+-source1.placeholder "x" \\
+-model.dir $modeldir \\
+-output.names "prediction" \\
+-out $output_classif
+```
+
+However, patch-based approach is slow because each patch is processed
+independently, which is not computationally efficient.
+
+### Fully convolutional mode
+
+In fully convolutional mode, the model is used to process larger blocks in
+order to estimate simultaneously multiple pixels classes.
+The model has a total number of 4 strides (caused by pooling).
+Hence the physical spacing of the features maps, in spatial dimensions, is
+divided by 4. This is what is called *spcscale* in the
+**TensorflowModelServe** application.
+If you want to use the model in fully convolutional mode, you have to tell
+**TensorflowModelServe** that the model performs a change of physical spacing
+of the output, 4 in our case.
+
+```commandLine
+otbcli_TensorflowModelServe \\
+-source1.il $image" \\
+-source1.rfieldx 16 \\
+-source1.rfieldy 16 \\
+-source1.placeholder "x" \\
+-output.names "prediction" \\
+-output.spcscale 4 \\
+-model.dir $modeldir \\
+-model.fullyconv on \\
+-out $output_classif_fcn
+```
+
+# Fully convolutional network
+
+[Source code :fontawesome-brands-github:](https://github.com/remicres/otbtf/blob/develop/otbtf/examples/tensorflow_v1x/create_savedmodel_simple_fcn.py){ .md-button }
+
+The `create_savedmodel_simple_fcn.py` script enables you to create a fully
+convolutional model which does not use any stride.
+
+<img src ="https://gitlab.irstea.fr/remi.cresson/otbtf/-/raw/develop/doc/images/savedmodel_simple_fcnn.png" />
+
+Thanks to that, once trained this model can be applied on the image to produce
+a landcover map at the same resolution as the input image, in a fully
+convolutional (i.e. fast) manner.
+The main difference with the model described in the previous section is
+the *spcscale* parameter that must be let to default (i.e. unitary).
+
+Create the SavedModel:
+
+```commandLine
+python create_savedmodel_simple_fcn.py --outdir $modeldir
+```
+
+Then, train it as we saw before.
+Then you can produce the land cover map at pixel level in fully convolutional
+mode:
+
+```commandLine
+otbcli_TensorflowModelServe \\
+-source1.il $image" \\
+-source1.rfieldx 16 \\
+-source1.rfieldy 16 \\
+-source1.placeholder "x" \\
+-output.names "prediction" \\
+-model.dir $modeldir \\
+-model.fullyconv on \\
+-out $output_classif
+```
+
+# M3Fusion Model
+
+[Source code :fontawesome-brands-github:](https://github.com/remicres/otbtf/blob/develop/otbtf/examples/tensorflow_v1x/create_savedmodel_ienco-m3_patchbased.py){ .md-button }
+
+The M3Fusion model (stands for MultiScale/Multimodal/Multitemporal satellite
+data fusion) is a model designed to input time series and very high resolution
+images.
+
+Benedetti, P., Ienco, D., Gaetano, R., Ose, K., Pensa, R. G., & Dupuy, S.
+(2018). *M3Fusion: A Deep Learning Architecture for Multiscale Multimodal
+Multitemporal Satellite Data Fusion*. IEEE Journal of Selected Topics in
+Applied Earth Observations and Remote Sensing, 11(12), 4939-4949.
+
+See the original paper [here](https://arxiv.org/pdf/1803.01945).
+
+The M3 model is patch-based, and process two input sources simultaneously:
+(i) time series, and (ii) a very high resolution image.
+The output class estimation is performed at pixel level.
+
+## Generate the model
+
+```
+python create_savedmodel_ienco-m3_patchbased.py --outdir $modeldir
+```
+
+Note that you can adjust the number of classes for the model with the
+`--nclasses` parameter.
+Type `python create_savedmodel_ienco-m3_patchbased.py --help` to see the other
+available parameters.
+
+## Train the model from the CLI
+
+Let's train the M3 model from time series (TS) and Very High Resolution
+Satellite (VHRS) patches images.
+
+<img src ="https://gitlab.irstea.fr/remi.cresson/otbtf/-/raw/develop/doc/images/model_training.png" />
+
+First, tell OTBTF that we want two sources: one for time series + one for
+VHR image
+
+```
+export OTB_TF_NSOURCES=2
+```
+
+Run the **TensorflowModelTrain** application of OTBTF.
+
+Note that for time series we could also have provided a list of images rather
+that a single big images stack (since "sourceX.il" is an input image list
+parameter).
+
+```
+otbcli_TensorflowModelTrain \\
+-model.dir $modeldir \\
+-model.saveto "$modeldir/variables/variables" \\
+-training.source1.il $patches_ts_train \\
+-training.source1.patchsizex 1 \\
+-training.source1.patchsizey 1 \\
+-training.source1.placeholder "x_rnn" \\
+-training.source2.il $patches_vhr_train \\
+-training.source2.patchsizex 25 \\
+-training.source2.patchsizey 25 \\
+-training.source2.placeholder "x_cnn" \\
+-training.source3.il $labels_train \\
+-training.source3.patchsizex 1 \\
+-training.source3.patchsizey 1 \\
+-training.source3.placeholder "y" \\
+-training.targetnodes "optimizer" \\
+-training.userplaceholders "is_training=true" "drop_rate=0.1" "learning_rate=0.0002" \\
+-validation.mode "class" -validation.step 1 \\
+-validation.source1.il $patches_ts_valid \\
+-validation.source1.name "x_rnn" \\
+-validation.source2.il $patches_vhr_valid \\
+-validation.source2.name "x_cnn" \\
+-validation.source3.il $labels_valid \\
+-validation.source3.name "prediction"
+```
+
+## Inference
+
+Let's produce a land cover map using the M3 model from time series (TS) and
+Very High Resolution Satellite image (VHRS)
+
+<img src ="https://gitlab.irstea.fr/remi.cresson/otbtf/-/raw/develop/doc/images/classif_map.png" />
+
+Since we provide time series as the reference source (*source1*), the output
+classes are estimated at the same resolution. This model can be run in
+patch-based mode only.
+
+```commandLine
+otbcli_TensorflowModelServe \\
+-source1.il $ts \\
+-source1.rfieldx 1 -source1.rfieldy 1 \\
+-source1.placeholder "x_rnn" \\
+-source2.il $vhr \\
+-source2.rfieldx 25 -source2.rfieldy 25 \\
+-source2.placeholder "x_cnn" \\
+-model.dir $modeldir \\
+-output.names "prediction" -out $output_classif
+```
+
+# Maggiori model
+
+[Source code :fontawesome-brands-github:](https://github.com/remicres/otbtf/blob/develop/otbtf/examples/tensorflow_v1x/create_savedmodel_maggiori17_fullyconv.py){ .md-button }
+
+This architecture was one of the first to introduce a fully convolutional
+model suited for large scale remote sensing images.
+
+Maggiori, E., Tarabalka, Y., Charpiat, G., & Alliez, P. (2016).
+*Convolutional neural networks for large-scale remote-sensing image
+classification*. IEEE Transactions on Geoscience and Remote Sensing, 55(2),
+645-657.
+
+See the original paper [here](https://hal.inria.fr/hal-01350706/document).
+This fully convolutional model performs binary semantic segmentation of large
+scale images without any blocking artifacts.
+
+## Generate the model
+
+```commandLine
+python create_savedmodel_maggiori17_fullyconv.py --outdir $modeldir
+```
+
+You can change the number of spectral bands of the input image that is
+processed with the model, using the `--n_channels` option.
+
+## Train the model
+
+The model perform the semantic segmentation from one single source.
+
+```commandLine
+otbcli_TensorflowModelTrain \\
+-model.dir $modeldir \\
+-model.saveto "$modeldir/variables/variables" \\
+-training.source1.il $patches_image_train \\
+-training.source1.patchsizex 80 -training.source1.patchsizey 80 \\
+-training.source1.placeholder "x" \\
+-training.source2.il $patches_labels_train \\
+-training.source2.patchsizex 16 -training.source2.patchsizey 16 \\
+-training.source2.placeholder "y" \\
+-training.targetnodes "optimizer" \\
+-training.userplaceholders "is_training=true" "learning_rate=0.0002" \\
+-validation.mode "class" -validation.step 1 \\
+-validation.source1.il $patches_image_valid \\
+-validation.source1.name "x" \\
+-validation.source2.il $patches_labels_valid \\
+-validation.source2.name "estimated"
+```
+
+Note that the `userplaceholders` parameter contains the *is_training*
+placeholder, fed with value *true* because the default value for this
+placeholder is *false*, and it is used in the batch normalization layers (take
+a look in the `create_savedmodel_maggiori17_fullyconv.py` code).
+
+## Inference
+
+This model can be used in fully convolutional mode only.
+This model performs convolutions with stride (i.e. downsampling), followed
+with transposed convolutions with strides (i.e. upsampling).
+Since there is no change of physical spacing (because downsampling and
+upsampling have both the same number of strides), the *spcscale* parameter is
+let to default (i.e. unitary).
+The receptive field of the model is 80x80, and the expression field is 16x16,
+due to the fact that the model keeps only the exact part of the output
+features maps.
+
+```
+otbcli_TensorflowModelServe \\
+-source1.il $image \\
+-source1.rfieldx 80 -source1.rfieldy 80 \\
+-source1.placeholder x \\
+-model.dir $modeldir \\
+-model.fullyconv on \\
+-output.names "estimated" \\
+-output.efieldx 16 -output.efieldy 16 \\
+-out $output_classif
+```
+
+# Fully convolutional network with separate channels
+
+[Source code :fontawesome-brands-github:](https://github.com/remicres/otbtf/blob/develop/otbtf/examples/tensorflow_v1x/create_savedmodel_pxs_fcn.py){ .md-button }
+
+It's common that very high resolution products are composed with a
+panchromatic channel at high-resolution (Pan), and a multispectral image
+generally at lower resolution (MS).
+This model inputs separately the two sources (Pan and MS) separately.
+
+See: Gaetano, R., Ienco, D., Ose, K., & Cresson, R. (2018). *A two-branch CNN
+architecture for land cover classification of PAN and MS imagery*. Remote
+Sensing, 10(11), 1746.
+
+<img src ="https://gitlab.irstea.fr/remi.cresson/otbtf/-/raw/develop/doc/images/savedmodel_simple_pxs_fcn.png" />
+
+Use `create_savedmodel_pxs_fcn.py` to generate this model.
+
+During training, the *x1* and *x2* placeholders must be fed respectively with
+patches of size 8x8 and 32x32.
+You can use this model in a fully convolutional way with receptive field of
+size 32 (for the Pan image) and 8 (for the MS image) and an unitary expression
+field (i.e. equal to 1).
+Don't forget to tell OTBTF that we want two sources: one for Ms image + one
+for Pan image
+
+```
+export OTB_TF_NSOURCES=2
+```
+
+## Inference at MS image resolution
+
+Here we perform the land cover map at the same resolution as the MS image.
+Do do this, we set the MS image as the first source in the **TensorflowModelServe** application.
+
+```
+otbcli_TensorflowModelServe \\
+-source1.il $ms \\
+-source1.rfieldx 8 -source1.rfieldy 8 \\
+-source1.placeholder "x1" \\
+-source2.il $pan \\
+-source2.rfieldx 32 -source2.rfieldy 32 \\
+-source2.placeholder "x2" \\
+-model.dir $modeldir \\
+-model.fullyconv on \\
+-output.names "prediction" \\
+-out $output_classif
+```
+
+Note that we could also have set the Pan image as the first source, and tell
+the application to use a *spcscale* of 4.
+```
+otbcli_TensorflowModelServe \\
+-source1.il $pan \\
+-source1.rfieldx 32 -source1.rfieldy 32 \\
+-source1.placeholder "x2" \\
+-source2.il $ms \\
+-source2.rfieldx 8 -source2.rfieldy 8 \\
+-source2.placeholder "x1" \\
+-model.dir $modeldir \\
+-model.fullyconv on \\
+-output.names "prediction" \\
+-output.spcscale 4 \\
+-out $output_classif
+```
+
+## Inference at Pan image resolution
+
+Here we perform the land cover map at the same resolution as the Pan image.
+Do do this, we set the Pan image as the first source in the
+**TensorflowModelServe** application.
+Note that this model can not be applied in a fully convolutional fashion at
+the Pan image resolution.
+We hence perform the processing in patch-based mode.
+
+```
+otbcli_TensorflowModelServe \\
+-source1.il $pan \\
+-source1.rfieldx 32 -source1.rfieldy 32 \\
+-source1.placeholder "x2" \\
+-source2.il $ms \\
+-source2.rfieldx 8 -source2.rfieldy 8 \\
+-source2.placeholder "x1" \\
+-model.dir $modeldir \\
+-output.names "prediction" \\
+-out $output_classif
+```
+
+Note that we could also have set the MS image as the first source, and tell
+the application to use a *spcscale* of 0.25.
+
+```
+otbcli_TensorflowModelServe \\
+-source1.il $ms \\
+-source1.rfieldx 8 -source1.rfieldy 8 \\
+-source1.placeholder "x1" \\
+-source2.il $pan \\
+-source2.rfieldx 32 -source2.rfieldy 32 \\
+-source2.placeholder "x2" \\
+-model.dir $modeldir \\
+-model.fullyconv on \\
+-output.names "prediction" \\
+-out $output_classif
+```
+"""
diff --git a/otbtf/examples/tensorflow_v1x/create_savedmodel_ienco-m3_patchbased.py b/otbtf/examples/tensorflow_v1x/create_savedmodel_ienco-m3_patchbased.py
index 2a3ad56f..1edfe44d 100755
--- a/otbtf/examples/tensorflow_v1x/create_savedmodel_ienco-m3_patchbased.py
+++ b/otbtf/examples/tensorflow_v1x/create_savedmodel_ienco-m3_patchbased.py
@@ -21,29 +21,19 @@
# Reference:
#
-# Benedetti, P., Ienco, D., Gaetano, R., Ose, K., Pensa, R. G., & Dupuy, S. (2018)
-# M3Fusion: A Deep Learning Architecture for Multiscale Multimodal Multitemporal
-# Satellite Data Fusion. IEEE Journal of Selected Topics in Applied Earth
-# Observations and Remote Sensing, 11(12), 4939-4949.
+# Benedetti, P., Ienco, D., Gaetano, R., Ose, K., Pensa, R. G., & Dupuy, S.
+# (2018) M3Fusion: A Deep Learning Architecture for Multiscale Multimodal
+# Multitemporal Satellite Data Fusion. IEEE Journal of Selected Topics in
+# Applied Earth Observations and Remote Sensing, 11(12), 4939-4949.
import argparse
-from tricks import create_savedmodel
+
import tensorflow.compat.v1 as tf
import tensorflow.compat.v1.nn.rnn_cell as rnn
-tf.disable_v2_behavior()
+from tricks import create_savedmodel
-parser = argparse.ArgumentParser()
-parser.add_argument("--nunits", type=int, default=1024, help="number of units")
-parser.add_argument("--n_levels_lstm", type=int, default=1, help="number of lstm levels")
-parser.add_argument("--hm_epochs", type=int, default=400, help="hm epochs")
-parser.add_argument("--n_timestamps", type=int, default=37, help="number of images in timeseries")
-parser.add_argument("--n_dims", type=int, default=16, help="number of channels in timeseries images")
-parser.add_argument("--patch_window", type=int, default=25, help="patch size for the high-res image")
-parser.add_argument("--n_channels", type=int, default=4, help="number of channels in the high-res image")
-parser.add_argument("--nclasses", type=int, default=8, help="number of classes")
-parser.add_argument("--outdir", help="Output directory for SavedModel", required=True)
-params = parser.parse_args()
+tf.disable_v2_behavior()
def RnnAttention(x, nunits, nlayer, n_dims, n_timetamps, is_training_ph):
@@ -53,10 +43,12 @@ def RnnAttention(x, nunits, nlayer, n_dims, n_timetamps, is_training_ph):
# (before unstack) x is 1 tensor of shape [N, n_dims, n_timestamps]
x = tf.unstack(x, n_timetamps, axis=2)
- # (after unstack) x is a list of "n_timestamps" tensors of shape: [N, n_dims]
+ # (after unstack) x is a list of "n_timestamps" tensors of shape:
+ # [N, n_dims]
# NETWORK DEF
- # MORE THEN ONE LAYER: list of LSTMcell,nunits hidden units each, for each layer
+ # MORE THEN ONE LAYER: list of LSTMcell,nunits hidden units each, for
+ # each layer
if nlayer > 1:
cells = []
for _ in range(nlayer):
@@ -73,14 +65,17 @@ def RnnAttention(x, nunits, nlayer, n_dims, n_timetamps, is_training_ph):
# Trainable parameters
attention_size = nunits # int(nunits / 2)
- W_omega = tf.Variable(tf.random_normal([nunits, attention_size], stddev=0.1))
+ W_omega = tf.Variable(
+ tf.random_normal([nunits, attention_size], stddev=0.1))
b_omega = tf.Variable(tf.random_normal([attention_size], stddev=0.1))
u_omega = tf.Variable(tf.random_normal([attention_size], stddev=0.1))
- # Applying fully connected layer with non-linear activation to each of the B*T timestamps;
+ # Applying fully connected layer with non-linear activation to each of
+ # the B*T timestamps;
# the shape of `v` is (B,T,D)*(D,A)=(B,T,A), where A=attention_size
v = tf.tanh(tf.tensordot(outputs, W_omega, axes=1) + b_omega)
- # For each of the timestamps its vector of size A from `v` is reduced with `u` vector
+ # For each of the timestamps its vector of size A from `v` is reduced
+ # with `u` vector
vu = tf.tensordot(v, u_omega, axes=1) # (B,T) shape
alphas = tf.nn.softmax(vu) # (B,T) shape also
@@ -102,14 +97,17 @@ def CNN(x, nunits):
conv1 = tf.compat.v1.layers.batch_normalization(conv1)
- pool1 = tf.compat.v1.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
+ pool1 = tf.compat.v1.layers.max_pooling2d(
+ inputs=conv1, pool_size=[2, 2], strides=2
+ )
conv2 = tf.compat.v1.layers.conv2d(
inputs=pool1,
filters=nunits,
kernel_size=[3, 3],
padding="valid",
- activation=tf.nn.relu)
+ activation=tf.nn.relu
+ )
conv2 = tf.compat.v1.layers.batch_normalization(conv2)
@@ -118,7 +116,8 @@ def CNN(x, nunits):
filters=nunits,
kernel_size=[3, 3],
padding="same",
- activation=tf.nn.relu)
+ activation=tf.nn.relu
+ )
conv3 = tf.compat.v1.layers.batch_normalization(conv3)
@@ -129,7 +128,8 @@ def CNN(x, nunits):
filters=nunits,
kernel_size=[1, 1],
padding="valid",
- activation=tf.nn.relu)
+ activation=tf.nn.relu
+ )
conv4 = tf.compat.v1.layers.batch_normalization(conv4)
@@ -140,8 +140,18 @@ def CNN(x, nunits):
return cnn, tensor_shape[1].value
-def get_prediction(x_rnn, x_cnn, nunits, nlayer, nclasses, n_dims, n_timetamps):
- vec_rnn = RnnAttention(x_rnn, nunits, nlayer, n_dims, n_timetamps, is_training_ph)
+def get_prediction(
+ x_rnn,
+ x_cnn,
+ nunits,
+ nlayer,
+ nclasses,
+ n_dims,
+ n_timetamps
+):
+ vec_rnn = RnnAttention(
+ x_rnn, nunits, nlayer, n_dims, n_timetamps, is_training_ph
+ )
vec_cnn, cnn_dim = CNN(x_cnn, 512)
features_learnt = tf.concat([vec_rnn, vec_cnn], axis=1, name="features")
@@ -165,48 +175,144 @@ def get_prediction(x_rnn, x_cnn, nunits, nlayer, nclasses, n_dims, n_timetamps):
return pred_c1, pred_c2, pred_full, features_learnt
-# Create the TensorFlow graph
-with tf.compat.v1.Graph().as_default():
- x_rnn = tf.compat.v1.placeholder(tf.float32, [None, 1, 1, params.n_dims * params.n_timestamps], name="x_rnn")
- x_cnn = tf.compat.v1.placeholder(tf.float32, [None, params.patch_window, params.patch_window, params.n_channels],
- name="x_cnn")
- y = tf.compat.v1.placeholder(tf.int32, [None, 1, 1, 1], name="y")
-
- learning_rate = tf.compat.v1.placeholder_with_default(tf.constant(0.0002, dtype=tf.float32, shape=[]), shape=[],
- name="learning_rate")
- is_training_ph = tf.compat.v1.placeholder_with_default(tf.constant(False, dtype=tf.bool, shape=[]), shape=[],
- name="is_training")
- dropout = tf.compat.v1.placeholder_with_default(tf.constant(0.5, dtype=tf.float32, shape=[]), shape=[],
- name="drop_rate")
-
- pred_c1, pred_c2, pred_full, features_learnt = get_prediction(x_rnn,
- x_cnn,
- params.nunits,
- params.n_levels_lstm,
- params.nclasses,
- params.n_dims,
- params.n_timestamps)
-
- testPrediction = tf.argmax(pred_full, 1, name="prediction")
-
- loss_full = tf.compat.v1.losses.sparse_softmax_cross_entropy(labels=tf.reshape(y, [-1, 1]),
- logits=tf.reshape(pred_full, [-1, params.nclasses]))
- loss_c1 = tf.compat.v1.losses.sparse_softmax_cross_entropy(labels=tf.reshape(y, [-1, 1]),
- logits=tf.reshape(pred_c1, [-1, params.nclasses]))
- loss_c2 = tf.compat.v1.losses.sparse_softmax_cross_entropy(labels=tf.reshape(y, [-1, 1]),
- logits=tf.reshape(pred_c2, [-1, params.nclasses]))
-
- cost = loss_full + (0.3 * loss_c1) + (0.3 * loss_c2)
-
- optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate, name="optimizer").minimize(cost)
-
- correct = tf.equal(tf.argmax(pred_full, 1), tf.argmax(y, 1))
- accuracy = tf.reduce_mean(tf.cast(correct, tf.float64))
-
- # Initializer, saver, session
- init = tf.compat.v1.global_variables_initializer()
- saver = tf.compat.v1.train.Saver(max_to_keep=20)
- sess = tf.compat.v1.Session()
- sess.run(init)
-
- create_savedmodel(sess, ["x_cnn:0", "x_rnn:0", "y:0"], ["prediction:0"], params.outdir)
+# if __name__ == __main__:
+# parser = argparse.ArgumentParser()
+# parser.add_argument(
+# "--nunits",
+# type=int,
+# default=1024,
+# help="number of units"
+# )
+# parser.add_argument(
+# "--n_levels_lstm",
+# type=int,
+# default=1,
+# help="number of lstm levels"
+# )
+# parser.add_argument(
+# "--hm_epochs",
+# type=int,
+# default=400,
+# help="hm epochs"
+# )
+# parser.add_argument(
+# "--n_timestamps",
+# type=int,
+# default=37,
+# help="number of images in timeseries"
+# )
+# parser.add_argument(
+# "--n_dims",
+# type=int,
+# default=16,
+# help="number of channels in timeseries images"
+# )
+# parser.add_argument(
+# "--patch_window",
+# type=int,
+# default=25,
+# help="patch size for the high-res image"
+# )
+# parser.add_argument(
+# "--n_channels",
+# type=int,
+# default=4,
+# help="number of channels in the high-res image"
+# )
+# parser.add_argument(
+# "--nclasses",
+# type=int,
+# default=8,
+# help="number of classes"
+# )
+# parser.add_argument(
+# "--outdir",
+# help="Output directory for SavedModel",
+# required=True
+# )
+# params = parser.parse_args()
+#
+# # Create the TensorFlow graph
+# with tf.compat.v1.Graph().as_default():
+# x_rnn = tf.compat.v1.placeholder(
+# tf.float32,
+# [None, 1, 1, params.n_dims * params.n_timestamps],
+# name="x_rnn"
+# )
+# x_cnn = tf.compat.v1.placeholder(
+# tf.float32,
+# [None, params.patch_window, params.patch_window,
+# params.n_channels],
+# name="x_cnn"
+# )
+# y = tf.compat.v1.placeholder(tf.int32, [None, 1, 1, 1], name="y")
+#
+# learning_rate = tf.compat.v1.placeholder_with_default(
+# tf.constant(
+# 0.0002,
+# dtype=tf.float32,
+# shape=[]
+# ),
+# shape=[],
+# name="learning_rate"
+# )
+# is_training_ph = tf.compat.v1.placeholder_with_default(
+# tf.constant(
+# False,
+# dtype=tf.bool,
+# shape=[]
+# ),
+# shape=[],
+# name="is_training"
+# )
+# dropout = tf.compat.v1.placeholder_with_default(
+# tf.constant(
+# 0.5,
+# dtype=tf.float32,
+# shape=[]
+# ), shape=[],
+# name="drop_rate"
+# )
+#
+# pred_c1, pred_c2, pred_full, features_learnt = get_prediction(
+# x_rnn,
+# x_cnn,
+# params.nunits,
+# params.n_levels_lstm,
+# params.nclasses,
+# params.n_dims,
+# params.n_timestamps
+# )
+#
+# testPrediction = tf.argmax(pred_full, 1, name="prediction")
+#
+# loss_full = tf.compat.v1.losses.sparse_softmax_cross_entropy(
+# labels=tf.reshape(y, [-1, 1]),
+# logits=tf.reshape(pred_full, [-1, params.nclasses]))
+# loss_c1 = tf.compat.v1.losses.sparse_softmax_cross_entropy(
+# labels=tf.reshape(y, [-1, 1]),
+# logits=tf.reshape(pred_c1, [-1, params.nclasses]))
+# loss_c2 = tf.compat.v1.losses.sparse_softmax_cross_entropy(
+# labels=tf.reshape(y, [-1, 1]),
+# logits=tf.reshape(pred_c2, [-1, params.nclasses]))
+#
+# cost = loss_full + (0.3 * loss_c1) + (0.3 * loss_c2)
+#
+# optimizer = tf.compat.v1.train.AdamOptimizer(
+# learning_rate=learning_rate,
+# name="optimizer"
+# ).minimize(cost)
+#
+# correct = tf.equal(tf.argmax(pred_full, 1), tf.argmax(y, 1))
+# accuracy = tf.reduce_mean(tf.cast(correct, tf.float64))
+#
+# # Initializer, saver, session
+# init = tf.compat.v1.global_variables_initializer()
+# saver = tf.compat.v1.train.Saver(max_to_keep=20)
+# sess = tf.compat.v1.Session()
+# sess.run(init)
+#
+# create_savedmodel(
+# sess, ["x_cnn:0", "x_rnn:0", "y:0"], ["prediction:0"],
+# params.outdir
+# )
diff --git a/otbtf/examples/tensorflow_v2x/__init__.py b/otbtf/examples/tensorflow_v2x/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/otbtf/examples/tensorflow_v2x/deterministic/__init__.py b/otbtf/examples/tensorflow_v2x/deterministic/__init__.py
new file mode 100644
index 00000000..d0ec3db4
--- /dev/null
+++ b/otbtf/examples/tensorflow_v2x/deterministic/__init__.py
@@ -0,0 +1,95 @@
+"""
+[Source code :fontawesome-brands-github:](https://github.com/remicres/otbtf/
+tree/master/otbtf/examples/tensorflow_v2x/deterministic){ .md-button }
+
+This section contains two examples of very simple models that are not
+trainable, called **deterministic models**.
+Sometimes it can be useful to consider deterministic approaches (e.g. modeling)
+and tensorflow is a powerful numerical library that can run smoothly on many
+kind of devices such as GPUs.
+
+In this section, we will consider two deterministic models:
+
+- [L2 norm](#l2-norm): a model that computes the l2 norm of the input image
+channels, for each pixel,
+- [Scalar product](#scalar-product): a model computing the scalar product
+between two images with the same number of channels, for each pixel
+
+# L2 norm
+
+We consider a very simple model that implements the computation of the l2 norm.
+The model inputs one multispectral image (*x*), and computes the l2 norm of
+each pixel (*y*). The model is exported as a SavedModel named
+*l2_norm_savedmodel*
+
+```python
+import tensorflow as tf
+
+# Input
+x = tf.keras.Input(shape=[None, None, None], name="x") # [1, h, w, N]
+
+# Compute norm on the last axis
+y = tf.norm(x, axis=-1)
+
+# Create model
+model = tf.keras.Model(inputs={"x": x}, outputs={"y": y})
+model.save("l2_norm_savedmodel")
+```
+
+Run the code. The *l2_norm_savedmodel* file is created.
+Now run the SavedModel with `TensorflowModelServe`:
+
+```commandline
+otbcli_TensorflowModelServe \\
+-source1.il image1.tif \\
+-model.dir l2_norm_savedmodel \\
+-model.fullyconv on \\
+-out output.tif \\
+-optim.disabletiling on
+```
+
+!!! Note
+
+ As you can notice, we have set the `optim.disabletiling` to `on` which
+ disables the tiling for the processing. This means that OTB will drive the
+ regions size based on the ram value defined in OTB. We can do that safely
+ since our process has a small memory footprint, and it is not optimized
+ with tiling because it does not use any neighborhood based approach.
+ Tiling is enabled by default in `TensorflowModelServe` since it is mostly
+ intended to perform inference using 2D convolutions.
+
+# Scalar product
+
+Let's consider a simple model that inputs two multispectral image (*x1* and
+*x2*), and computes the scalar product between each pixels of the two images.
+The model is exported as a SavedModel named *scalar_product_savedmodel*
+
+```python
+import tensorflow as tf
+
+# Input
+x1 = tf.keras.Input(shape=[None, None, None], name="x1") # [1, h, w, N]
+x2 = tf.keras.Input(shape=[None, None, None], name="x2") # [1, h, w, N]
+
+# Compute scalar product
+y = tf.reduce_sum(tf.multiply(x1, x2), axis=-1)
+
+# Create model
+model = tf.keras.Model(inputs={"x1": x1, "x2": x2}, outputs={"y": y})
+model.save("scalar_product_savedmodel")
+```
+
+Run the code. The *scalar_product_savedmodel* file is created.
+Now run the SavedModel with `TensorflowModelServe`:
+
+```commandline
+OTB_TF_NSOURCES=2 otbcli_TensorflowModelServe \\
+-source1.il image1.tif \\
+-source2.il image2.tif \\
+-model.dir scalar_product_savedmodel \\
+-model.fullyconv on \\
+-out output.tif \\
+-optim.disabletiling on # Small memory footprint, we can remove tiling
+```
+
+"""
diff --git a/otbtf/examples/tensorflow_v2x/l2_norm.py b/otbtf/examples/tensorflow_v2x/deterministic/l2_norm.py
similarity index 71%
rename from otbtf/examples/tensorflow_v2x/l2_norm.py
rename to otbtf/examples/tensorflow_v2x/deterministic/l2_norm.py
index a98e9a64..b23d86cb 100644
--- a/otbtf/examples/tensorflow_v2x/l2_norm.py
+++ b/otbtf/examples/tensorflow_v2x/deterministic/l2_norm.py
@@ -2,15 +2,17 @@
This code implements a simple model that inputs one multispectral image ("x"),
and computes the euclidean norm of each pixel ("y").
The model is exported as a SavedModel named "l2_norm_savedmodel"
-
To run the SavedModel:
-otbcli_TensorflowModelServe \
--source1.il image1.tif \
+```
+otbcli_TensorflowModelServe \
+-source1.il image1.tif \
-model.dir l2_norm_savedmodel \
--model.fullyconv on \
--out output.tif \
--optim.disabletiling on # Tiling is not helping here, since its a pixel wise op.
+-model.fullyconv on \
+-out output.tif \
+-optim.disabletiling on # Tiling is not helping here (it is a pixel wise op)
+```
+
"""
import tensorflow as tf
diff --git a/otbtf/examples/tensorflow_v2x/scalar_product.py b/otbtf/examples/tensorflow_v2x/deterministic/scalar_prod.py
similarity index 65%
rename from otbtf/examples/tensorflow_v2x/scalar_product.py
rename to otbtf/examples/tensorflow_v2x/deterministic/scalar_prod.py
index dc67a322..57127c5e 100644
--- a/otbtf/examples/tensorflow_v2x/scalar_product.py
+++ b/otbtf/examples/tensorflow_v2x/deterministic/scalar_prod.py
@@ -1,17 +1,20 @@
"""
-This code implements a simple model that inputs two multispectral image ("x1" and "x2"),
+This code implements a simple model that inputs two multispectral image ("x1"
+and "x2"),
and computes the scalar product between each pixels of the two images.
The model is exported as a SavedModel named "scalar_product_savedmodel"
-
To run the SavedModel:
+```
OTB_TF_NSOURCES=2 otbcli_TensorflowModelServe \
--source1.il image1.tif \
--source2.il image2.tif \
--model.dir scalar_product_savedmodel \
--model.fullyconv on \
--out output.tif \
--optim.disabletiling on # Tiling is not helping here, since its a pixel wise op.
+-source1.il image1.tif \
+-source2.il image2.tif \
+-model.dir scalar_product_savedmodel \
+-model.fullyconv on \
+-out output.tif \
+-optim.disabletiling on # (Tiling is not helping here, it is a pixel wise op)
+```
+
"""
import tensorflow as tf
diff --git a/otbtf/examples/tensorflow_v2x/fcnn/README.md b/otbtf/examples/tensorflow_v2x/fcnn/README.md
deleted file mode 100644
index e6cfce78..00000000
--- a/otbtf/examples/tensorflow_v2x/fcnn/README.md
+++ /dev/null
@@ -1,64 +0,0 @@
-This example show how to train a small fully convolutional model using the
-OTBTF python API. In particular, the example show how a model can be trained
-(1) from **patches-images**, or (2) from **TFRecords** files.
-
-# Files
-
-- `fcnn_model.py` implements a small fully convolutional U-Net like model,
-with the preprocessing and normalization functions
-- `train_from_patches-images.py` shows how to train the model from a list of
-patches-images
-- `train_from_tfrecords.py` shows how to train the model from TFRecords files
-- `create_tfrecords.py` shows how to convert patch-images into TFRecords files
-- `helper.py` contains a few helping functions
-
-# Patches-images vs TFRecords based datasets
-
-TensorFlow datasets are the most practical way to feed a network data during
-training steps.
-In particular, they are very useful to train models with data parallelism using
-multiple workers (i.e. multiple GPU devices).
-Since OTBTF 3, two kind of approaches are available to deliver the patches:
-- Create TF datasets from **patches-images**: the first approach implemented in
-OTBTF, relying on geospatial raster formats supported by GDAL. Patches are simply
-stacked in rows. patches-images are friendly because they can be visualized
-like any other image. However this approach is **not very optimized**, since it
-generates a lot of I/O and stresses the filesystem when iterating randomly over
-patches.
-- Create TF datasets from **TFRecords** files. The principle is that a number of
-patches are stored in TFRecords files (google protubuf serialized data). This
-approach provides the best performances, since it generates less I/Os since
-multiple patches are read simultaneously together. It is the recommended approach
-to work on high end gear. It requires an additional step of converting the
-patches-images into TFRecords files.
-
-## Patches-images based datasets
-
-**Patches-images** are generated from the `PatchesExtraction` application of OTBTF.
-They consist in extracted patches stacked in rows into geospatial rasters.
-The `otbtf.DatasetFromPatchesImages` provides access to **patches-images** as a
-TF dataset. It inherits from the `otbtf.Dataset` class, which can be a base class
-to develop other raster based datasets.
-The `use_streaming` option can be used to read the patches on-the-fly
-on the filesystem. However, this can cause I/O bottleneck when one training step
-is shorter that fetching one batch of data. Typically, this is very common with
-small networks trained over large amount of data using multiple GPUs, causing the
-filesystem read operation being the weak point (and the GPUs wait for the batches
-to be ready). The class offers other functionalities, for instance changing the
-iterator class with a custom one (can inherit from `otbtf.dataset.IteratorBase`)
-which is, by default, an `otbtf.dataset.RandomIterator`. This could enable to
-control how the patches are walked, from the multiple patches-images of the
-dataset.
-
-## TFRecords batches datasets
-
-**TFRecord** based datasets are implemented in the `otbtf.tfrecords` module.
-They basically deliver patches from the TFRecords files, which can be created
-with the `to_tfrecords()` method of the `otbtf.Dataset` based classes.
-Depending on the filesystem characteristics and the computational cost of one
-training step, it can be good to select the number of samples per TFRecords file.
-Another tweak is the shuffling: since one TFRecord file contains multiple patches,
-the way TFRecords files are accessed (sometimes, we need them to be randomly
-accessed), and the way patches are accessed (within a buffer, of size set with the
-`shuffle_buffer_size`), is crucial.
-
diff --git a/otbtf/examples/tensorflow_v2x/fcnn/__init__.py b/otbtf/examples/tensorflow_v2x/fcnn/__init__.py
new file mode 100644
index 00000000..7aa1b166
--- /dev/null
+++ b/otbtf/examples/tensorflow_v2x/fcnn/__init__.py
@@ -0,0 +1,4 @@
+"""
+Example showing how to work with a small fully convolutional network from
+patches extracted in images.
+"""
diff --git a/otbtf/examples/tensorflow_v2x/fcnn/create_tfrecords.py b/otbtf/examples/tensorflow_v2x/fcnn/create_tfrecords.py
index 51043ef1..2acb0ae9 100644
--- a/otbtf/examples/tensorflow_v2x/fcnn/create_tfrecords.py
+++ b/otbtf/examples/tensorflow_v2x/fcnn/create_tfrecords.py
@@ -1,20 +1,42 @@
"""
-This example shows how to convert patches-images (like the ones generated from the `PatchesExtraction`)
-into TFRecords files.
+This example shows how to convert patches-images (like the ones generated from
+the `PatchesExtraction`) into TFRecords files.
"""
import argparse
from pathlib import Path
-from otbtf.examples.tensorflow_v2x.fcnn import helper
+
from otbtf import DatasetFromPatchesImages
+from otbtf.examples.tensorflow_v2x.fcnn import helper
-parser = argparse.ArgumentParser(description="Converts patches-images into TFRecords")
-parser.add_argument("--xs", required=True, nargs="+", default=[], help="A list of patches-images for the XS image")
-parser.add_argument("--labels", required=True, nargs="+", default=[],
- help="A list of patches-images for the labels")
-parser.add_argument("--outdir", required=True, help="Output dir for TFRecords files")
+parser = argparse.ArgumentParser(
+ description="Converts patches-images into TFRecords"
+)
+parser.add_argument(
+ "--xs",
+ required=True,
+ nargs="+",
+ default=[],
+ help="A list of patches-images for the XS image"
+)
+parser.add_argument(
+ "--labels",
+ required=True,
+ nargs="+",
+ default=[],
+ help="A list of patches-images for the labels"
+)
+parser.add_argument(
+ "--outdir",
+ required=True,
+ help="Output dir for TFRecords files"
+)
def create_tfrecords(params):
+ """
+ Create TFRecords.
+
+ """
# Sort patches and labels
patches = sorted(params.xs)
labels = sorted(params.labels)
@@ -28,12 +50,16 @@ def create_tfrecords(params):
outdir.mkdir(exist_ok=True)
# Create dataset from the filename dict
- dataset = DatasetFromPatchesImages(filenames_dict={"input_xs_patches": patches, "labels_patches": labels})
+ dataset = DatasetFromPatchesImages(
+ filenames_dict={
+ "input_xs_patches": patches,
+ "labels_patches": labels
+ }
+ )
# Convert the dataset into TFRecords
dataset.to_tfrecords(output_dir=params.outdir, drop_remainder=False)
if __name__ == "__main__":
- params = parser.parse_args()
- create_tfrecords(params)
+ create_tfrecords(parser.parse_args())
diff --git a/otbtf/examples/tensorflow_v2x/fcnn/fcnn_model.py b/otbtf/examples/tensorflow_v2x/fcnn/fcnn_model.py
index 95f2d017..44285d92 100644
--- a/otbtf/examples/tensorflow_v2x/fcnn/fcnn_model.py
+++ b/otbtf/examples/tensorflow_v2x/fcnn/fcnn_model.py
@@ -1,15 +1,30 @@
"""
Implementation of a small U-Net like model
"""
-from otbtf.model import ModelBase
-import tensorflow as tf
import logging
-logging.basicConfig(format='%(asctime)s %(levelname)-8s %(message)s', level=logging.INFO, datefmt='%Y-%m-%d %H:%M:%S')
+import tensorflow as tf
+
+from otbtf.model import ModelBase
+
+logging.basicConfig(
+ format='%(asctime)s %(levelname)-8s %(message)s',
+ level=logging.INFO,
+ datefmt='%Y-%m-%d %H:%M:%S'
+)
+
+# Number of classes estimated by the model
N_CLASSES = 2
-INPUT_NAME = "input_xs" # name of the input in the `FCNNModel` instance, also name of the input node in the SavedModel
-TARGET_NAME = "predictions" # name of the output in the `FCNNModel` instance
-OUTPUT_SOFTMAX_NAME = "predictions_softmax_tensor" # name (prefix) of the output node in the SavedModel
+
+# Name of the input in the `FCNNModel` instance, also name of the input node
+# in the SavedModel
+INPUT_NAME = "input_xs"
+
+# Name of the output in the `FCNNModel` instance
+TARGET_NAME = "predictions"
+
+# Name (prefix) of the output node in the SavedModel
+OUTPUT_SOFTMAX_NAME = "predictions_softmax_tensor"
class FCNNModel(ModelBase):
@@ -17,42 +32,65 @@ class FCNNModel(ModelBase):
A Simple Fully Convolutional U-Net like model
"""
- def normalize_inputs(self, inputs):
+ def normalize_inputs(self, inputs: dict):
"""
Inherits from `ModelBase`
- The model will use this function internally to normalize its inputs, before applying the `get_outputs()`
- function that actually builds the operations graph (convolutions, etc).
- This function will hence work at training time and inference time.
+ The model will use this function internally to normalize its inputs,
+ before applying `get_outputs()` that actually builds the operations
+ graph (convolutions, etc). This function will hence work at training
+ time and inference time.
- In this example, we assume that we have an input 12 bits multispectral image with values ranging from
- [0, 10000], that we process using a simple stretch to roughly match the [0, 1] range.
+ In this example, we assume that we have an input 12 bits multispectral
+ image with values ranging from [0, 10000], that we process using a
+ simple stretch to roughly match the [0, 1] range.
- :param inputs: dict of inputs
- :return: dict of normalized inputs, ready to be used from the `get_outputs()` function of the model
+ Params:
+ inputs: dict of inputs
+
+ Returns:
+ dict of normalized inputs, ready to be used from `get_outputs()`
"""
return {INPUT_NAME: tf.cast(inputs[INPUT_NAME], tf.float32) * 0.0001}
- def get_outputs(self, normalized_inputs):
+ def get_outputs(self, normalized_inputs: dict) -> dict:
"""
Inherits from `ModelBase`
- This small model produces an output which has the same physical spacing as the input.
- The model generates [1 x 1 x N_CLASSES] output pixel for [32 x 32 x <nb channels>] input pixels.
+ This small model produces an output which has the same physical
+ spacing as the input. The model generates [1 x 1 x N_CLASSES] output
+ pixel for [32 x 32 x <nb channels>] input pixels.
+
+ Params:
+ normalized_inputs: dict of normalized inputs
- :param normalized_inputs: dict of normalized inputs`
- :return: activation values
+ Returns:
+ dict of model outputs
"""
norm_inp = normalized_inputs[INPUT_NAME]
def _conv(inp, depth, name):
- return tf.keras.layers.Conv2D(filters=depth, kernel_size=3, strides=2, activation="relu",
- padding="same", name=name)(inp)
+ conv_op = tf.keras.layers.Conv2D(
+ filters=depth,
+ kernel_size=3,
+ strides=2,
+ activation="relu",
+ padding="same",
+ name=name
+ )
+ return conv_op(inp)
def _tconv(inp, depth, name, activation="relu"):
- return tf.keras.layers.Conv2DTranspose(filters=depth, kernel_size=3, strides=2, activation=activation,
- padding="same", name=name)(inp)
+ tconv_op = tf.keras.layers.Conv2DTranspose(
+ filters=depth,
+ kernel_size=3,
+ strides=2,
+ activation=activation,
+ padding="same",
+ name=name
+ )
+ return tconv_op(inp)
out_conv1 = _conv(norm_inp, 16, "conv1")
out_conv2 = _conv(out_conv1, 32, "conv2")
@@ -63,63 +101,85 @@ class FCNNModel(ModelBase):
out_tconv3 = _tconv(out_tconv2, 16, "tconv3") + out_conv1
out_tconv4 = _tconv(out_tconv3, N_CLASSES, "classifier", None)
- # Generally it is a good thing to name the final layers of the network (i.e. the layers of which outputs are
- # returned from the `MyModel.get_output()` method).
- # Indeed this enables to retrieve them for inference time, using their name.
- # In case your forgot to name the last layers, it is still possible to look at the model outputs using the
- # `saved_model_cli show --dir /path/to/your/savedmodel --all` command.
+ # Generally it is a good thing to name the final layers of the network
+ # (i.e. the layers of which outputs are returned from
+ # `MyModel.get_output()`). Indeed this enables to retrieve them for
+ # inference time, using their name. In case your forgot to name the
+ # last layers, it is still possible to look at the model outputs using
+ # the `saved_model_cli show --dir /path/to/your/savedmodel --all`
+ # command.
#
- # Do not confuse **the name of the output layers** (i.e. the "name" property of the tf.keras.layer that is used
- # to generate an output tensor) and **the key of the output tensor**, in the dict returned from the
- # `MyModel.get_output()` method. They are two identifiers with a different purpose:
- # - the output layer name is used only at inference time, to identify the output tensor from which generate
- # the output image,
- # - the output tensor key identifies the output tensors, mainly to fit the targets to model outputs during
- # training process, but it can also be used to access the tensors as tf/keras objects, for instance to
- # display previews images in TensorBoard.
- predictions = tf.keras.layers.Softmax(name=OUTPUT_SOFTMAX_NAME)(out_tconv4)
+ # Do not confuse **the name of the output layers** (i.e. the "name"
+ # property of the tf.keras.layer that is used to generate an output
+ # tensor) and **the key of the output tensor**, in the dict returned
+ # from `MyModel.get_output()`. They are two identifiers with a
+ # different purpose:
+ # - the output layer name is used only at inference time, to identify
+ # the output tensor from which generate the output image,
+ # - the output tensor key identifies the output tensors, mainly to
+ # fit the targets to model outputs during training process, but it
+ # can also be used to access the tensors as tf/keras objects, for
+ # instance to display previews images in TensorBoard.
+ softmax_op = tf.keras.layers.Softmax(name=OUTPUT_SOFTMAX_NAME)
+ predictions = softmax_op(out_tconv4)
return {TARGET_NAME: predictions}
-def dataset_preprocessing_fn(examples):
+def dataset_preprocessing_fn(examples: dict):
"""
Preprocessing function for the training dataset.
- This function is only used at training time, to put the data in the expected format for the training step.
- DO NOT USE THIS FUNCTION TO NORMALIZE THE INPUTS ! (see `otbtf.ModelBase.normalize_inputs` for that).
- Note that this function is not called here, but in the code that prepares the datasets.
+ This function is only used at training time, to put the data in the
+ expected format for the training step.
+ DO NOT USE THIS FUNCTION TO NORMALIZE THE INPUTS ! (see
+ `otbtf.ModelBase.normalize_inputs` for that).
+ Note that this function is not called here, but in the code that prepares
+ the datasets.
- :param examples: dict for examples (i.e. inputs and targets stored in a single dict)
- :return: preprocessed examples
- """
+ Params:
+ examples: dict for examples (i.e. inputs and targets stored in a single
+ dict)
- def _to_categorical(x):
- return tf.one_hot(tf.squeeze(tf.cast(x, tf.int32), axis=-1), depth=N_CLASSES)
+ Returns:
+ preprocessed examples
- return {INPUT_NAME: examples["input_xs_patches"],
- TARGET_NAME: _to_categorical(examples["labels_patches"])}
+ """
+ return {
+ INPUT_NAME: examples["input_xs_patches"],
+ TARGET_NAME: tf.one_hot(
+ tf.squeeze(tf.cast(examples["labels_patches"], tf.int32), axis=-1),
+ depth=N_CLASSES
+ )
+ }
def train(params, ds_train, ds_valid, ds_test):
"""
Create, train, and save the model.
- :param params: contains batch_size, learning_rate, nb_epochs, and model_dir
- :param ds_train: training dataset
- :param ds_valid: validation dataset
- :param ds_test: testing dataset
+ Params:
+ params: contains batch_size, learning_rate, nb_epochs, and model_dir
+ ds_train: training dataset
+ ds_valid: validation dataset
+ ds_test: testing dataset
+
"""
strategy = tf.distribute.MirroredStrategy() # For single or multi-GPUs
with strategy.scope():
- # Model instantiation. Note that the normalize_fn is now part of the model
- # It is mandatory to instantiate the model inside the strategy scope.
+ # Model instantiation. Note that the normalize_fn is now part of the
+ # model. It is mandatory to instantiate the model inside the strategy
+ # scope.
model = FCNNModel(dataset_element_spec=ds_train.element_spec)
# Compile the model
- model.compile(loss=tf.keras.losses.CategoricalCrossentropy(),
- optimizer=tf.keras.optimizers.Adam(learning_rate=params.learning_rate),
- metrics=[tf.keras.metrics.Precision(), tf.keras.metrics.Recall()])
+ model.compile(
+ loss=tf.keras.losses.CategoricalCrossentropy(),
+ optimizer=tf.keras.optimizers.Adam(
+ learning_rate=params.learning_rate
+ ),
+ metrics=[tf.keras.metrics.Precision(), tf.keras.metrics.Recall()]
+ )
# Summarize the model (in CLI)
model.summary()
diff --git a/otbtf/examples/tensorflow_v2x/fcnn/helper.py b/otbtf/examples/tensorflow_v2x/fcnn/helper.py
index aea3a0ac..cec3d5c1 100644
--- a/otbtf/examples/tensorflow_v2x/fcnn/helper.py
+++ b/otbtf/examples/tensorflow_v2x/fcnn/helper.py
@@ -8,30 +8,43 @@ def base_parser():
"""
Create a parser with the base parameters for the training applications
- :return: argparse.ArgumentParser instance
+ Returns:
+ argparse.ArgumentParser instance
+
"""
parser = argparse.ArgumentParser(description="Train a FCNN model")
- parser.add_argument("--batch_size", type=int, default=8, help="Batch size")
- parser.add_argument("--learning_rate", type=float, default=0.0001, help="Learning rate")
- parser.add_argument("--nb_epochs", type=int, default=100, help="Number of epochs")
- parser.add_argument("--model_dir", required=True, help="Path to save model")
+ parser.add_argument(
+ "--batch_size", type=int, default=8, help="Batch size"
+ )
+ parser.add_argument(
+ "--learning_rate", type=float, default=0.0001, help="Learning rate"
+ )
+ parser.add_argument(
+ "--nb_epochs", type=int, default=100, help="Number of epochs"
+ )
+ parser.add_argument(
+ "--model_dir", required=True, help="Path to save model"
+ )
return parser
def check_files_order(files1, files2):
"""
Here we check that the two input lists of str are correctly sorted.
- Except for the last, splits of files1[i] and files2[i] from the "_" character, must be equal.
+ Except for the last, splits of files1[i] and files2[i] from the "_"
+ character, must be equal.
+
+ Params:
+ files1: list of filenames (str)
+ files2: list of filenames (str)
- :param files1: list of filenames (str)
- :param files2: list of filenames (str)
"""
assert files1
assert files2
assert len(files1) == len(files2)
- def get_basename(n):
- return "_".join([n.split("_")][:-1])
+ def get_basename(filename):
+ return "_".join([filename.split("_")][:-1])
- for p, l in zip(files1, files2):
- assert get_basename(p) == get_basename(l)
+ for file1, file2 in zip(files1, files2):
+ assert get_basename(file1) == get_basename(file2)
diff --git a/otbtf/examples/tensorflow_v2x/fcnn/train_from_patchesimages.py b/otbtf/examples/tensorflow_v2x/fcnn/train_from_patchesimages.py
index 9299c9e0..9dab4b9b 100644
--- a/otbtf/examples/tensorflow_v2x/fcnn/train_from_patchesimages.py
+++ b/otbtf/examples/tensorflow_v2x/fcnn/train_from_patchesimages.py
@@ -1,28 +1,65 @@
"""
-This example shows how to use the otbtf python API to train a deep net from patches-images.
+This example shows how to use the otbtf python API to train a deep net from
+patches-images.
"""
from otbtf import DatasetFromPatchesImages
-from otbtf.examples.tensorflow_v2x.fcnn import helper
from otbtf.examples.tensorflow_v2x.fcnn import fcnn_model
+from otbtf.examples.tensorflow_v2x.fcnn import helper
parser = helper.base_parser()
-parser.add_argument("--train_xs", required=True, nargs="+", default=[],
- help="A list of patches-images for the XS image (training dataset)")
-parser.add_argument("--train_labels", required=True, nargs="+", default=[],
- help="A list of patches-images for the labels (training dataset)")
-parser.add_argument("--valid_xs", required=True, nargs="+", default=[],
- help="A list of patches-images for the XS image (validation dataset)")
-parser.add_argument("--valid_labels", required=True, nargs="+", default=[],
- help="A list of patches-images for the labels (validation dataset)")
-parser.add_argument("--test_xs", required=False, nargs="+", default=[],
- help="A list of patches-images for the XS image (test dataset)")
-parser.add_argument("--test_labels", required=False, nargs="+", default=[],
- help="A list of patches-images for the labels (test dataset)")
-
-
-def create_dataset(xs_filenames, labels_filenames, batch_size, targets_keys=[fcnn_model.TARGET_NAME]):
+parser.add_argument(
+ "--train_xs",
+ required=True,
+ nargs="+",
+ default=[],
+ help="A list of patches-images for the XS image (training dataset)"
+)
+parser.add_argument(
+ "--train_labels",
+ required=True,
+ nargs="+",
+ default=[],
+ help="A list of patches-images for the labels (training dataset)"
+)
+parser.add_argument(
+ "--valid_xs",
+ required=True,
+ nargs="+",
+ default=[],
+ help="A list of patches-images for the XS image (validation dataset)"
+)
+parser.add_argument(
+ "--valid_labels",
+ required=True,
+ nargs="+",
+ default=[],
+ help="A list of patches-images for the labels (validation dataset)"
+)
+parser.add_argument(
+ "--test_xs",
+ required=False,
+ nargs="+",
+ default=[],
+ help="A list of patches-images for the XS image (test dataset)"
+)
+parser.add_argument(
+ "--test_labels",
+ required=False,
+ nargs="+",
+ default=[],
+ help="A list of patches-images for the labels (test dataset)"
+)
+
+
+def create_dataset(
+ xs_filenames: list,
+ labels_filenames: list,
+ batch_size: int,
+ targets_keys: list = None
+):
"""
- Returns a TF dataset generated from an `otbtf.DatasetFromPatchesImages` instance
+ Returns a TF dataset generated from an `otbtf.DatasetFromPatchesImages`
+ instance
"""
# Sort patches and labels
xs_filenames.sort()
@@ -32,27 +69,48 @@ def create_dataset(xs_filenames, labels_filenames, batch_size, targets_keys=[fcn
helper.check_files_order(xs_filenames, labels_filenames)
# Create dataset from the filename dict
- # You can add the `use_streaming` option here, is you want to lower the memory budget.
- # However, this can slow down your process since the patches are read on-the-fly on the filesystem.
- # Good when one batch computation is slower than one batch gathering!
- # You can also use a custom `Iterator` of your own (default is `RandomIterator`). See `otbtf.dataset.Iterator`.
- ds = DatasetFromPatchesImages(filenames_dict={"input_xs_patches": xs_filenames, "labels_patches": labels_filenames})
-
- # We generate the TF dataset, and we use a preprocessing option to put the labels into one hot encoding (see the
- # `fcnn_model.dataset_preprocessing_fn` function). Also, we set the `target_keys` parameter to ask the dataset to
- # deliver samples in the form expected by keras, i.e. a tuple of dicts (inputs_dict, target_dict).
- tf_ds = ds.get_tf_dataset(batch_size=batch_size, preprocessing_fn=fcnn_model.dataset_preprocessing_fn,
- targets_keys=targets_keys)
+ # You can add the `use_streaming` option here, is you want to lower the
+ # memory budget. However, this can slow down your process since the
+ # patches are read on-the-fly on the filesystem. Good when one batch
+ # computation is slower than one batch gathering! You can also use a
+ # custom `Iterator` of your own (default is `RandomIterator`).
+ # See `otbtf.dataset.Iterator`.
+ dataset = DatasetFromPatchesImages(
+ filenames_dict={
+ "input_xs_patches": xs_filenames,
+ "labels_patches": labels_filenames
+ }
+ )
+
+ # We generate the TF dataset, and we use a preprocessing option to put the
+ # labels in one hot encoding (see `fcnn_model.dataset_preprocessing_fn()`).
+ # Also, we set the `target_keys` parameter to ask the dataset to deliver
+ # samples in the form expected by keras, i.e. a tuple of dicts
+ # (inputs_dict, target_dict).
+ tf_ds = dataset.get_tf_dataset(
+ batch_size=batch_size,
+ preprocessing_fn=fcnn_model.dataset_preprocessing_fn,
+ targets_keys=targets_keys or [fcnn_model.TARGET_NAME]
+ )
return tf_ds
def train(params):
+ """
+ Train from patches images.
+
+ """
# Create TF datasets
- ds_train = create_dataset(params.train_xs, params.train_labels, batch_size=params.batch_size)
- ds_valid = create_dataset(params.valid_xs, params.valid_labels, batch_size=params.batch_size)
- ds_test = create_dataset(params.test_xs, params.test_labels,
- batch_size=params.batch_size) if params.test_xs else None
+ ds_train = create_dataset(
+ params.train_xs, params.train_labels, batch_size=params.batch_size
+ )
+ ds_valid = create_dataset(
+ params.valid_xs, params.valid_labels, batch_size=params.batch_size
+ )
+ ds_test = create_dataset(
+ params.test_xs, params.test_labels, batch_size=params.batch_size
+ ) if params.test_xs else None
# Train the model
fcnn_model.train(params, ds_train, ds_valid, ds_test)
diff --git a/otbtf/examples/tensorflow_v2x/fcnn/train_from_tfrecords.py b/otbtf/examples/tensorflow_v2x/fcnn/train_from_tfrecords.py
index 3fbfe472..caf15a79 100644
--- a/otbtf/examples/tensorflow_v2x/fcnn/train_from_tfrecords.py
+++ b/otbtf/examples/tensorflow_v2x/fcnn/train_from_tfrecords.py
@@ -1,8 +1,10 @@
"""
-This example shows how to use the otbtf python API to train a deep net from TFRecords.
+This example shows how to use the otbtf python API to train a deep net from
+TFRecords.
-We expect that the files are stored in the following way, with m, n, and k denoting respectively
-the number of TFRecords files in the training, validation, and test datasets:
+We expect that the files are stored in the following way, with m, n, and k
+denoting respectively the number of TFRecords files in the training,
+validation, and test datasets:
/dataset_dir
/train
@@ -23,24 +25,35 @@ the number of TFRecords files in the training, validation, and test datasets:
"""
import os
+
from otbtf import TFRecords
-from otbtf.examples.tensorflow_v2x.fcnn import helper
from otbtf.examples.tensorflow_v2x.fcnn import fcnn_model
+from otbtf.examples.tensorflow_v2x.fcnn import helper
parser = helper.base_parser()
-parser.add_argument("--tfrecords_dir", required=True,
- help="Directory containing train, valid(, test) folders of TFRecords files")
+parser.add_argument(
+ "--tfrecords_dir",
+ required=True,
+ help="Directory containing train, valid(, test) folders of TFRecords files"
+)
def train(params):
- # Patches directories must contain 'train' and 'valid' dirs ('test' is not required)
+ """
+ Train from TFRecords.
+
+ """
+ # Patches directories must contain 'train' and 'valid' dirs ('test' is not
+ # required)
train_dir = os.path.join(params.tfrecords_dir, "train")
valid_dir = os.path.join(params.tfrecords_dir, "valid")
test_dir = os.path.join(params.tfrecords_dir, "test")
- kwargs = {"batch_size": params.batch_size,
- "target_keys": [fcnn_model.TARGET_NAME],
- "preprocessing_fn": fcnn_model.dataset_preprocessing_fn}
+ kwargs = {
+ "batch_size": params.batch_size,
+ "target_keys": [fcnn_model.TARGET_NAME],
+ "preprocessing_fn": fcnn_model.dataset_preprocessing_fn
+ }
# Training dataset. Must be shuffled
assert os.path.isdir(train_dir)
@@ -51,7 +64,9 @@ def train(params):
ds_valid = TFRecords(valid_dir).read(**kwargs)
# Test dataset (optional)
- ds_test = TFRecords(test_dir).read(**kwargs) if os.path.isdir(test_dir) else None
+ ds_test = TFRecords(test_dir).read(**kwargs) if os.path.isdir(
+ test_dir
+ ) else None
# Train the model
fcnn_model.train(params, ds_train, ds_valid, ds_test)
diff --git a/otbtf/model.py b/otbtf/model.py
index e11f2e44..b3ee7b92 100644
--- a/otbtf/model.py
+++ b/otbtf/model.py
@@ -1,8 +1,34 @@
# -*- coding: utf-8 -*-
-""" Base class for models"""
+# ==========================================================================
+#
+# Copyright 2018-2019 IRSTEA
+# Copyright 2020-2023 INRAE
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0.txt
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+# ==========================================================================*/
+"""
+[Source code :fontawesome-brands-github:](https://github.com/remicres/otbtf/
+tree/master/otbtf/model.py){ .md-button }
+
+Base class for models.
+"""
+from typing import List, Dict, Any
import abc
import logging
-import tensorflow
+import tensorflow as tf
+
+TensorsDict = Dict[str, Any]
class ModelBase(abc.ABC):
@@ -10,45 +36,72 @@ class ModelBase(abc.ABC):
Base class for all models
"""
- def __init__(self, dataset_element_spec, input_keys=None, inference_cropping=None):
+ def __init__(
+ self,
+ dataset_element_spec: tf.TensorSpec,
+ input_keys: List[str] = None,
+ inference_cropping: List[int] = None
+ ):
"""
Model initializer, must be called **inside** the strategy.scope().
- :param dataset_element_spec: the dataset elements specification (shape, dtype, etc). Can be retrieved from the
- dataset instance simply with `ds.element_spec`
- :param input_keys: Optional. the keys of the inputs used in the model. If not specified, all inputs from the
- dataset will be considered.
- :param inference_cropping: list of number of pixels to be removed on each side of the output during inference.
- This list creates some additional outputs in the model, not used during training,
- only during inference. Default [16, 32, 64, 96, 128]
+ Args:
+ dataset_element_spec: the dataset elements specification (shape,
+ dtype, etc). Can be retrieved from a dataset instance `ds`
+ simply with `ds.element_spec`
+ input_keys: Optional keys of the inputs used in the model. If not
+ specified, all inputs from the dataset will be considered.
+ inference_cropping: list of number of pixels to be removed on each
+ side of the output for inference. Additional outputs are
+ created in the model, not used during training, only during
+ inference. Default [16, 32, 64, 96, 128]
+
"""
# Retrieve dataset inputs shapes
dataset_input_element_spec = dataset_element_spec[0]
- logging.info("Dataset input element spec: %s", dataset_input_element_spec)
+ logging.info(
+ "Dataset input element spec: %s", dataset_input_element_spec
+ )
if input_keys:
self.dataset_input_keys = input_keys
logging.info("Using input keys: %s", self.dataset_input_keys)
else:
self.dataset_input_keys = list(dataset_input_element_spec)
- logging.info("Found dataset input keys: %s", self.dataset_input_keys)
-
- self.inputs_shapes = {key: dataset_input_element_spec[key].shape[1:] for key in self.dataset_input_keys}
+ logging.info(
+ "Found dataset input keys: %s", self.dataset_input_keys
+ )
+
+ self.inputs_shapes = {
+ key: dataset_input_element_spec[key].shape[1:]
+ for key in self.dataset_input_keys
+ }
logging.info("Inputs shapes: %s", self.inputs_shapes)
# Setup cropping, normalization function
- self.inference_cropping = [16, 32, 64, 96, 128] if not inference_cropping else inference_cropping
+ self.inference_cropping = inference_cropping or [16, 32, 64, 96, 128]
logging.info("Inference cropping values: %s", self.inference_cropping)
# Create model
self.model = self.create_network()
- def __getattr__(self, name):
- """This method is called when the default attribute access fails. We choose to try to access the attribute of
- self.model. Thus, any method of keras.Model() can be used transparently, e.g. model.summary() or model.fit()"""
+ def __getattr__(self, name: str) -> Any:
+ """
+ This method is called when the default attribute access fails. We
+ choose to try to access the attribute of self.model. Thus, any method
+ of `keras.Model()` can be used transparently, e.g. `model.summary()`
+ or model.fit()
+
+ Args:
+ name: name of the attribute
+
+ Returns:
+ attribute
+
+ """
return getattr(self.model, name)
- def get_inputs(self):
+ def get_inputs(self) -> TensorsDict:
"""
This method returns the dict of keras.Input
"""
@@ -57,47 +110,72 @@ class ModelBase(abc.ABC):
for key in self.dataset_input_keys:
new_shape = list(self.inputs_shapes[key])
logging.info("Original shape for input %s: %s", key, new_shape)
- # Here we modify the x and y dims of >2D tensors to enable any image size at input
+ # Here we modify the x and y dims of >2D tensors to enable any
+ # image size at input
if len(new_shape) > 2:
new_shape[0] = None
new_shape[1] = None
- placeholder = tensorflow.keras.Input(shape=new_shape, name=key)
+ placeholder = tf.keras.Input(shape=new_shape, name=key)
logging.info("New shape for input %s: %s", key, new_shape)
model_inputs.update({key: placeholder})
return model_inputs
@abc.abstractmethod
- def get_outputs(self, normalized_inputs):
+ def get_outputs(self, normalized_inputs: TensorsDict) -> TensorsDict:
"""
Implementation of the model, from the normalized inputs.
- :param normalized_inputs: normalized inputs, as generated from `self.normalize_inputs()`
- :return: dict of model outputs
+ Params:
+ normalized_inputs: normalized inputs, as generated from
+ `self.normalize_inputs()`
+
+ Returns:
+ model outputs
+
"""
- raise NotImplementedError("This method has to be implemented. Here you code the model :)")
+ raise NotImplementedError(
+ "This method has to be implemented. Here you code the model :)"
+ )
- def normalize_inputs(self, inputs):
+ def normalize_inputs(self, inputs: TensorsDict) -> TensorsDict:
"""
Normalize the model inputs.
Takes the dict of inputs and returns a dict of normalized inputs.
- :param inputs: model inputs
- :return: a dict of normalized model inputs
+ Params:
+ inputs: model inputs
+
+ Returns:
+ a dict of normalized model inputs
+
"""
- logging.warning("normalize_input() undefined. No normalization of the model inputs will be performed. "
- "You can implement the function in your model class if you want.")
+ logging.warning(
+ "normalize_input() undefined. No normalization of the model "
+ "inputs will be performed. You can implement the function in your "
+ "model class if you want."
+ )
return inputs
- def postprocess_outputs(self, outputs, inputs=None, normalized_inputs=None):
+ def postprocess_outputs(
+ self,
+ outputs: TensorsDict,
+ inputs: TensorsDict = None,
+ normalized_inputs: TensorsDict = None
+ ) -> TensorsDict:
"""
Post-process the model outputs.
- Takes the dicts of inputs and outputs, and returns a dict of post-processed outputs.
- The default implementation provides a set of cropped output tensors
+ Takes the dicts of inputs and outputs, and returns a dict of
+ post-processed outputs.
+ The default implementation provides a set of cropped output tensors.
+
+ Params:
+ outputs: dict of model outputs
+ inputs: dict of model inputs (optional)
+ normalized_inputs: dict of normalized model inputs (optional)
+
+ Returns:
+ a dict of post-processed model outputs
- :param outputs: dict of model outputs
- :param inputs: dict of model inputs (optional)
- :param normalized_inputs: dict of normalized model inputs (optional)
- :return: a dict of post-processed model outputs
"""
# Add extra outputs for inference
@@ -105,20 +183,29 @@ class ModelBase(abc.ABC):
for out_key, out_tensor in outputs.items():
for crop in self.inference_cropping:
extra_output_key = cropped_tensor_name(out_key, crop)
- extra_output_name = cropped_tensor_name(out_tensor._keras_history.layer.name, crop)
- logging.info("Adding extra output for tensor %s with crop %s (%s)", out_key, crop, extra_output_name)
+ extra_output_name = cropped_tensor_name(
+ out_tensor._keras_history.layer.name, crop
+ )
+ logging.info(
+ "Adding extra output for tensor %s with crop %s (%s)",
+ out_key, crop, extra_output_name
+ )
cropped = out_tensor[:, crop:-crop, crop:-crop, :]
- identity = tensorflow.keras.layers.Activation('linear', name=extra_output_name)
+ identity = tf.keras.layers.Activation(
+ 'linear', name=extra_output_name
+ )
extra_outputs[extra_output_key] = identity(cropped)
return extra_outputs
- def create_network(self):
+ def create_network(self) -> tf.keras.Model:
"""
- This method returns the Keras model. This needs to be called **inside** the strategy.scope().
- Can be reimplemented depending on the needs.
+ This method returns the Keras model. This needs to be called
+ **inside** the strategy.scope(). Can be reimplemented depending on the
+ needs.
- :return: the keras model
+ Returns:
+ the keras model
"""
# Get the model inputs
@@ -134,45 +221,64 @@ class ModelBase(abc.ABC):
logging.info("Model outputs: %s", outputs)
# Post-processing for inference
- postprocessed_outputs = self.postprocess_outputs(outputs=outputs, inputs=inputs,
- normalized_inputs=normalized_inputs)
+ postprocessed_outputs = self.postprocess_outputs(
+ outputs=outputs,
+ inputs=inputs,
+ normalized_inputs=normalized_inputs
+ )
outputs.update(postprocessed_outputs)
# Return the keras model
- return tensorflow.keras.Model(inputs=inputs, outputs=outputs, name=self.__class__.__name__)
+ return tf.keras.Model(
+ inputs=inputs,
+ outputs=outputs,
+ name=self.__class__.__name__
+ )
def summary(self, strategy=None):
"""
- Wraps the summary printing of the model. When multiworker strategy, only prints if the worker is chief
+ Wraps the summary printing of the model. When multiworker strategy,
+ only prints if the worker is chief
+
+ Params:
+ strategy: strategy
- :param strategy: strategy
"""
if not strategy or _is_chief(strategy):
self.model.summary(line_length=150)
- def plot(self, output_path, strategy=None, show_shapes=False):
+ def plot(self, output_path: str, strategy=None, show_shapes: bool = False):
"""
Enables to save a figure representing the architecture of the network.
- Needs pydot and graphviz to work (`pip install pydot` and https://graphviz.gitlab.io/download/)
+ Needs pydot and graphviz to work (`pip install pydot` and
+ https://graphviz.gitlab.io/download/)
- :param output_path: output path for the schema
- :param strategy: strategy
- :param show_shapes: annotate with shapes values (True or False)
+ Params:
+ output_path: output path for the schema
+ strategy: strategy
+ show_shapes: annotate with shapes values (True or False)
"""
- assert self.model, "Plot() only works if create_network() has been called beforehand"
+ assert self.model, "Plot() only works if create_network() has been " \
+ "called beforehand"
# When multiworker strategy, only plot if the worker is chief
if not strategy or _is_chief(strategy):
- tensorflow.keras.utils.plot_model(self.model, output_path, show_shapes=show_shapes)
+ tf.keras.utils.plot_model(
+ self.model, output_path, show_shapes=show_shapes
+ )
def _is_chief(strategy):
"""
Tell if the current worker is the chief.
- :param strategy: strategy
- :return: True if the current worker is the chief, False else
+ Params:
+ strategy: strategy
+
+ Returns:
+ True if the current worker is the chief, False else
+
"""
# Note: there are two possible `TF_CONFIG` configuration.
# 1) In addition to `worker` tasks, a `chief` task type is use;
@@ -185,17 +291,25 @@ def _is_chief(strategy):
# is added because it is effectively run with only a single worker.
if strategy.cluster_resolver: # this means MultiWorkerMirroredStrategy
- task_type, task_id = strategy.cluster_resolver.task_type, strategy.cluster_resolver.task_id
- return (task_type == 'chief') or (task_type == 'worker' and task_id == 0) or task_type is None
+ task_type = strategy.cluster_resolver.task_type
+ task_id = strategy.cluster_resolver.task_id
+ return (task_type == 'chief') \
+ or (task_type == 'worker' and task_id == 0) \
+ or task_type is None
# strategy with only one worker
return True
-def cropped_tensor_name(tensor_name, crop):
+def cropped_tensor_name(tensor_name: str, crop: int):
"""
A name for the padded tensor
- :param tensor_name: tensor name
- :param pad: pad value
- :return: name
+
+ Params:
+ tensor_name: tensor name
+ crop: cropping value
+
+ Returns:
+ name for the cropped tensor
+
"""
- return "{}_crop{}".format(tensor_name, crop)
+ return f"{tensor_name}_crop{crop}"
diff --git a/otbtf/tfrecords.py b/otbtf/tfrecords.py
index 15a23354..e5ac0841 100644
--- a/otbtf/tfrecords.py
+++ b/otbtf/tfrecords.py
@@ -2,7 +2,7 @@
# ==========================================================================
#
# Copyright 2018-2019 IRSTEA
-# Copyright 2020-2022 INRAE
+# Copyright 2020-2023 INRAE
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
@@ -18,62 +18,93 @@
#
# ==========================================================================*/
"""
-The tfrecords module provides an implementation for the TFRecords files read/write
+[Source code :fontawesome-brands-github:](https://github.com/remicres/otbtf/
+tree/master/otbtf/tfrecords.py){ .md-button }
+
+The tfrecords module provides an implementation for the TFRecords files
+read/write
"""
import glob
import json
-import os
import logging
+import os
from functools import partial
+
+from typing import Any, List, Dict, Callable
import tensorflow as tf
from tqdm import tqdm
class TFRecords:
"""
- This class allows to convert Dataset objects to TFRecords and to load them in dataset tensorflows format.
+ This class allows to convert Dataset objects to TFRecords and to load them
+ in dataset tensorflow format.
"""
- def __init__(self, path):
+ def __init__(self, path: str):
"""
- :param path: Can be a directory where TFRecords must be saved/loaded
+ Params:
+ path: Can be a directory where TFRecords must be saved/loaded
"""
self.dirpath = path
os.makedirs(self.dirpath, exist_ok=True)
- self.output_types_file = os.path.join(self.dirpath, "output_types.json")
- self.output_shapes_file = os.path.join(self.dirpath, "output_shapes.json")
- self.output_shapes = self.load(self.output_shapes_file) if os.path.exists(self.output_shapes_file) else None
- self.output_types = self.load(self.output_types_file) if os.path.exists(self.output_types_file) else None
+ self.output_types_file = os.path.join(
+ self.dirpath, "output_types.json"
+ )
+ self.output_shapes_file = os.path.join(
+ self.dirpath, "output_shapes.json"
+ )
+ self.output_shapes = self.load(self.output_shapes_file) \
+ if os.path.exists(self.output_shapes_file) else None
+ self.output_types = self.load(self.output_types_file) \
+ if os.path.exists(self.output_types_file) else None
@staticmethod
def _bytes_feature(value):
"""
Convert a value to a type compatible with tf.train.Example.
- :param value: value
- :return a bytes_list from a string / byte.
+
+ Params:
+ value: value
+
+ Returns:
+ a bytes_list from a string / byte.
"""
if isinstance(value, type(tf.constant(0))):
- value = value.numpy() # BytesList won't unpack a string from an EagerTensor.
+ value = value.numpy() # BytesList won't unpack a string from
+ # an EagerTensor.
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
- def ds2tfrecord(self, dataset, n_samples_per_shard=100, drop_remainder=True):
+ def ds2tfrecord(
+ self,
+ dataset: Any,
+ n_samples_per_shard: int = 100,
+ drop_remainder: bool = True
+ ):
"""
Convert and save samples from dataset object to tfrecord files.
- :param dataset: Dataset object to convert into a set of tfrecords
- :param n_samples_per_shard: Number of samples per shard
- :param drop_remainder: Whether additional samples should be dropped. Advisable if using multiworkers training.
- If True, all TFRecords will have `n_samples_per_shard` samples
+
+ Params:
+ dataset: Dataset object to convert into a set of tfrecords
+ n_samples_per_shard: Number of samples per shard
+ drop_remainder: Whether additional samples should be dropped.
+ Advisable if using multiworkers training. If True, all
+ TFRecords will have `n_samples_per_shard` samples
+
"""
logging.info("%s samples", dataset.size)
- nb_shards = (dataset.size // n_samples_per_shard)
+ nb_shards = dataset.size // n_samples_per_shard
if not drop_remainder and dataset.size % n_samples_per_shard > 0:
nb_shards += 1
- output_shapes = {key: output_shape for key, output_shape in dataset.output_shapes.items()}
+ output_shapes = dict(dataset.output_shapes.items())
self.save(output_shapes, self.output_shapes_file)
- output_types = {key: output_type.name for key, output_type in dataset.output_types.items()}
+ output_types = {
+ key: output_type.name
+ for key, output_type in dataset.output_types.items()
+ }
self.save(output_types, self.output_types_file)
for i in tqdm(range(nb_shards)):
@@ -87,100 +118,165 @@ class TFRecords:
with tf.io.TFRecordWriter(filepath) as writer:
for _ in range(nb_sample):
sample = dataset.read_one_sample()
- serialized_sample = {name: tf.io.serialize_tensor(fea) for name, fea in sample.items()}
- features = {name: self._bytes_feature(serialized_tensor) for name, serialized_tensor in
- serialized_sample.items()}
+ serialized_sample = {
+ name: tf.io.serialize_tensor(fea)
+ for name, fea in sample.items()
+ }
+ features = {
+ name: self._bytes_feature(serialized_tensor)
+ for name, serialized_tensor in
+ serialized_sample.items()
+ }
tf_features = tf.train.Features(feature=features)
example = tf.train.Example(features=tf_features)
writer.write(example.SerializeToString())
@staticmethod
- def save(data, filepath):
+ def save(data: Dict[str, Any], filepath: str):
"""
Save data to JSON format.
- :param data: Data to save json format
- :param filepath: Output file name
+
+ Params:
+ data: Data to save json format
+ filepath: Output file name
+
"""
with open(filepath, 'w') as file:
json.dump(data, file, indent=4)
@staticmethod
- def load(filepath):
+ def load(filepath: str):
"""
Return data from JSON format.
- :param filepath: Input file name
+
+ Args:
+ filepath: Input file name
+
"""
with open(filepath, 'r') as file:
return json.load(file)
- def parse_tfrecord(self, example, target_keys, preprocessing_fn=None, **kwargs):
+ def parse_tfrecord(
+ self,
+ example: Any,
+ target_keys: List[str],
+ preprocessing_fn: Callable = None,
+ **kwargs
+ ):
"""
Parse example object to sample dict.
- :param example: Example object to parse
- :param target_keys: list of keys of the targets
- :param preprocessing_fn: Optional. A preprocessing function that process the input example
- :param kwargs: some keywords arguments for preprocessing_fn
+
+ Params:
+ example: Example object to parse
+ target_keys: list of keys of the targets
+ preprocessing_fn: Optional. A preprocessing function that process
+ the input example
+ kwargs: some keywords arguments for preprocessing_fn
+
"""
- read_features = {key: tf.io.FixedLenFeature([], dtype=tf.string) for key in self.output_types}
+ read_features = {
+ key: tf.io.FixedLenFeature([], dtype=tf.string)
+ for key in self.output_types
+ }
example_parsed = tf.io.parse_single_example(example, read_features)
# Tensor with right data type
for key, out_type in self.output_types.items():
- example_parsed[key] = tf.io.parse_tensor(example_parsed[key], out_type=out_type)
+ example_parsed[key] = tf.io.parse_tensor(
+ example_parsed[key],
+ out_type=out_type
+ )
# Ensure shape
for key, shape in self.output_shapes.items():
example_parsed[key] = tf.ensure_shape(example_parsed[key], shape)
# Preprocessing
- example_parsed_prep = preprocessing_fn(example_parsed, **kwargs) if preprocessing_fn else example_parsed
+ example_parsed_prep = preprocessing_fn(
+ example_parsed, **kwargs
+ ) if preprocessing_fn else example_parsed
# Differentiating inputs and targets
- input_parsed = {key: value for (key, value) in example_parsed_prep.items() if key not in target_keys}
- target_parsed = {key: value for (key, value) in example_parsed_prep.items() if key in target_keys}
+ input_parsed = {
+ key: value for (key, value) in example_parsed_prep.items()
+ if key not in target_keys
+ }
+ target_parsed = {
+ key: value for (key, value) in example_parsed_prep.items()
+ if key in target_keys
+ }
return input_parsed, target_parsed
- def read(self, batch_size, target_keys, n_workers=1, drop_remainder=True, shuffle_buffer_size=None,
- preprocessing_fn=None, shard_policy=tf.data.experimental.AutoShardPolicy.AUTO,
- prefetch_buffer_size=tf.data.experimental.AUTOTUNE,
- num_parallel_calls=tf.data.experimental.AUTOTUNE, **kwargs):
+ def read(
+ self,
+ batch_size: int,
+ target_keys: List[str],
+ n_workers: int = 1,
+ drop_remainder: bool = True,
+ shuffle_buffer_size: int = None,
+ preprocessing_fn: Callable = None,
+ shard_policy=tf.data.experimental.AutoShardPolicy.AUTO,
+ prefetch_buffer_size: int = tf.data.experimental.AUTOTUNE,
+ num_parallel_calls: int = tf.data.experimental.AUTOTUNE,
+ **kwargs
+ ):
"""
- Read all tfrecord files matching with pattern and convert data to tensorflow dataset.
- :param batch_size: Size of tensorflow batch
- :param target_keys: Keys of the target, e.g. ['s2_out']
- :param n_workers: number of workers, e.g. 4 if using 4 GPUs
- e.g. 12 if using 3 nodes of 4 GPUs
- :param drop_remainder: whether the last batch should be dropped in the case it has fewer than
- `batch_size` elements. True is advisable when training on multiworkers.
- False is advisable when evaluating metrics so that all samples are used
- :param shuffle_buffer_size: if None, shuffle is not used. Else, blocks of shuffle_buffer_size
- elements are shuffled using uniform random.
- :param preprocessing_fn: Optional. A preprocessing function that takes input examples as args and returns the
- preprocessed input examples. Typically, examples are composed of model inputs and
- targets. Model inputs and model targets must be computed accordingly to (1) what the
- model outputs and (2) what training loss needs. For instance, for a classification
- problem, the model will likely output the softmax, or activation neurons, for each
- class, and the cross entropy loss requires labels in one hot encoding. In this case,
- the preprocessing_fn has to transform the labels values (integer ranging from
- [0, n_classes]) in one hot encoding (vector of 0 and 1 of length n_classes). The
- preprocessing_fn should not implement such things as radiometric transformations from
- input to input_preprocessed, because those are performed inside the model itself
- (see `otbtf.ModelBase.normalize_inputs()`).
- :param shard_policy: sharding policy for the TFRecordDataset options
- :param prefetch_buffer_size: buffer size for the prefetch operation
- :param num_parallel_calls: number of parallel calls for the parsing + preprocessing step
- :param kwargs: some keywords arguments for preprocessing_fn
+ Read all tfrecord files matching with pattern and convert data to
+ tensorflow dataset.
+
+ Params:
+ batch_size: Size of tensorflow batch
+ target_keys: Keys of the target, e.g. ['s2_out']
+ n_workers: number of workers, e.g. 4 if using 4 GPUs, e.g. 12 if
+ using 3 nodes of 4 GPUs
+ drop_remainder: whether the last batch should be dropped in the
+ case it has fewer than `batch_size` elements. True is
+ advisable when training on multiworkers. False is advisable
+ when evaluating metrics so that all samples are used
+ shuffle_buffer_size: if None, shuffle is not used. Else, blocks of
+ shuffle_buffer_size elements are shuffled using uniform random.
+ preprocessing_fn: Optional. A preprocessing function that takes
+ input examples as args and returns the preprocessed input
+ examples. Typically, examples are composed of model inputs and
+ targets. Model inputs and model targets must be computed
+ accordingly to (1) what the model outputs and (2) what
+ training loss needs. For instance, for a classification
+ problem, the model will likely output the softmax, or
+ activation neurons, for each class, and the cross entropy loss
+ requires labels in one hot encoding. In this case, the
+ `preprocessing_fn` has to transform the labels values (integer
+ ranging from [0, n_classes]) in one hot encoding (vector of 0
+ and 1 of length n_classes). The `preprocessing_fn` should not
+ implement such things as radiometric transformations from
+ input to input_preprocessed, because those are performed
+ inside the model itself (see
+ `otbtf.ModelBase.normalize_inputs()`).
+ shard_policy: sharding policy for the TFRecord dataset options
+ prefetch_buffer_size: buffer size for the prefetch operation
+ num_parallel_calls: number of parallel calls for the parsing +
+ preprocessing step
+ kwargs: some keywords arguments for `preprocessing_fn`
+
"""
- for dic, file in zip([self.output_types, self.output_shapes],
- [self.output_types_file, self.output_shapes_file]):
+ for dic, file in zip([self.output_types,
+ self.output_shapes],
+ [self.output_types_file,
+ self.output_shapes_file]):
assert dic, f"The file {file} is missing!"
options = tf.data.Options()
if shuffle_buffer_size:
- options.experimental_deterministic = False # disable order, increase speed
- options.experimental_distribute.auto_shard_policy = shard_policy # for multiworker
- parse = partial(self.parse_tfrecord, target_keys=target_keys, preprocessing_fn=preprocessing_fn, **kwargs)
+ # disable order, increase speed
+ options.experimental_deterministic = False
+ # for multiworker
+ options.experimental_distribute.auto_shard_policy = shard_policy
+ parse = partial(
+ self.parse_tfrecord,
+ target_keys=target_keys,
+ preprocessing_fn=preprocessing_fn,
+ **kwargs
+ )
# 1/ num_parallel_reads useful ? I/O bottleneck of not ?
# 2/ num_parallel_calls=tf.data.experimental.AUTOTUNE useful ?
@@ -188,14 +284,22 @@ class TFRecords:
matching_files = glob.glob(tfrecords_pattern_path)
logging.info('Searching TFRecords in %s...', tfrecords_pattern_path)
logging.info('Number of matching TFRecords: %s', len(matching_files))
- matching_files = matching_files[:n_workers * (len(matching_files) // n_workers)] # files multiple of workers
+ matching_files = matching_files[:n_workers * (
+ len(matching_files) // n_workers)] # files multiple of workers
nb_matching_files = len(matching_files)
if nb_matching_files == 0:
- raise Exception(f"At least one worker has no TFRecord file in {tfrecords_pattern_path}. Please ensure that "
- "the number of TFRecord files is greater or equal than the number of workers!")
+ raise Exception(
+ "At least one worker has no TFRecord file in "
+ f"{tfrecords_pattern_path}. Please ensure that the number of "
+ "TFRecord files is greater or equal than the number of "
+ "workers!"
+ )
logging.info('Reducing number of records to : %s', nb_matching_files)
- dataset = tf.data.TFRecordDataset(matching_files) # , num_parallel_reads=2) # interleaves reads from xxx files
- dataset = dataset.with_options(options) # uses data as soon as it streams in, rather than in its original order
+ dataset = tf.data.TFRecordDataset(
+ matching_files
+ ) # , num_parallel_reads=2) # interleaves reads from xxx files
+ # uses data as soon as it streams in, rather than in its original order
+ dataset = dataset.with_options(options)
dataset = dataset.map(parse, num_parallel_calls=num_parallel_calls)
if shuffle_buffer_size:
dataset = dataset.shuffle(buffer_size=shuffle_buffer_size)
diff --git a/otbtf/utils.py b/otbtf/utils.py
index 069638a5..1c552fbd 100644
--- a/otbtf/utils.py
+++ b/otbtf/utils.py
@@ -2,7 +2,7 @@
# ==========================================================================
#
# Copyright 2018-2019 IRSTEA
-# Copyright 2020-2022 INRAE
+# Copyright 2020-2023 INRAE
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
@@ -18,19 +18,24 @@
#
# ==========================================================================*/
"""
+[Source code :fontawesome-brands-github:](https://github.com/remicres/otbtf/
+tree/master/otbtf/utils.py){ .md-button }
+
The utils module provides some helpers to read patches using gdal
"""
from osgeo import gdal
import numpy as np
-# ----------------------------------------------------- Helpers --------------------------------------------------------
-
-def gdal_open(filename):
+def gdal_open(filename: str):
"""
Open a GDAL raster
- :param filename: raster file
- :return: a GDAL dataset instance
+
+ Params:
+ filename: raster file
+
+ Returns:
+ one GDAL dataset instance
"""
gdal_ds = gdal.Open(filename)
if not gdal_ds:
@@ -38,14 +43,25 @@ def gdal_open(filename):
return gdal_ds
-def read_as_np_arr(gdal_ds, as_patches=True, dtype=None):
+def read_as_np_arr(
+ gdal_ds,
+ as_patches: bool = True,
+ dtype: np.dtype = None
+) -> np.ndarray:
"""
Read a GDAL raster as numpy array
- :param gdal_ds: a GDAL dataset instance
- :param as_patches: if True, the returned numpy array has the following shape (n, psz_x, psz_x, nb_channels). If
- False, the shape is (1, psz_y, psz_x, nb_channels)
- :param dtype: if not None array dtype will be cast to given numpy data type (np.float32, np.uint16...)
- :return: Numpy array of dim 4
+
+ Params:
+ gdal_ds: a GDAL dataset instance
+ as_patches: if True, the returned numpy array has the following
+ shape (n, psz_x, psz_x, nb_channels). If False, the shape is (1,
+ psz_y, psz_x, nb_channels)
+ dtype: if not None array dtype will be cast to given numpy data type
+ (np.float32, np.uint16...)
+
+ Returns
+ Numpy array of dim 4
+
"""
buffer = gdal_ds.ReadAsArray()
size_x = gdal_ds.RasterXSize
diff --git a/setup.py b/setup.py
index 35d216ae..958be96a 100644
--- a/setup.py
+++ b/setup.py
@@ -6,7 +6,7 @@ with open("README.md", "r", encoding="utf-8") as fh:
setuptools.setup(
name="otbtf",
- version="3.4.0",
+ version="4.0.0",
author="Remi Cresson",
author_email="remi.cresson@inrae.fr",
description="OTBTF: Orfeo ToolBox meets TensorFlow",
@@ -26,5 +26,12 @@ setuptools.setup(
],
packages=setuptools.find_packages(),
python_requires=">=3.6",
- keywords="remote sensing, otb, orfeotoolbox, orfeo toolbox, tensorflow, tf, deep learning, machine learning",
+ keywords=["remote sensing",
+ "otb",
+ "orfeotoolbox",
+ "orfeo toolbox",
+ "tensorflow",
+ "deep learning",
+ "machine learning"
+ ],
)
diff --git a/test/api_unittest.py b/test/api_unittest.py
index 29582489..2fe3fe38 100644
--- a/test/api_unittest.py
+++ b/test/api_unittest.py
@@ -1,13 +1,16 @@
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
-import pytest
import unittest
-from test_utils import resolve_paths, files_exist, run_command_and_compare
-from otbtf.examples.tensorflow_v2x.fcnn.fcnn_model import INPUT_NAME, OUTPUT_SOFTMAX_NAME
+
+import pytest
+
+from otbtf.examples.tensorflow_v2x.fcnn import create_tfrecords
from otbtf.examples.tensorflow_v2x.fcnn import train_from_patchesimages
from otbtf.examples.tensorflow_v2x.fcnn import train_from_tfrecords
-from otbtf.examples.tensorflow_v2x.fcnn import create_tfrecords
+from otbtf.examples.tensorflow_v2x.fcnn.fcnn_model import INPUT_NAME, \
+ OUTPUT_SOFTMAX_NAME
from otbtf.model import cropped_tensor_name
+from test_utils import resolve_paths, files_exist, run_command_and_compare
INFERENCE_MAE_TOL = 10.0 # Dummy value: we don't really care of the mae value but rather the image size etc
@@ -16,21 +19,25 @@ class APITest(unittest.TestCase):
@pytest.mark.order(1)
def test_train_from_patchesimages(self):
- params = train_from_patchesimages.parser.parse_args(['--model_dir', resolve_paths('$TMPDIR/model_from_pimg'),
- '--nb_epochs', '1',
- '--train_xs',
- resolve_paths('$DATADIR/amsterdam_patches_A.tif'),
- '--train_labels',
- resolve_paths('$DATADIR/amsterdam_labels_A.tif'),
- '--valid_xs',
- resolve_paths('$DATADIR/amsterdam_patches_B.tif'),
- '--valid_labels',
- resolve_paths('$DATADIR/amsterdam_labels_B.tif')])
+ params = train_from_patchesimages.parser.parse_args([
+ '--model_dir', resolve_paths('$TMPDIR/model_from_pimg'),
+ '--nb_epochs', '1',
+ '--train_xs',
+ resolve_paths('$DATADIR/amsterdam_patches_A.tif'),
+ '--train_labels',
+ resolve_paths('$DATADIR/amsterdam_labels_A.tif'),
+ '--valid_xs',
+ resolve_paths('$DATADIR/amsterdam_patches_B.tif'),
+ '--valid_labels',
+ resolve_paths('$DATADIR/amsterdam_labels_B.tif')
+ ])
train_from_patchesimages.train(params=params)
- self.assertTrue(files_exist(['$TMPDIR/model_from_pimg/keras_metadata.pb',
- '$TMPDIR/model_from_pimg/saved_model.pb',
- '$TMPDIR/model_from_pimg/variables/variables.data-00000-of-00001',
- '$TMPDIR/model_from_pimg/variables/variables.index']))
+ self.assertTrue(files_exist([
+ '$TMPDIR/model_from_pimg/keras_metadata.pb',
+ '$TMPDIR/model_from_pimg/saved_model.pb',
+ '$TMPDIR/model_from_pimg/variables/variables.data-00000-of-00001',
+ '$TMPDIR/model_from_pimg/variables/variables.index'
+ ]))
@pytest.mark.order(2)
def test_model_inference1(self):
@@ -48,7 +55,8 @@ class APITest(unittest.TestCase):
"-output.efieldx 32 "
"-output.efieldy 32 "
"-out \"$TMPDIR/classif_model4_softmax.tif?&gdal:co:compress=deflate\" uint8",
- to_compare_dict={"$DATADIR/classif_model4_softmax.tif": "$TMPDIR/classif_model4_softmax.tif"},
+ to_compare_dict={
+ "$DATADIR/classif_model4_softmax.tif": "$TMPDIR/classif_model4_softmax.tif"},
tol=INFERENCE_MAE_TOL))
self.assertTrue(
run_command_and_compare(
@@ -64,36 +72,49 @@ class APITest(unittest.TestCase):
"-output.efieldx 64 "
"-output.efieldy 64 "
"-out \"$TMPDIR/classif_model4_softmax.tif?&gdal:co:compress=deflate\" uint8",
- to_compare_dict={"$DATADIR/classif_model4_softmax.tif": "$TMPDIR/classif_model4_softmax.tif"},
+ to_compare_dict={
+ "$DATADIR/classif_model4_softmax.tif": "$TMPDIR/classif_model4_softmax.tif"},
tol=INFERENCE_MAE_TOL))
@pytest.mark.order(3)
def test_create_tfrecords(self):
- params = create_tfrecords.parser.parse_args(['--xs', resolve_paths('$DATADIR/amsterdam_patches_A.tif'),
- '--labels', resolve_paths('$DATADIR/amsterdam_labels_A.tif'),
- '--outdir', resolve_paths('$TMPDIR/train')])
+ params = create_tfrecords.parser.parse_args([
+ '--xs', resolve_paths('$DATADIR/amsterdam_patches_A.tif'),
+ '--labels', resolve_paths('$DATADIR/amsterdam_labels_A.tif'),
+ '--outdir', resolve_paths('$TMPDIR/train')
+ ])
create_tfrecords.create_tfrecords(params=params)
- self.assertTrue(files_exist(['$TMPDIR/train/output_shapes.json',
- '$TMPDIR/train/output_types.json',
- '$TMPDIR/train/0.records']))
- params = create_tfrecords.parser.parse_args(['--xs', resolve_paths('$DATADIR/amsterdam_patches_B.tif'),
- '--labels', resolve_paths('$DATADIR/amsterdam_labels_B.tif'),
- '--outdir', resolve_paths('$TMPDIR/valid')])
+ self.assertTrue(files_exist([
+ '$TMPDIR/train/output_shapes.json',
+ '$TMPDIR/train/output_types.json',
+ '$TMPDIR/train/0.records'
+ ]))
+ params = create_tfrecords.parser.parse_args([
+ '--xs', resolve_paths('$DATADIR/amsterdam_patches_B.tif'),
+ '--labels', resolve_paths('$DATADIR/amsterdam_labels_B.tif'),
+ '--outdir', resolve_paths('$TMPDIR/valid')
+ ])
create_tfrecords.create_tfrecords(params=params)
- self.assertTrue(files_exist(['$TMPDIR/valid/output_shapes.json',
- '$TMPDIR/valid/output_types.json',
- '$TMPDIR/valid/0.records']))
+ self.assertTrue(files_exist([
+ '$TMPDIR/valid/output_shapes.json',
+ '$TMPDIR/valid/output_types.json',
+ '$TMPDIR/valid/0.records'
+ ]))
@pytest.mark.order(4)
def test_train_from_tfrecords(self):
- params = train_from_tfrecords.parser.parse_args(['--model_dir', resolve_paths('$TMPDIR/model_from_tfrecs'),
- '--nb_epochs', '1',
- '--tfrecords_dir', resolve_paths('$TMPDIR')])
+ params = train_from_tfrecords.parser.parse_args([
+ '--model_dir', resolve_paths('$TMPDIR/model_from_tfrecs'),
+ '--nb_epochs', '1',
+ '--tfrecords_dir', resolve_paths('$TMPDIR')
+ ])
train_from_tfrecords.train(params=params)
- self.assertTrue(files_exist(['$TMPDIR/model_from_tfrecs/keras_metadata.pb',
- '$TMPDIR/model_from_tfrecs/saved_model.pb',
- '$TMPDIR/model_from_tfrecs/variables/variables.data-00000-of-00001',
- '$TMPDIR/model_from_tfrecs/variables/variables.index']))
+ self.assertTrue(files_exist([
+ '$TMPDIR/model_from_tfrecs/keras_metadata.pb',
+ '$TMPDIR/model_from_tfrecs/saved_model.pb',
+ '$TMPDIR/model_from_tfrecs/variables/variables.data-00000-of-00001',
+ '$TMPDIR/model_from_tfrecs/variables/variables.index'
+ ]))
@pytest.mark.order(5)
def test_model_inference2(self):
@@ -111,7 +132,10 @@ class APITest(unittest.TestCase):
"-output.efieldx 32 "
"-output.efieldy 32 "
"-out \"$TMPDIR/classif_model4_softmax.tif?&gdal:co:compress=deflate\" uint8",
- to_compare_dict={"$DATADIR/classif_model4_softmax.tif": "$TMPDIR/classif_model4_softmax.tif"},
+ to_compare_dict={
+ "$DATADIR/classif_model4_softmax.tif":
+ "$TMPDIR/classif_model4_softmax.tif"
+ },
tol=INFERENCE_MAE_TOL))
self.assertTrue(
@@ -128,7 +152,10 @@ class APITest(unittest.TestCase):
"-output.efieldx 64 "
"-output.efieldy 64 "
"-out \"$TMPDIR/classif_model4_softmax.tif?&gdal:co:compress=deflate\" uint8",
- to_compare_dict={"$DATADIR/classif_model4_softmax.tif": "$TMPDIR/classif_model4_softmax.tif"},
+ to_compare_dict={
+ "$DATADIR/classif_model4_softmax.tif":
+ "$TMPDIR/classif_model4_softmax.tif"
+ },
tol=INFERENCE_MAE_TOL))
diff --git a/test/imports_test.py b/test/imports_test.py
new file mode 100644
index 00000000..a89ab3dc
--- /dev/null
+++ b/test/imports_test.py
@@ -0,0 +1,23 @@
+#!/usr/bin/env python3
+# -*- coding: utf-8 -*-
+import pytest
+import unittest
+
+class ImportsTest(unittest.TestCase):
+
+ def test_import_both1(self):
+ import tensorflow
+ self.assertTrue(tensorflow.__version__)
+ import otbApplication
+ self.assertTrue(otbApplication.Registry_GetAvailableApplications())
+
+
+ def test_import_both2(self):
+ import otbApplication
+ self.assertTrue(otbApplication.Registry_GetAvailableApplications())
+ import tensorflow
+ self.assertTrue(tensorflow.__version__)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tools/docker/README.md b/tools/docker/README.md
deleted file mode 100644
index 3dcf38f8..00000000
--- a/tools/docker/README.md
+++ /dev/null
@@ -1,159 +0,0 @@
-# Build with Docker
-Docker build has to be called from the root of the repository (i.e. `docker build .` or `bash tools/docker/multibuild.sh`).
-You can build a custom image using `--build-arg` and several config files :
-- Ubuntu : `BASE_IMG` should accept any version, for additional packages see [build-deps-cli.txt](build-deps-cli.txt) and [build-deps-gui.txt](build-deps-gui.txt).
-- TensorFlow : `TF` arg for the git branch or tag + [build-env-tf.sh](build-env-tf.sh) and BZL_* arguments for the build configuration. `ZIP_TF_BIN` allows you to save compiled binaries if you want to install it elsewhere.
-- OrfeoToolBox : `OTB` arg for the git branch or tag + [build-flags-otb.txt](build-flags-otb.txt) to edit cmake flags. Set `KEEP_SRC_OTB` in order to preserve OTB git directory.
-
-### Base images
-```bash
-UBUNTU=20.04 # or 16.04, 18.04
-CUDA=11.2.2 # or 10.1, 10.2, 11.0.3
-CUDNN=8 # or 7
-IMG=ubuntu:$UBUNTU
-GPU_IMG=nvidia/cuda:$CUDA-cudnn$CUDNN-devel-ubuntu$UBUNTU
-```
-
-### Default arguments
-```bash
-BASE_IMG # mandatory
-CPU_RATIO=1
-GUI=false
-NUMPY_SPEC="==1.19.*"
-TF=v2.8.0
-OTB=8.1.0
-BZL_TARGETS="//tensorflow:libtensorflow_cc.so //tensorflow/tools/pip_package:build_pip_package"
-BZL_CONFIGS="--config=nogcp --config=noaws --config=nohdfs --config=opt"
-BZL_OPTIONS="--verbose_failures --remote_cache=http://localhost:9090"
-ZIP_TF_BIN=false
-KEEP_SRC_OTB=false
-SUDO=true
-
-# NumPy version requirement :
-# TF < 2.4 : "numpy<1.19.0,>=1.16.0"
-# TF >= 2.4 : "numpy==1.19.*"
-# TF >= 2.8 : "numpy==1.22.*"
-```
-
-### Bazel remote cache daemon
-If you just need to rebuild with different GUI or KEEP_SRC arguments, or may be a different branch of OTB, bazel cache will help you to rebuild everything except TF, even if the docker cache was purged (after `docker [system|builder] prune`).
-In order to recycle the cache, bazel config and TF git tag should be exactly the same, any change in [build-env-tf.sh](build-env-tf.sh) and `--build-arg` (if related to bazel env, cuda, mkl, xla...) may result in a fresh new build.
-
-Start a cache daemon - here with max 20GB but 10GB should be enough to save 2 TF builds (GPU and CPU):
-```bash
-mkdir -p $HOME/.cache/bazel-remote
-docker run --detach -u 1000:1000 -v $HOME/.cache/bazel-remote:/data -p 9090:8080 buchgr/bazel-remote-cache --max_size=20
-```
-Then just add ` --network='host'` to the docker build command, or connect bazel to a remote server - see 'BZL_OPTIONS'.
-The other way of docker is a virtual bridge, but you'll need to edit the IP address.
-
-## Images build examples
-```bash
-# Build for CPU using default Dockerfiles args (without AWS, HDFS or GCP support)
-docker build --network='host' -t otbtf:cpu --build-arg BASE_IMG=ubuntu:20.04 .
-
-# Clear bazel config var (deactivate default optimizations and unset noaws/nogcp/nohdfs)
-docker build --network='host' -t otbtf:cpu --build-arg BASE_IMG=ubuntu:20.04 --build-arg BZL_CONFIGS= .
-
-# Enable MKL
-MKL_CONFIG="--config=nogcp --config=noaws --config=nohdfs --config=opt --config=mkl"
-docker build --network='host' -t otbtf:cpu-mkl --build-arg BZL_CONFIGS="$MKL_CONFIG" --build-arg BASE_IMG=ubuntu:20.04 .
-
-# Build for GPU (if you're building for your system only you should edit CUDA_COMPUTE_CAPABILITIES in build-env-tf.sh)
-docker build --network='host' -t otbtf:gpu --build-arg BASE_IMG=nvidia/cuda:11.0.3-cudnn8-devel-ubuntu20.04 .
-
-# Build latest TF and OTB, set git branches/tags to clone
-docker build --network='host' -t otbtf:gpu-dev --build-arg BASE_IMG=nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04 \
- --build-arg KEEP_SRC_OTB=true --build-arg TF=nightly --build-arg OTB=develop .
-
-# Build old release (TF-2.1)
-docker build --network='host' -t otbtf:oldstable-gpu --build-arg BASE_IMG=nvidia/cuda:10.1-cudnn7-devel-ubuntu18.04 \
- --build-arg TF=r2.1 --build-arg NUMPY_SPEC="<1.19" \
- --build-arg BAZEL_OPTIONS="--noincompatible_do_not_split_linking_cmdline --verbose_failures --remote_cache=http://localhost:9090" .
-# You could edit the Dockerfile in order to clone an old branch of the repo instead of copying files from the build context
-```
-
-### Build for another machine and save TF compiled files
-
-Example with TF 2.5
-
-```bash
-# Use same ubuntu and CUDA version than your target machine, beware of CC optimization and CPU compatibility
-# (set env variable CC_OPT_FLAGS and avoid "-march=native" if your Docker's CPU is optimized with AVX2/AVX512 but your target CPU isn't)
-docker build --network='host' -t otbtf:custom --build-arg BASE_IMG=nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04 \
- --build-arg TF=v2.5.0 --build-arg ZIP_TF_BIN=true .
-# Retrieve zip file
-docker run -v $HOME:/home/otbuser/volume otbtf:custom cp /opt/otbtf/tf-v2.5.0.zip /home/otbuser/volume
-
-# Target machine shell
-cd $HOME
-unzip tf-v2.5.0.zip
-sudo mkdir -p /opt/tensorflow/lib
-sudo mv tf-v2.5.0/libtensorflow_cc* /opt/tensorflow/lib
-# You may need to create a virtualenv, here TF and dependencies are installed next to user's pip packages
-pip3 install -U pip wheel mock six future deprecated "numpy==1.19.*"
-pip3 install --no-deps keras_applications keras_preprocessing
-pip3 install tf-v2.5.0/tensorflow-2.5.0-cp38-cp38-linux_x86_64.whl
-
-TF_WHEEL_DIR="$HOME/.local/lib/python3.8/site-packages/tensorflow"
-# If you installed the wheel as regular user, with root pip it should be in /usr/local/lib/python3.*, or in your virtualenv lib/ directory
-mv tf-v2.5.0/tag_constants.h $TF_WHEEL_DIR/include/tensorflow/cc/saved_model/
-# Then recompile OTB with OTBTF using libraries in /opt/tensorflow/lib and instructions in HOWTOBUILD.md.
-cmake $OTB_GIT \
- -DOTB_USE_TENSORFLOW=ON -DModule_OTBTensorflow=ON \
- -DTENSORFLOW_CC_LIB=/opt/tensorflow/lib/libtensorflow_cc.so.2 \
- -Dtensorflow_include_dir=$TF_WHEEL_DIR/include \
- -DTENSORFLOW_FRAMEWORK_LIB=$TF_WHEEL_DIR/libtensorflow_framework.so.2 \
-&& make install -j
-```
-
-### Debug build
-If you fail to build, you can log into the last layer and check CMake logs. Run `docker images`, find the latest layer ID and run a tmp container (`docker run -it d60496d9612e bash`).
-You may also need to split some multi-command layers in the Dockerfile.
-If you see OOM errors during SuperBuild you should decrease CPU_RATIO (e.g. 0.75).
-
-## Container examples
-```bash
-# Pull GPU image and create a new container with your home directory as volume (requires apt package nvidia-docker2 and CUDA>=11.0)
-docker create --gpus=all --volume $HOME:/home/otbuser/volume -it --name otbtf-gpu mdl4eo/otbtf:3.3.2-gpu
-
-# Run interactive
-docker start -i otbtf-gpu
-
-# Run in background
-docker start otbtf-gpu
-docker exec otbtf-gpu python -c 'import tensorflow as tf; print(tf.test.is_gpu_available())'
-```
-
-### Rebuild OTB with more modules
-```bash
-docker create --gpus=all -it --name otbtf-gpu-dev mdl4eo/otbtf:3.3.2-gpu-dev
-docker start -i otbtf-gpu-dev
-```
-```bash
-# From the container shell:
-sudo -i
-cd /src/otb/otb/Modules/Remote
-git clone https://gitlab.irstea.fr/raffaele.gaetano/otbSelectiveHaralickTextures.git
-cd /src/otb/build/OTB/build
-cmake -DModule_OTBAppSelectiveHaralickTextures=ON /src/otb/otb && make install -j
-```
-
-### Container with GUI
-```bash
-# GUI is disabled by default in order to save space, and because docker xvfb isn't working properly with OpenGL.
-# => otbgui seems OK but monteverdi isn't working
-docker build --network='host' -t otbtf:cpu-gui --build-arg BASE_IMG=ubuntu:20.04 --build-arg GUI=true .
-docker create -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -it --name otbtf-gui otbtf:cpu-gui
-docker start -i otbtf-gui
-$ mapla
-```
-
-## Common errors
-Build :
-`Error response from daemon: manifest for nvidia/cuda:11.0-cudnn8-devel-ubuntu20.04 not found: manifest unknown: manifest unknown`
-=> Image is missing from dockerhub
-
-Run :
-`failed call to cuInit: UNKNOWN ERROR (303) / no NVIDIA GPU device is present: /dev/nvidia0 does not exist`
-=> Nvidia driver is missing or disabled, make sure to add ` --gpus=all` to your docker run or create command
diff --git a/tools/docker/build-deps-cli.txt b/tools/docker/build-deps-cli.txt
index 67d94187..6b7432f8 100644
--- a/tools/docker/build-deps-cli.txt
+++ b/tools/docker/build-deps-cli.txt
@@ -45,6 +45,5 @@ libsvm-dev
libtinyxml-dev
zlib1g-dev
libgeos++-dev
-libgeos-3.8.0
libgeos-c1v5
libgeos-dev
diff --git a/tools/docker/build-env-tf.sh b/tools/docker/build-env-tf.sh
index b29f6c1a..ff5c5692 100644
--- a/tools/docker/build-env-tf.sh
+++ b/tools/docker/build-env-tf.sh
@@ -1,7 +1,9 @@
### TF - bazel build env variables
-# As in official TF wheels, you'll need to remove "-march=native" to ensure portability (avoid AVX2 / AVX512 compatibility issues)
-# You could also add CPUs instructions one by one, in this example to avoid only AVX512 but enable commons optimizations like FMA, SSE4.2 and AVX2
+# As in official TF wheels, you'll need to remove "-march=native" to ensure
+# portability (avoid AVX2 / AVX512 compatibility issues)
+# You could also add CPUs instructions one by one, in this example to avoid
+# only AVX512 but enable commons optimizations like FMA, SSE4.2 and AVX2
#export CC_OPT_FLAGS="-Wno-sign-compare --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both --copt=-msse4.2"
export CC_OPT_FLAGS="-march=native -Wno-sign-compare"
export GCC_HOST_COMPILER_PATH=$(which gcc)
diff --git a/tools/docker/build-flags-otb.txt b/tools/docker/build-flags-otb.txt
index fe0eb08d..95b8462c 100644
--- a/tools/docker/build-flags-otb.txt
+++ b/tools/docker/build-flags-otb.txt
@@ -6,9 +6,6 @@
-DUSE_SYSTEM_GDAL=OFF
-DUSE_SYSTEM_GEOS=ON
-DUSE_SYSTEM_GEOTIFF=OFF
--DUSE_SYSTEM_GLEW=ON
--DUSE_SYSTEM_GLFW=ON
--DUSE_SYSTEM_GLUT=ON
-DUSE_SYSTEM_GSL=ON
-DUSE_SYSTEM_ITK=ON
-DUSE_SYSTEM_LIBKML=ON
@@ -17,16 +14,6 @@
-DUSE_SYSTEM_MUPARSERX=ON
-DUSE_SYSTEM_OPENCV=ON
-DUSE_SYSTEM_PNG=ON
--DUSE_SYSTEM_QT5=ON
--DUSE_SYSTEM_QWT=ON
-DUSE_SYSTEM_TINYXML=ON
-DUSE_SYSTEM_ZLIB=ON
-DUSE_SYSTEM_SWIG=ON
-
--DOTB_USE_QT=OFF
--DOTB_USE_OPENGL=OFF
--DOTB_USE_GLUT=OFF
--DOTB_USE_GLEW=OFF
--DOTB_USE_GLFW=OFF
-
--DGDAL_SB_EXTRA_OPTIONS=--with-geos
diff --git a/tools/docker/multibuild.sh b/tools/docker/multibuild.sh
index c88bb0ac..9373d292 100644
--- a/tools/docker/multibuild.sh
+++ b/tools/docker/multibuild.sh
@@ -1,37 +1,75 @@
#!/bin/bash
-### Docker multibuild and push, see default args and more examples in tools/docker/README.md
-RELEASE=2.5
-UBUNTU=20.04
-CUDA=11.2.2
-CUDNN=8
-IMG=ubuntu:$UBUNTU
-GPU_IMG=nvidia/cuda:$CUDA-cudnn$CUDNN-devel-ubuntu$UBUNTU
+# Various docker builds using bazel cache
+RELEASE=3.5
+CPU_IMG=ubuntu:22.04
+GPU_IMG=nvidia/cuda:12.1.0-devel-ubuntu22.04
## Bazel remote cache daemon
mkdir -p $HOME/.cache/bazel-remote
-docker run -d -u 1000:1000 -v $HOME/.cache/bazel-remote:/data -p 9090:8080 buchgr/bazel-remote-cache --max_size=20
-
-### CPU (no MKL)
-docker build --network='host' -t mdl4eo/otbtf$RELEASE:cpu-dev --build-arg BASE_IMG=$IMG --build-arg KEEP_SRC_OTB=true .
-docker build --network='host' -t mdl4eo/otbtf$RELEASE:cpu --build-arg BASE_IMG=$IMG .
-#docker build --network='host' -t mdl4eo/otbtf$RELEASE:-cpu-gui --build-arg BASE_IMG=$IMG --build-arg GUI=true .
-
-### MKL is enabled with bazel config flag
-#MKL_CONF="--config=nogcp --config=noaws --config=nohdfs --config=mkl --config=opt"
-#docker build --network='host' -t mdl4eo/otbtf$RELEASE:-cpu-mkl --build-arg BASE_IMG=$IMG --build-arg BZL_CONFIGS="$MKL_CONF" .
-#docker build --network='host' -t mdl4eo/otbtf$RELEASE:-cpu-mkl-dev --build-arg BASE_IMG=$IMG --build-arg BZL_CONFIGS="$MKL_CONF" --build-arg KEEP_SRC_OTB=true .
-
-### GPU support is enabled if CUDA is found in /usr/local
-docker build --network='host' -t mdl4eo/otbtf$RELEASE:gpu-dev --build-arg BASE_IMG=$GPU_IMG --build-arg KEEP_SRC_OTB=true .
-docker build --network='host' -t mdl4eo/otbtf$RELEASE:gpu --build-arg BASE_IMG=$GPU_IMG .
-#docker build --network='host' -t mdl4eo/otbtf$RELEASE:-gpu-gui --build-arg BASE_IMG=$GPU_IMG --build-arg GUI=true .
-
-#docker login
-docker push mdl4eo/otbtf$RELEASE:-cpu-dev
-docker push mdl4eo/otbtf$RELEASE:-cpu
-#docker push mdl4eo/otbtf$RELEASE:-cpu-gui
-#docker push mdl4eo/otbtf$RELEASE:-cpu-mkl
-
-docker push mdl4eo/otbtf$RELEASE:-gpu-dev
-docker push mdl4eo/otbtf$RELEASE:-gpu
-#docker push mdl4eo/otbtf$RELEASE:-gpu-gui
+docker run -d -u 1000:1000 \
+-v $HOME/.cache/bazel-remote:/data \
+-p 9090:8080 \
+buchgr/bazel-remote-cache --max_size=20
+
+### CPU images
+
+# CPU-Dev
+docker build . \
+--network='host' \
+-t mdl4eo/otbtf:$RELEASE-cpu-dev \
+--build-arg BASE_IMG=$CPU_IMG \
+--build-arg KEEP_SRC_OTB=true
+
+# CPU
+docker build . \
+--network='host' \
+-t mdl4eo/otbtf:$RELEASE-cpu \
+--build-arg BASE_IMG=$CPU_IMG
+
+# CPU-GUI
+docker build . \
+--network='host' \
+-t mdl4eo/otbtf:$RELEASE-cpu-gui \
+--build-arg BASE_IMG=$CPU_IMG \
+--build-arg GUI=true
+
+### CPU images with Intel MKL support
+MKL_CONF="--config=nogcp --config=noaws --config=nohdfs --config=mkl --config=opt"
+
+# CPU-MKL
+docker build . \
+--network='host' \
+-t mdl4eo/otbtf:$RELEASE-cpu-mkl \
+--build-arg BASE_IMG=$CPU_IMG \
+--build-arg BZL_CONFIGS="$MKL_CONF"
+
+# CPU-MKL-Dev
+docker build . \
+--network='host' \
+-t mdl4eo/otbtf:$RELEASE-cpu-mkl-dev \
+--build-arg BASE_IMG=$CPU_IMG \
+--build-arg BZL_CONFIGS="$MKL_CONF" \
+--build-arg KEEP_SRC_OTB=true
+
+### GPU enabled images
+# Support is enabled if CUDA is found in /usr/local
+
+# GPU
+docker build . \
+--network='host' \
+-t mdl4eo/otbtf:$RELEASE-gpu-dev \
+--build-arg BASE_IMG=$GPU_IMG \
+--build-arg KEEP_SRC_OTB=true
+
+# GPU-Dev
+docker build . \
+--network='host' \
+-t mdl4eo/otbtf:$RELEASE-gpu \
+--build-arg BASE_IMG=$GPU_IMG
+
+# GPU-GUI
+docker build . \
+--network='host' \
+-t mdl4eo/otbtf:$RELEASE-gpu-gui \
+--build-arg BASE_IMG=$GPU_IMG \
+--build-arg GUI=true
--
GitLab
From 80e64b86dedf6a0423bd968cbba8a69ad9941dd4 Mon Sep 17 00:00:00 2001
From: Cresson Remi <remi.cresson@irstea.fr>
Date: Tue, 4 Apr 2023 12:53:12 +0200
Subject: [PATCH 02/18] Docfix1 release4
---
doc/docker_use.md | 18 ++++++++++--------
1 file changed, 10 insertions(+), 8 deletions(-)
diff --git a/doc/docker_use.md b/doc/docker_use.md
index ba3c083d..47749325 100644
--- a/doc/docker_use.md
+++ b/doc/docker_use.md
@@ -25,12 +25,12 @@ Since OTBTF >= 3.2.1 you can find the latest docker images on
| Name | Os | TF | OTB | Description | Dev files | Compute capability |
|------------------------------------------------------------------------------------| ------------- |-------|-------| ---------------------- | --------- | ------------------ |
-| **mdl4eo/otbtf:4.0.0-cpu** | Ubuntu Focal | r2.12 | 8.1.0 | CPU, no optimization | no | 5.2,6.1,7.0,7.5,8.6|
-| **mdl4eo/otbtf:4.0.0-cpu-dev** | Ubuntu Focal | r2.12 | 8.1.0 | CPU, no optimization (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
-| **mdl4eo/otbtf:4.0.0-gpu** | Ubuntu Focal | r2.12 | 8.1.0 | GPU, no optimization | no | 5.2,6.1,7.0,7.5,8.6|
-| **mdl4eo/otbtf:4.0.0-gpu-dev** | Ubuntu Focal | r2.12 | 8.1.0 | GPU, no optimization (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
-| **gitlab.irstea.fr/remi.cresson/otbtf/container_registry/otbtf:4.0.0-gpu-opt** | Ubuntu Focal | r2.12 | 8.1.0 | GPU with opt. | no | 5.2,6.1,7.0,7.5,8.6|
-| **gitlab.irstea.fr/remi.cresson/otbtf/container_registry/otbtf:4.0.0-gpu-opt-dev** | Ubuntu Focal | r2.12 | 8.1.0 | GPU with opt. (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
+| **mdl4eo/otbtf:4.0.0-cpu** | Ubuntu Jammy | r2.12 | 8.1.0 | CPU, no optimization | no | 5.2,6.1,7.0,7.5,8.6|
+| **mdl4eo/otbtf:4.0.0-cpu-dev** | Ubuntu Jammy | r2.12 | 8.1.0 | CPU, no optimization (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
+| **mdl4eo/otbtf:4.0.0-gpu** | Ubuntu Jammy | r2.12 | 8.1.0 | GPU, no optimization | no | 5.2,6.1,7.0,7.5,8.6|
+| **mdl4eo/otbtf:4.0.0-gpu-dev** | Ubuntu Jammy | r2.12 | 8.1.0 | GPU, no optimization (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
+| **gitlab.irstea.fr/remi.cresson/otbtf/container_registry/otbtf:4.0.0-gpu-opt** | Ubuntu Jammy | r2.12 | 8.1.0 | GPU with opt. | no | 5.2,6.1,7.0,7.5,8.6|
+| **gitlab.irstea.fr/remi.cresson/otbtf/container_registry/otbtf:4.0.0-gpu-opt-dev** | Ubuntu Jammy | r2.12 | 8.1.0 | GPU with opt. (dev) | yes | 5.2,6.1,7.0,7.5,8.6|
The list of older releases is available [here](#older-images).
@@ -95,8 +95,10 @@ Troubleshooting:
Some users have reported to use OTBTF with GPU in windows 10 using WSL2.
How to install WSL2 with Cuda on windows 10:
- https://docs.nvidia.com/cuda/wsl-user-guide/index.html
- https://docs.docker.com/docker-for-windows/wsl/#gpu-support
+
+ - [WSL user guide](https://docs.nvidia.com/cuda/wsl-user-guide/index.html)
+ - [XSL GPU support](https://docs.docker.com/docker-for-windows/wsl/#gpu-support)
+
## Build your own images
--
GitLab
From cb1a48e1e257892b3584c55226a40a4253df762f Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 13:19:33 +0200
Subject: [PATCH 03/18] COMP: remove explicit numpy and proto versions
---
Dockerfile | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/Dockerfile b/Dockerfile
index f8b82f79..4d120292 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -26,8 +26,8 @@ RUN ln -s /usr/bin/python3 /usr/local/bin/python && ln -s /usr/bin/pip3 /usr/loc
# Upgrade pip
RUN pip install --no-cache-dir pip --upgrade
# NumPy version is conflicting with system's gdal dep and may require venv
-ARG NUMPY_SPEC="==1.22.*"
-ARG PROTO_SPEC="==3.20.*"
+ARG NUMPY_SPEC=""
+ARG PROTO_SPEC=""
RUN pip install --no-cache-dir -U wheel mock six future tqdm deprecated "numpy$NUMPY_SPEC" "protobuf$PROTO_SPEC" packaging requests \
&& pip install --no-cache-dir --no-deps keras_applications keras_preprocessing
--
GitLab
From f1d90e54f8879ffdf12fb0cfe236c9d3cbaea45c Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 14:22:29 +0200
Subject: [PATCH 04/18] ADD: test numpy, gdal and OTB together from python
---
test/numpy_test.py | 42 ++++++++++++++++++++++++++++++++++++++++++
1 file changed, 42 insertions(+)
create mode 100644 test/numpy_test.py
diff --git a/test/numpy_test.py b/test/numpy_test.py
new file mode 100644
index 00000000..55f0272c
--- /dev/null
+++ b/test/numpy_test.py
@@ -0,0 +1,42 @@
+#!/usr/bin/env python3
+# -*- coding: utf-8 -*-
+import pytest
+import unittest
+import otbApplication
+from osgeo import gdal
+from test_utils import resolve_paths
+
+FILENAME = resolve_paths('$DATADIR/fake_spot6.jp2')
+
+class NumpyTest(unittest.TestCase):
+
+ def test_gdal_as_nparr(self):
+ gdal_ds = gdal.Open(FILENAME)
+ band = gdal_ds.GetRasterBand(1)
+ arr = band.ReadAsArray()
+ self.assertTrue(arr.shape)
+
+
+ def test_otb_as_nparr(self):
+ app = otbApplication.Registry.CreateApplication('ExtractROI')
+ app.SetParameterString("in", FILENAME)
+ app.Execute()
+ arr = app.GetVectorImageAsNumpyArray('out')
+ self.assertTrue(arr.shape)
+
+ def test_gdal_and_otb_np(self):
+ gdal_ds = gdal.Open(FILENAME)
+ band = gdal_ds.GetRasterBand(1)
+ arr = band.ReadAsArray()
+ app = otbApplication.Registry.CreateApplication('ExtractROI')
+ app.SetImageFromNumpyArray('in', arr)
+ app.SetParameterInt('startx', 0)
+ app.SetParameterInt('starty', 0)
+ app.SetParameterInt('sizex', 10)
+ app.SetParameterInt('sizey', 10)
+ app.Execute()
+ arr2 = app.GetVectorImageAsNumpyArray('out')
+ self.assertTrue(arr2.shape)
+
+if __name__ == '__main__':
+ unittest.main()
--
GitLab
From e35fe71655ab9771d7812026b2145049ef79de26 Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 14:22:50 +0200
Subject: [PATCH 05/18] ADD: new tests for numpy
---
.gitlab-ci.yml | 5 +++++
1 file changed, 5 insertions(+)
diff --git a/.gitlab-ci.yml b/.gitlab-ci.yml
index 596e7ed1..af0e40a1 100644
--- a/.gitlab-ci.yml
+++ b/.gitlab-ci.yml
@@ -207,6 +207,11 @@ imports:
script:
- python -m pytest --junitxml=$ARTIFACT_TEST_DIR/report_imports.xml $OTBTF_SRC/test/imports_test.py
+numpy_gdal_otb:
+ extends: .applications_test_base
+ script:
+ - python -m pytest --junitxml=$ARTIFACT_TEST_DIR/report_numpy.xml $OTBTF_SRC/test/numpy_test.py
+
deploy_cpu-dev-testing:
stage: Update dev image
extends: .docker_build_base
--
GitLab
From 7817902e29d3b8a363d0d8df688bd3d8bb77bbc5 Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 14:23:17 +0200
Subject: [PATCH 06/18] ADD: test import all
---
test/imports_test.py | 11 +++++++++++
1 file changed, 11 insertions(+)
diff --git a/test/imports_test.py b/test/imports_test.py
index a89ab3dc..8d84a5cd 100644
--- a/test/imports_test.py
+++ b/test/imports_test.py
@@ -19,5 +19,16 @@ class ImportsTest(unittest.TestCase):
self.assertTrue(tensorflow.__version__)
+def test_import_all(self):
+ import otbApplication
+ self.assertTrue(otbApplication.Registry_GetAvailableApplications())
+ import tensorflow
+ self.assertTrue(tensorflow.__version__)
+ from osgeo import gdal
+ self.assertTrue(gdal.__version__)
+ import numpy
+ self.assertTrue(numpy.__version__)
+
+
if __name__ == '__main__':
unittest.main()
--
GitLab
From eab477a831952d64e146cfeeb9d6f10b407c4599 Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 14:23:46 +0200
Subject: [PATCH 07/18] COMP: set numpy version to 1.21.5
---
Dockerfile | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/Dockerfile b/Dockerfile
index 4d120292..b8a5cf81 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -26,7 +26,7 @@ RUN ln -s /usr/bin/python3 /usr/local/bin/python && ln -s /usr/bin/pip3 /usr/loc
# Upgrade pip
RUN pip install --no-cache-dir pip --upgrade
# NumPy version is conflicting with system's gdal dep and may require venv
-ARG NUMPY_SPEC=""
+ARG NUMPY_SPEC="==1.21.5"
ARG PROTO_SPEC=""
RUN pip install --no-cache-dir -U wheel mock six future tqdm deprecated "numpy$NUMPY_SPEC" "protobuf$PROTO_SPEC" packaging requests \
&& pip install --no-cache-dir --no-deps keras_applications keras_preprocessing
--
GitLab
From 365e5f4d534d7f5494dfa2f653ee28ca133d6d7a Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 15:12:19 +0200
Subject: [PATCH 08/18] COMP: remove install proto
---
Dockerfile | 5 ++---
1 file changed, 2 insertions(+), 3 deletions(-)
diff --git a/Dockerfile b/Dockerfile
index b8a5cf81..a612da25 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -26,9 +26,8 @@ RUN ln -s /usr/bin/python3 /usr/local/bin/python && ln -s /usr/bin/pip3 /usr/loc
# Upgrade pip
RUN pip install --no-cache-dir pip --upgrade
# NumPy version is conflicting with system's gdal dep and may require venv
-ARG NUMPY_SPEC="==1.21.5"
-ARG PROTO_SPEC=""
-RUN pip install --no-cache-dir -U wheel mock six future tqdm deprecated "numpy$NUMPY_SPEC" "protobuf$PROTO_SPEC" packaging requests \
+ARG NUMPY_SPEC="==1.22.*"
+RUN pip install --no-cache-dir -U wheel mock six future tqdm deprecated "numpy$NUMPY_SPEC" packaging requests \
&& pip install --no-cache-dir --no-deps keras_applications keras_preprocessing
# ----------------------------------------------------------------------------
--
GitLab
From fd539005b2b3860dbea6ccb29f7a1c34de4e12b1 Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 17:07:09 +0200
Subject: [PATCH 09/18] FIX: indent
---
test/imports_test.py | 18 +++++++++---------
1 file changed, 9 insertions(+), 9 deletions(-)
diff --git a/test/imports_test.py b/test/imports_test.py
index 8d84a5cd..e745ed5b 100644
--- a/test/imports_test.py
+++ b/test/imports_test.py
@@ -19,15 +19,15 @@ class ImportsTest(unittest.TestCase):
self.assertTrue(tensorflow.__version__)
-def test_import_all(self):
- import otbApplication
- self.assertTrue(otbApplication.Registry_GetAvailableApplications())
- import tensorflow
- self.assertTrue(tensorflow.__version__)
- from osgeo import gdal
- self.assertTrue(gdal.__version__)
- import numpy
- self.assertTrue(numpy.__version__)
+ def test_import_all(self):
+ import otbApplication
+ self.assertTrue(otbApplication.Registry_GetAvailableApplications())
+ import tensorflow
+ self.assertTrue(tensorflow.__version__)
+ from osgeo import gdal
+ self.assertTrue(gdal.__version__)
+ import numpy
+ self.assertTrue(numpy.__version__)
if __name__ == '__main__':
--
GitLab
From a8fe95c93545b8217a119fe312fae46ad19a59da Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 19:10:06 +0200
Subject: [PATCH 10/18] CI: add rasterio test
---
.gitlab-ci.yml | 6 ++++++
test/rio_test.py | 30 ++++++++++++++++++++++++++++++
2 files changed, 36 insertions(+)
create mode 100644 test/rio_test.py
diff --git a/.gitlab-ci.yml b/.gitlab-ci.yml
index af0e40a1..b3f138fb 100644
--- a/.gitlab-ci.yml
+++ b/.gitlab-ci.yml
@@ -212,6 +212,12 @@ numpy_gdal_otb:
script:
- python -m pytest --junitxml=$ARTIFACT_TEST_DIR/report_numpy.xml $OTBTF_SRC/test/numpy_test.py
+rio:
+ extends: .applications_test_base
+ script:
+ - sudo pip install rasterio
+ - python -c pytest --junitxml=$ARTIFACT_TEST_DIR/report_rio.xml $OTBTF_SRC/test/rio_test.py
+
deploy_cpu-dev-testing:
stage: Update dev image
extends: .docker_build_base
diff --git a/test/rio_test.py b/test/rio_test.py
new file mode 100644
index 00000000..972b521f
--- /dev/null
+++ b/test/rio_test.py
@@ -0,0 +1,30 @@
+#!/usr/bin/env python3
+# -*- coding: utf-8 -*-
+import pytest
+import unittest
+import rasterio
+import rasterio.features
+import rasterio.warp
+
+FILENAME = resolve_paths('$DATADIR/fake_spot6.jp2')
+
+class NumpyTest(unittest.TestCase):
+
+ def test_rio_read_md(self):
+ with rasterio.open(FILENAME) as dataset:
+ # Read the dataset's valid data mask as a ndarray.
+ mask = dataset.dataset_mask()
+
+ # Extract feature shapes and values from the array.
+ for geom, val in rasterio.features.shapes(
+ mask, transform=dataset.transform
+ ):
+ # Transform shapes from the dataset's own coordinate
+ # reference system to CRS84 (EPSG:4326).
+ geom = rasterio.warp.transform_geom(
+ dataset.crs, 'EPSG:4326', geom, precision=6
+ )
+ self.assertTrue(geom)
+
+if __name__ == '__main__':
+ unittest.main()
--
GitLab
From 72872e915981a645629b13be97a70a86d84df30c Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 19:37:13 +0200
Subject: [PATCH 11/18] CI: add rasterio test
---
.gitlab-ci.yml | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/.gitlab-ci.yml b/.gitlab-ci.yml
index b3f138fb..4c7c2dea 100644
--- a/.gitlab-ci.yml
+++ b/.gitlab-ci.yml
@@ -216,7 +216,7 @@ rio:
extends: .applications_test_base
script:
- sudo pip install rasterio
- - python -c pytest --junitxml=$ARTIFACT_TEST_DIR/report_rio.xml $OTBTF_SRC/test/rio_test.py
+ - python -m pytest --junitxml=$ARTIFACT_TEST_DIR/report_rio.xml $OTBTF_SRC/test/rio_test.py
deploy_cpu-dev-testing:
stage: Update dev image
--
GitLab
From fae013d38cdca3ad43e6b776df89d6dee5cc2d07 Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 20:07:20 +0200
Subject: [PATCH 12/18] CI: add rasterio test
---
test/rio_test.py | 1 +
1 file changed, 1 insertion(+)
diff --git a/test/rio_test.py b/test/rio_test.py
index 972b521f..fc6f8531 100644
--- a/test/rio_test.py
+++ b/test/rio_test.py
@@ -5,6 +5,7 @@ import unittest
import rasterio
import rasterio.features
import rasterio.warp
+from test_utils import resolve_paths
FILENAME = resolve_paths('$DATADIR/fake_spot6.jp2')
--
GitLab
From 3c92b32dcd6f3e34c30130fcd017ae56280da35c Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 20:11:33 +0200
Subject: [PATCH 13/18] DOC: update user path improvement in release notes
---
RELEASE_NOTES.txt | 1 +
1 file changed, 1 insertion(+)
diff --git a/RELEASE_NOTES.txt b/RELEASE_NOTES.txt
index 7cf3b01d..e0ac4a4e 100644
--- a/RELEASE_NOTES.txt
+++ b/RELEASE_NOTES.txt
@@ -12,6 +12,7 @@ Version 4.0.0alpha (4 apr 2023)
* Tensorflow version: 2.12.0
* Fixed Tensorflow error "Cannot register 2 metrics with the same name" + new test
* Faster CI build thanks to bazel remote cache
+* /home/otbuser/.local/bin added to user path
Version 3.4.0 (22 mar 2023)
----------------------------------------------------------------
--
GitLab
From 08eefb42af33418d04df5a1d4a24a2250cbe9f1f Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 20:48:10 +0200
Subject: [PATCH 14/18] TEST: add import_all() test
---
test/rio_test.py | 13 +++++++++++++
1 file changed, 13 insertions(+)
diff --git a/test/rio_test.py b/test/rio_test.py
index fc6f8531..a391c4a8 100644
--- a/test/rio_test.py
+++ b/test/rio_test.py
@@ -27,5 +27,18 @@ class NumpyTest(unittest.TestCase):
)
self.assertTrue(geom)
+
+ def test_import_all(self):
+ import otbApplication
+ self.assertTrue(otbApplication.Registry_GetAvailableApplications())
+ import tensorflow
+ self.assertTrue(tensorflow.__version__)
+ from osgeo import gdal
+ self.assertTrue(gdal.__version__)
+ import numpy
+ self.assertTrue(numpy.__version__)
+ self.test_rio_read_md()
+
+
if __name__ == '__main__':
unittest.main()
--
GitLab
From b5acab7a0796123c2e38fc9235b89fb100136583 Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 21:14:08 +0200
Subject: [PATCH 15/18] DOC: quick fix
---
doc/index.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/doc/index.md b/doc/index.md
index 4bb28c76..d7357c79 100644
--- a/doc/index.md
+++ b/doc/index.md
@@ -50,7 +50,7 @@ set of _patches images_ and delivering samples as `tf.dataset` that can be
used in your favorite TensorFlow pipelines, or convert your patches into
TFRecords. The `otbtf.TFRecords` enables you train networks from TFRecords
files, which is quite suited for distributed training. Read more in the
-[tutorial for keras](otbtf/examples/tensorflow_v2x/fcnn/README.md).
+[tutorial for keras](#api_tutorial.html).
## Examples
--
GitLab
From 8e2dd5605cf867d23accda3de3c7e4cba33d9a80 Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 21:26:22 +0200
Subject: [PATCH 16/18] TEST: add otbtf import in import_all()
---
test/rio_test.py | 2 ++
1 file changed, 2 insertions(+)
diff --git a/test/rio_test.py b/test/rio_test.py
index a391c4a8..c6a0f2f1 100644
--- a/test/rio_test.py
+++ b/test/rio_test.py
@@ -38,6 +38,8 @@ class NumpyTest(unittest.TestCase):
import numpy
self.assertTrue(numpy.__version__)
self.test_rio_read_md()
+ import otbtf
+ self.assertTrue(otbtf.__version__)
if __name__ == '__main__':
--
GitLab
From 05e2d31ab0501782e614911e06e69b2c5573c844 Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 21:34:26 +0200
Subject: [PATCH 17/18] DOC: quick fix
---
doc/index.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/doc/index.md b/doc/index.md
index d7357c79..976b739a 100644
--- a/doc/index.md
+++ b/doc/index.md
@@ -50,7 +50,7 @@ set of _patches images_ and delivering samples as `tf.dataset` that can be
used in your favorite TensorFlow pipelines, or convert your patches into
TFRecords. The `otbtf.TFRecords` enables you train networks from TFRecords
files, which is quite suited for distributed training. Read more in the
-[tutorial for keras](#api_tutorial.html).
+[tutorial for keras](api_tutorial.html).
## Examples
--
GitLab
From c930619eaf4d4bc4f9785566a6b6067b0424f3fe Mon Sep 17 00:00:00 2001
From: Remi Cresson <remi.cresson@inrae.fr>
Date: Tue, 4 Apr 2023 21:43:20 +0200
Subject: [PATCH 18/18] DOC: quick fix
---
doc/api_distributed.md | 2 +-
doc/deprecated.md | 2 +-
doc/docker_build.md | 2 +-
doc/docker_use.md | 2 +-
doc/index.md | 2 +-
5 files changed, 5 insertions(+), 5 deletions(-)
diff --git a/doc/api_distributed.md b/doc/api_distributed.md
index 1478022c..077704e0 100644
--- a/doc/api_distributed.md
+++ b/doc/api_distributed.md
@@ -24,7 +24,7 @@ on all GPUs.
## Python code
We can start from the codebase of the fully convolutional model example
-described in the OTBTF [Python API tutorial](#api_tutorial.html).
+described in the OTBTF [Python API tutorial](api_tutorial.html).
### Dataset
diff --git a/doc/deprecated.md b/doc/deprecated.md
index c0477962..3f76c1db 100644
--- a/doc/deprecated.md
+++ b/doc/deprecated.md
@@ -35,4 +35,4 @@ training, etc. is done using the so-called `tensorflow.Strategy`
!!! Note
- Read our [tutorial](#api_tutorial.html) to know more on working with Keras!
\ No newline at end of file
+ Read our [tutorial](api_tutorial.html) to know more on working with Keras!
\ No newline at end of file
diff --git a/doc/docker_build.md b/doc/docker_build.md
index c7a3c1e9..debc1ea8 100644
--- a/doc/docker_build.md
+++ b/doc/docker_build.md
@@ -49,7 +49,7 @@ be a different branch of OTB, bazel cache will help you to rebuild everything
except TF, even if the docker cache was purged (after `docker
[system|builder] prune`).
In order to recycle the cache, bazel config and TF git tag should be exactly
-the same, any change in [build-env-tf.sh](build-env-tf.sh) and `--build-arg`
+the same, any change in *tools/docker/build-env-tf.sh* and `--build-arg`
(if related to bazel env, cuda, mkl, xla...) may result in a fresh new build.
Start a cache daemon - here with max 20GB but 10GB should be enough to save 2
diff --git a/doc/docker_use.md b/doc/docker_use.md
index 47749325..ebbab5a4 100644
--- a/doc/docker_use.md
+++ b/doc/docker_use.md
@@ -104,7 +104,7 @@ Troubleshooting:
If you want to use optimization flags, change GPUs compute capability, etc.
you can build your own docker image using the provided dockerfile.
-See the [docker build documentation](#docker_build.html).
+See the [docker build documentation](docker_build.html).
## Older images
diff --git a/doc/index.md b/doc/index.md
index 976b739a..f96bb5cb 100644
--- a/doc/index.md
+++ b/doc/index.md
@@ -16,7 +16,7 @@
This remote module of the [Orfeo ToolBox](https://www.orfeo-toolbox.org)
-provides a generic, multi-purpose deep learning framework, targeting remote
+provides a generic, multipurpose deep learning framework, targeting remote
sensing images processing. It contains a set of new process objects for OTB
that internally invoke [Tensorflow](https://www.tensorflow.org/), and new [OTB
applications](#otb-applications) to perform deep learning with real-world
--
GitLab